This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
The good news is that a number of Hadoop solutions can be invaluable for people that are trying to get the most bang for their buck. How does Hadoop technology help with key couponing and frugal living? Fortunately, Hadoop and other big data technologies are playing an important role in addressing all of these challenges.
They work at the intersection of various technical domains, requiring a blend of skills to handle data processing, algorithm development, system design, and implementation. Machine Learning Algorithms Recent improvements in machine learning algorithms have significantly enhanced their efficiency and accuracy.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is Apache Hadoop? What is Apache Spark?
The biggest breakthroughs in machine learning have only emerged over the last five years, as new advances in Hadoop and other big data technology make artificial intelligence algorithms more practical. Users’ disorganized libraries of thousands of untagged photos were transformed into searchable databases overnight.”.
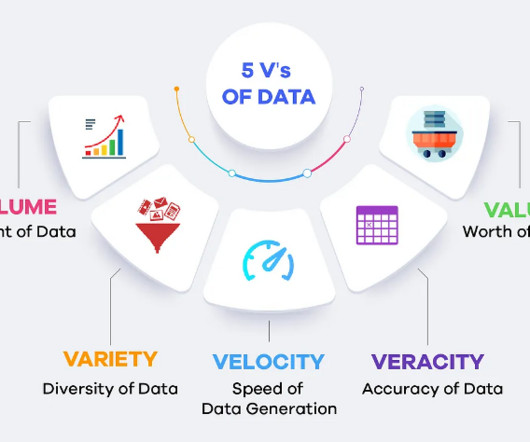
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Different algorithms and techniques are employed to achieve eventual consistency. XML, JSON), and unstructured data (e.g.,
Unlike the old days where data was readily stored and available from a single database and data scientists only needed to learn a few programming languages, data has grown with technology. This will enable you to leverage the right algorithms to create good, well structured, and performing software. Understand the Databases.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
Also, it extracts historical weather data from various databases. Hadoop has also helped considerably with weather forecasting. Instead, it uses AI-powered algorithms to process weather data and generates real-time weather forecasts. from various sources. Real-Time Weather Insights.
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics. Yes, many people still need a data lake (for their relevant data, not all enterprise data).
MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machine learning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas. Setup the Database access and Network access.
Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists. And you should have experience working with big data platforms such as Hadoop or Apache Spark. Those who work in the field of data science are known as data scientists.
Data scientists are the bridge between programming and algorithmic thinking. They are responsible for managing database systems, scaling data architecture to multiple servers, and writing complex queries to sift through the data. Hadoop, SQL, Python, R, Excel are some of the tools you’ll need to be familiar using.
GPUs (graphics processing units) and TPUs (tensor processing units) are specifically designed to handle complex mathematical computations central to AI algorithms, offering significant speedups compared with traditional CPUs. Additionally, using in-memory databases and caching mechanisms minimizes latency and improves data access speeds.
They are able to utilize Hadoop-based data mining tools to improve their market research capabilities and develop better products. There are detailed databases of business names that you can use for inspiration and avoid trademark issues. These algorithms are getting better all the time.
Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data. Linear algebra is vital for understanding Machine Learning algorithms and data manipulation. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms.
Familiarise yourself with essential tools like Hadoop and Spark. Variety Data comes in multiple forms, from highly organised databases to messy, unstructured formats like videos and social media text. What are the Main Components of Hadoop? What is the Role of a NameNode in Hadoop ? What is a DataNode in Hadoop?
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). It is built on the Hadoop Distributed File System (HDFS) and utilises MapReduce for data processing.
Concepts such as linear algebra, calculus, probability, and statistical theory are the backbone of many data science algorithms and techniques. Coding skills are essential for tasks such as data cleaning, analysis, visualization, and implementing machine learning algorithms. Specializing can make you stand out from other candidates.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). Key Takeaways Big Data originates from diverse sources, including IoT and social media.
Processing frameworks like Hadoop enable efficient data analysis across clusters. This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). Key Takeaways Big Data originates from diverse sources, including IoT and social media.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
Machine Learning Engineer Machine Learning Engineers develop algorithms and models that enable machines to learn from data. Strong understanding of data preprocessing and algorithm development. They explore new algorithms and techniques to improve machine learning models. Strong knowledge of AI algorithms and architectures.
This is an organized set of data that can be processed, stored, and retrieved from a database in an orderly format using a simplified search engine algorithm. For example, you can organize an employee table in a database in a structured manner to capture the employee’s details, job positions, salary, etc. Structured. Velocity.
In addition to traditional structured data (like databases), there is a wealth of unstructured and semi-structured data (such as emails, videos, images, and social media posts). This section will highlight key tools such as Apache Hadoop, Spark, and various NoSQL databases that facilitate efficient Big Data management.
data visualization tools, machine learning algorithms, and statistical models to uncover valuable information hidden within data. Finance: In the financial sector, data science is used for fraud detection, risk assessment, algorithmic trading, and personalized financial advice.
These skills encompass proficiency in programming languages, data manipulation, and applying Machine Learning Algorithms , all essential for extracting meaningful insights and making data-driven decisions. SQL is indispensable for database management and querying. It forms the basis of predictive modelling and risk assessment.
The BigBasket team was running open source, in-house ML algorithms for computer vision object recognition to power AI-enabled checkout at their Fresho (physical) stores. We used FSx for Lustre and Amazon Relational Database Service (Amazon RDS) for fast parallel data access. Split data into train, validation, and test sets.
Advances in big data technology like Hadoop, Hive, Spark and Machine Learning algorithms have made it possible to interpret and utilize this variety of data effectively. Structured Structured data is quantitative and highly organized, typically managed within relational databases.
With a few taps on a mobile device, riders request a ride; then, Uber’s algorithms work to match them with the nearest available driver and calculate the optimal price. They stood up a file-based data lake alongside their analytical database. Uber has made the Presto query engine connect to real-time databases.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Below, we explore some of the most widely used algorithms in ML.
Further, Data Scientists are also responsible for using machine learning algorithms to identify patterns and trends, make predictions, and solve business problems. Furthermore, they must be highly efficient in programming languages like Python or R and have data visualization tools and database expertise.
In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Sound knowledge of relational databases or NoSQL databases like Cassandra. Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. What is Polybase?
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
Knowledge of Core Data Engineering Concepts Ensure one possess a strong foundation in core data engineering concepts, which include data structures, algorithms, database management systems, data modeling , data warehousing , ETL (Extract, Transform, Load) processes, and distributed computing frameworks (e.g., Hadoop, Spark).
Unlike structured data, unstructured data doesn’t fit neatly into predefined models or databases, making it harder to analyse using traditional methods. While sensor data is typically numerical and has a well-defined format, such as timestamps and data points, it only fits the standard tabular structure of databases.
They encompass all the origins from which data is collected, including: Internal Data Sources: These include databases, enterprise resource planning (ERP) systems, customer relationship management (CRM) systems, and flat files within an organization. databases), semi-structured (e.g., Data can be structured (e.g.,
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Crawlers then store this information in a database for indexing. Advanced crawling algorithms allow them to adapt to new content and changes in website structures. Precision: Advanced algorithms ensure they accurately categorise and store data. Structured data can be easily imported into databases or analytical tools.
Computer Science A computer science background equips you with programming expertise, knowledge of algorithms and data structures, and the ability to design and implement software solutions – all valuable assets for manipulating and analyzing data. Databases and SQL Data doesn’t exist in a vacuum.
The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and Big Data technologies. Issues such as algorithmic bias, data privacy, and transparency are becoming critical topics of discussion within the industry.
From an algorithmic perspective, Learning To Rank (LeToR) and Elastic Search are some of the most popular algorithms used to build a Seach system. We can collect and use user-product historical interaction data to train recommendation system algorithms. are some examples. Let’s understand this with an example.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content