This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data pre-processing: This involves making certain that the data is correctly formatted and cleansed to facilitate analysis. Data manipulation This stage, often referred to as datawrangling, consists of transforming raw data into a more usable format for analysis.
Because it can swiftly and effectively handle data structures, carry out calculations, and apply algorithms, Python is the perfect language for handling data. Datawrangling requires that you first clean the data. It entails searching the data for missing values and assigning or imputed values to them.
They require strong programming skills, expertise in machine learning algorithms, and knowledge of data processing. Machine Learning Engineer Machine learning engineers are responsible for designing and building machine learning systems.
the most sophisticated iteration of its primary text-to-image algorithm. Additionally, it may be found on Amazon SageMaker JumpStart, an ML hub with access to ML solutions, models, and algorithms. fine-tuning the model to custom data is easier than ever. Stability AI unveiled SDXL 1.0, With Stable Diffusion XL 1.0,
It could explain how these distributions are used in different machine learning algorithms and why understanding them is crucial for data scientists. 32 datasets to uplift your skills in data science Data Science Dojo has created an archive of 32 data sets for you to use to practice and improve your skills as a data scientist.
Machine Learning for Data Science by Carlos Guestrin This is an intermediate-level course that teaches you how to use machine learning for data science tasks. The course covers topics such as datawrangling, feature engineering, and model selection.
Machine learning practitioners tend to do more than just create algorithms all day. First, there’s a need for preparing the data, aka data engineering basics. As the chart shows, two major themes emerged.
You’ll take a deep dive into DataGPT’s technology stack, detailing its methodology for efficient data processing and its measures to ensure accuracy and consistency. You’ll cover the integration of LLMs with advanced algorithms in DataGPT, with an emphasis on their collaborative roles in data analysis.
It could explain how these distributions are used in different machine learning algorithms and why understanding them is crucial for data scientists. This blog might discuss various statistical distributions (such as normal, binomial, and Poisson) and their applications in machine learning.
Recently, we spoke with Pedro Domingos, Professor of computer science at the University of Washington, AI researcher, and author of “The Master Algorithm” book. In the interview, we talked about the quest for the “ultimate machine learning algorithm.” How close are we to a “Holy Grail,” aka the Ultimate Machine Learning Algorithm?
In ML, there are a variety of algorithms that can help solve problems. In graduate school, a course in AI will usually have a quick review of the core ML concepts (covered in a previous course) and then cover searching algorithms, game theory, Bayesian Networks, Markov Decision Processes (MDP), reinforcement learning, and more.
students must use a particular algorithm type or must make inferences quickly). DrivenData Competitions to use: Any competition with open data Skill options: Flexible to fit a huge range of data science or statistical skills Assessment: Grades can be based on model performance, or a submitted report or presentation.
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on data analysis and interpretation to extract meaningful insights.
Here are some simplified usage patterns where we feel Dataiku can help: Data Preparation Dataiku offers robust data preparation capabilities that streamline the entire process of transforming raw data into actionable insights.
Just as a writer needs to know core skills like sentence structure, grammar, and so on, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and so on. This will lead to algorithm development for any machine or deep learning processes.
Mathematical Foundations In addition to programming concepts, a solid grasp of basic mathematical principles is essential for success in Data Science. Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data.
Business users will also perform data analytics within business intelligence (BI) platforms for insight into current market conditions or probable decision-making outcomes. Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists.
ODSC Bootcamp Primer: DataWrangling with SQL Course January 25th @ 2PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in AI.
SQL Primer Thursday, September 7th, 2023, 2 PM EST This SQL coding course teaches students the basics of Structured Query Language, which is a standard programming language used for managing and manipulating data and an essential tool in learning AI. You will learn how to design and write SQL code to solve real-world problems.
R, with its robust statistical capabilities, remains a popular choice for statistical analysis and data visualization. Datawrangling and preprocessing Data seldom comes in a pristine form; it often requires cleaning, transformation, and preprocessing before analysis.
Build Classification and Regression Models with Spark on AWS Suman Debnath | Principal Developer Advocate, Data Engineering | Amazon Web Services This immersive session will cover optimizing PySpark and best practices for Spark MLlib. Finally, you’ll explore how to handle missing values and training and validating your models using PySpark.
Our virtual partners include: Microsoft Azure | Qwak | Tangent Works | MIT | Pachyderm | Boston College | ArangoDB | DataGPT | Upsolver On-Demand Training You’ll also have access to our on-demand Primer Courses that cover a wide range of data science topics essential for success in the field. So, don’t delay.
There is a position called Data Analyst whose work is to analyze the historical data, and from that, they will derive some KPI s (Key Performance Indicators) for making any further calls. For Data Analysis you can focus on such topics as Feature Engineering , DataWrangling , and EDA which is also known as Exploratory Data Analysis.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learning algorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learning algorithms.
Data Profiling refers to the process of analysing and examining data for creating valuable summaries of it. The process of data profiling helps in understanding the structure, content and interrelationships of data. What is the difference between data profiling and datawrangling?
DataWrangling The process of cleaning and preparing raw data for analysis—often referred to as “ datawrangling “—is time-consuming and requires attention to detail. Ensuring data quality is vital for producing reliable results. Is Data Science Harder Than Other Fields?
Programming/coding skills are to data scientists as plumbing tools are to professional plumbers. Without the ability to utilize data, create models, visualizations, algorithms, or anything else, you’re left without a story. One of the superpowers of data science is the ability to create predictive models.
Steps to Become a Data Scientist If you want to pursue a Data Science course after 10th, you need to ensure that you are aware the steps that can help you become a Data Scientist. For instance, calculus can help with optimising ML algorithms. Using Python libraries like pandas can help you better in the process.
They possess a deep understanding of AI technologies, algorithms, and frameworks and have the ability to translate business requirements into robust AI systems. AI Engineers focus primarily on implementing and deploying AI models and algorithms, working closely with data scientists and machine learning experts.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. DataWrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
By transitioning from computer science to data science, you can tap into a broader range of job opportunities and potentially increase your earning potential. Leveraging existing skills: Computer science provides a strong foundation in programming, algorithms, and problem-solving, which are highly valuable in data science.
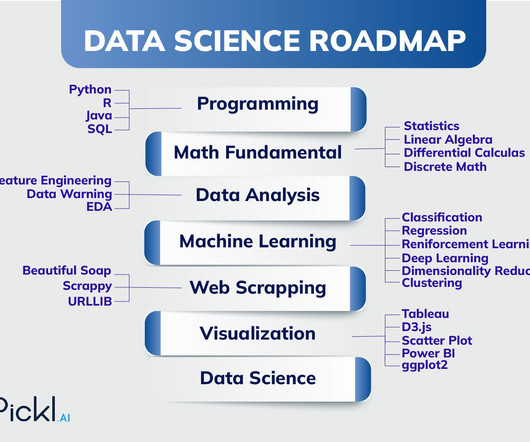
The Data Science Roadmap: Navigating Your Path to Success Step 1: Learning About Programming or Software Engineering A strong foundation in programming languages like Python , R, or Java is essential. Step 2: Acquiring Statistical Proficiency A Data Scientist’s toolkit is incomplete without a solid understanding of statistics.
Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decision trees, and support vector machines. To obtain practical expertise, run the algorithms on datasets. After that, move towards unsupervised learning methods like clustering and dimensionality reduction.
This new feature enables you to run large datawrangling operations efficiently, within Azure ML, by leveraging Azure Synapse Analytics to get access to an Apache Spark pool. Another recent announcement, also still in public preview, is the integration of Spark with Azure ML.
Summary View Analytics Chart DataWrangling Dashboard Parameter Summary View Reference lines for Mean & Midian Now you can see the mean and the median values as reference lines on top of the histogram charts for numerical columns. I’m super excited to announce Exploratory v6.2! ???
Basic Data Science Terms Familiarity with key concepts also fosters confidence when presenting findings to stakeholders. Below is an alphabetical list of essential Data Science terms that every Data Analyst should know. DataWrangling: The cleaning, transforming, and structuring of raw data into a format suitable for analysis.
The constant compromises are frustrating because, without clear visualization and smooth workflows, even the smartest algorithms and simulations can’t reach their full potential. Its algorithms handle all the heavy lifting for me, automatically scoring nodes based on their context in the network.
Students should learn about datawrangling and the importance of data quality. Statistical Analysis Introducing statistical methods and techniques for analysing data, including hypothesis testing, regression analysis, and descriptive statistics. Students should learn how to apply machine learning models to Big Data.
When you import data to Exploratory it used to save the data in a binary format called RDS on the local hard disk. This is the data at the source step (the first step in the right hand side) before any datawrangling. you can easily switch between similar algorithms while preserving the column selection.
. · Machine Learning: R provides numerous packages for machine learning tasks, making it a popular choice for data scientists. Packages like caret, random Forest, glmnet, and xgboost offer implementations of various machine learning algorithms, including classification, regression, clustering, and dimensionality reduction.
Predictive Analytics Projects: Predictive analytics involves using historical data to predict future events or outcomes. Techniques like regression analysis, time series forecasting, and machine learning algorithms are used to predict customer behavior, sales trends, equipment failure, and more.
Data Analyst to Data Scientist: Level-up Your Data Science Career The ever-evolving field of Data Science is witnessing an explosion of data volume and complexity. This can significantly reduce development time and democratize Machine Learning for Data Analysts looking to transition into architecture.
Also today’s volume, variety, and velocity of data, only intensify the data-sharing issues. With Snowflake’s data marketplace, this data can be sourced in just a few clicks from various data providers without any data-wrangling efforts.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content