This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. Retrieve images stored in S3 bucket response = s3.list_objects_v2(Bucket=BUCKET_NAME)
Learn how the synergy of AI and Machine Learning algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Machine learning algorithms Machine learning is a subset of AI. You can download Pegasus using pip with simple instructions.
Learn how the synergy of AI and ML algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Paraphrasing tools in AI and ML algorithms Machine learning is a subset of AI. You can download Pegasus using pip with simple instructions.
Learn how the synergy of AI and ML algorithms in paraphrasing tools is redefining communication through intelligent algorithms that enhance language expression. Paraphrasing tools in AI and ML algorithms Machine learning is a subset of AI. You can download Pegasus using pip with simple instructions.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. Looking for the source code to this post?
In this blog post, we’ll explore how to deploy LLMs such as Llama-2 using Amazon Sagemaker JumpStart and keep our LLMs up to date with relevant information through Retrieval Augmented Generation (RAG) using the Pinecone vector database in order to prevent AI Hallucination. Sign up for a free-tier Pinecone Vector Database.
For time-series forecasting use cases, SageMaker Canvas uses autoML to train six algorithms on your historical time-series dataset and combines them using a stacking ensemble method to create an optimal forecasting model. To download a copy of this dataset, visit. Choose Save.
app downloads, DeepSeek is growing in popularity with each passing hour. Whether by scanning medical images or analyzing market trends, each engagement fine-tunes its algorithms, one building on another, getting more and more powerful. AI is being discussed in various sectors like healthcare, banking, education, manufacturing, etc.
Traditionally, RAG systems were text-centric, retrieving information from large text databases to provide relevant context for language models. First, it enables you to include both image and text features in a single database and therefore reduces complexity. jpg") or doc.endswith(".png")) b64encode(fIn.read()).decode("utf-8")
Database name : Enter dev. Database user : Enter awsuser. You can now view the predictions and download them as CSV. Enter the following details to establish your Amazon Redshift connection : Cluster Identifier : Copy the ProducerClusterName from the CloudFormation nested stack outputs. Connection Name : Enter MyRedshiftCluster.
Collecting the dataset The use case for the text classification is based on the Consumer complaint database which is a collection of complaints about consumer financial products and services. So, the ensemble model performs better than individual algorithms and the ensemble workflow is very easy to use in the Watson NLP library.
Download the free, unabridged version here. Below we outline three of our favourites: From XGBoost to NGBoost NGBoost is a machine learning algorithm that goes beyond the already powerful XGBoost by predicting an interval , instead of a single point estimate. Download the free, unabridged version here.
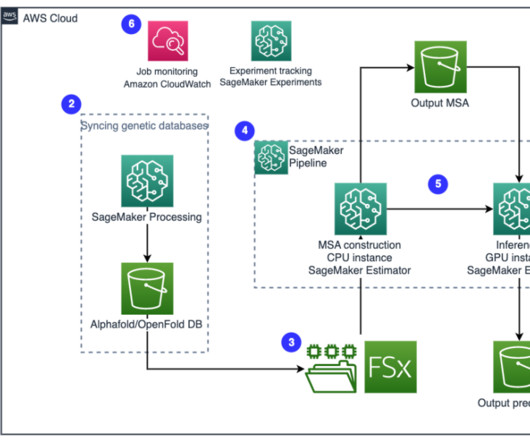
Folding algorithms like AlphaFold2 , ESMFold , OpenFold , and RoseTTAFold can be used to quickly build accurate models of protein structures. Genetic databases – A genetic database is one or more sets of genetic data stored together with software to enable users to retrieve genetic data.
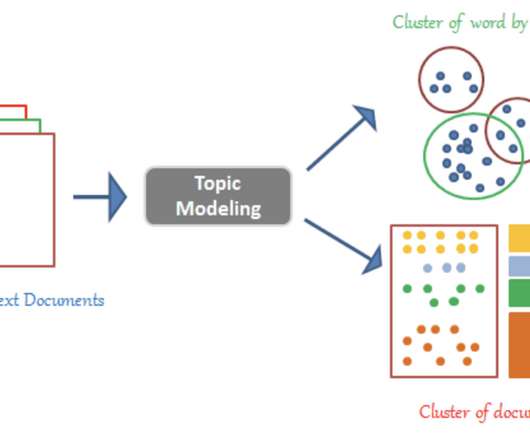
Topic Modeling In this blog, we walk you through the popular Open Source Latent Dirichlet Allocation (LDA) Topic Modeling from conventional algorithms and Watson NLP Topic Modeling. An algorithm is carried out in LDA by carefully following the stages listed below. Once you have collected this dataset. Collecting dataset 4.
“ Vector Databases are completely different from your cloud data warehouse.” – You might have heard that statement if you are involved in creating vector embeddings for your RAG-based Gen AI applications. in a 2D space based on the machine learning algorithm used.
Image Retrieval with IBM watsonx.data and Milvus (Vector) Database : A Deep Dive into Similarity Search What is Milvus? Milvus is an open-source vector database specifically designed for efficient similarity search across large datasets. You can follow command below to download the data. . Building the Image Search Pipeline 1.
SageMaker JumpStart is a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. models with SageMaker JumpStart as follows: import requests import base64 def url_to_base64(image_url): # Download the image response = requests.get(image_url) if response.status_code !=
Prerequisites For this post, the administrator needs the following prerequisites: A Snowflake user with administrator permission to create a Snowflake virtual warehouse, user, and role, and grant access to this user to create a database. The following steps show how to prepare and load the dataset into the Snowflake database.
Jump Right To The Downloads Section What Is Locality Sensitive Hashing (LSH)? SimHash: LSH for Vector Databases SimHash is a specific type of Locality Sensitive Hashing (LSH) designed to efficiently detect near-duplicate documents and perform similarity searches in large-scale vector databases.
MMPose is a member of the OpenMMLab Project and contains a rich set of algorithms for 2D multi-person human pose estimation, 2D hand pose estimation, 2D face landmark detection, and 133 keypoint whole-body human pose estimations. If the gloss is not available in the GenASL database, the logic falls back to fingerspelling each alphabet letter.
Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deep learning models tend to develop a bias toward the data distribution on which they have been trained. Note that this entails a simple way multi-class classification problem for a database with personnel (here, persons or classes).
When working on real-world machine learning (ML) use cases, finding the best algorithm/model is not the end of your responsibilities. To ensure security and JSON/pickle benefits, you can save your model to a dedicated database. Next, you will see how you can save an ML model in a database.
DSPy DSPy is a framework for algorithmically optimizing Language Model prompts instead of manually prompting. Open a second terminal, and to download and start the extractors, use: $ indexify-extractor download tensorlake/minilm-l6 $ indexify-extractor download tensorlake/chunk-extractor $ indexify-extractor join-server After […]
There are various techniques of preference alignment, including proximal policy optimization (PPO), direct preference optimization (DPO), odds ratio policy optimization (ORPO), group relative policy optimization (GRPO), and other algorithms, that can be used in this process.
The software is easy to use and provides the ability to download different file formats. It works with a number of different databases. With RapidMiner, companies can use a huge range of algorithm and data functions without writing code manually. Another key benefit is that it allows companies to create data visualizations!
We applied Otter-Knowledge to Drug Discovery, and demonstrated that knowledge-enhanced learned representation enriches protein sequence and SMILES drug databases with a large multi-modal Knowledge Graph fused from different sources. Bindingdb: a web-accessible database of experimentally determined protein–ligand binding affinities.
It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. join(batch_text_arr) s3.put_object(
For metrics that may not correlate with any other variables, we can attempt to characterize the behavior over time using forecasting algorithms. One state-of-the-art forecasting algorithm is Prophet, developed by Meta. You can download our synthetic data from here. Understanding Anomaly Detection What are anomalies in CRM data?
DSPy DSPy is a framework for algorithmically optimizing Language Model prompts instead of manually prompting. Open a second terminal, and to download and start the extractors, use: $ indexify-extractor download tensorlake/minilm-l6 $ indexify-extractor download tensorlake/chunk-extractor $ indexify-extractor join-server After […]
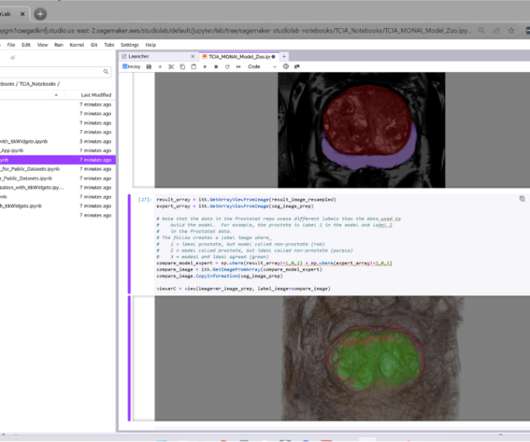
The following example illustrates Studio Lab running a Jupyter notebook that downloads TCIA prostate MRI data, segments it using MONAI, and displays the results using itkWidgets. The first SageMaker notebook shows how to download DICOM images from TCIA and visualize those images using the cinematic volume rendering capabilities of itkWidgets.
There’s nothing to download. How to use AutoDraw You just begin drawing your best depiction of a pizza, home, puppy, or birthday cake, and the algorithms attempt to figure out what you’re attempting to create. There is nothing to be downloaded. . “AutoDraw is a new kind of drawing tool. Nothing to pay for.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
In November 2022, we announced that AWS customers can generate images from text with Stable Diffusion models in Amazon SageMaker JumpStart , a machine learning (ML) hub offering models, algorithms, and solutions. When it comes to building the essential vector database, AWS provides a multitude of options through their native services.
That’s because AI algorithms are trained on data. And it’s safe to say that most AI algorithms are trained on datasets that are significantly older. Worse yet, the AI’s bias would likely find its way into the system’s database and follow the students from one class to the next. You turned left or right.
Data scientists are the bridge between programming and algorithmic thinking. They are responsible for managing database systems, scaling data architecture to multiple servers, and writing complex queries to sift through the data. Data Scientists. A data scientist can run a project from end-to-end. Data Engineers.
Improving Operations and Infrastructure Taipy The inspiration for this open-source software for Python developers was the frustration felt by those who were trying, and struggling, to bring AI algorithms to end-users. Making Data Observable Bigeye The quality of the data powering your machine learning algorithms should not be a mystery.
Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data. Linear algebra is vital for understanding Machine Learning algorithms and data manipulation. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Your video may be exported in high definition and then shared on social media or downloaded to your mobile device. You can export your video in HD quality and share it directly to social media or download it to your device. It also selects relevant images or footage from its database or online sources.
For enterprises, the value-add of applications built on top of large language models is realized when domain knowledge from internal databases and documents is incorporated to enhance a model’s ability to answer questions, generate content, and any other intended use cases.
Summary: Hash function are essential algorithms that convert input data into fixed-size outputs. A hash function is a mathematical algorithm that transforms input data into a fixed-size string of characters. For example, when downloading files, hash values can verify that the file remains unchanged. What is a Hash Function?
Neo4j is one of the most popular graph database choices among our customers. The Neo4j data platform As the world’s most popular graph database, Neo4j offers unmatched tools and integrations to support graph application developers. This will replicate a full Neo4j database and let us test our Cypher querying.
TikTok Music offers users access to a sizable database of songs that can be added to personal libraries, mimicking the functionality of existing music streaming services. You may download, stream, share, and buy music with the app. Here is how to use TikTok Music: Download TikTok Music from App Store or Google Play Store.
Amazon Kendra is a highly accurate and intelligent search service that enables users to search unstructured and structured data using natural language processing (NLP) and advanced search algorithms. Access permission to the AWS Glue databases and tables are managed by AWS Lake Formation. amazonaws.com docker build -t. Choose Select.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content