This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. Vector databases are revolutionizing healthcare data management. That’s where vector databases come in handy—they are made on purpose to handle this special kind of data.
Or think about a real-time facial recognition system that must match a face in a crowd to a database of thousands. These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate NearestNeighbor (ANN) search algorithms come into play.
Start by estimating the memory required to support your disk-optimized k-NN index (with the default 32 times compression rate) using the following formula: Required memory (bytes) = 1.1 Disk mode uses the HNSW algorithm to build indexes, so m is one of the algorithm parameters, and it defaults to 16.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights.
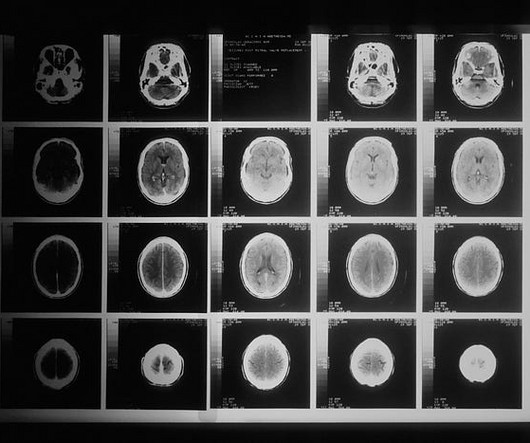
Ensemble models can be generated using a single algorithm with numerous variations, known as a homogeneous ensemble, or by using different techniques, known as a heterogeneous ensemble [3]. 4] Dataset The dataset comes from Kaggle [5], which contains a database of 3206 brain MRI images. Stacking Model Representation Diagram. [4]
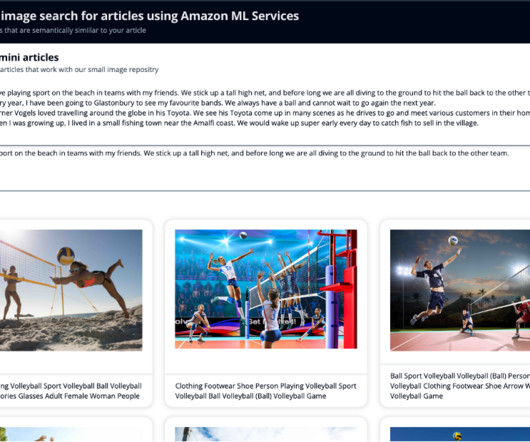
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. Display results : Display the top K similar results to the user. b64encode(resized_image).decode('utf-8')
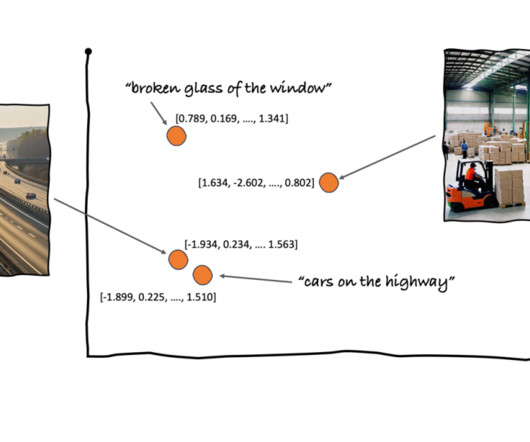
Vector Databases 101: A Beginners Guide to Vector Search and Indexing Photo by Google DeepMind on Unsplash Introduction Alright, folks! The secret sauce behind all of this is vector search and vector databases, helping power similarity-based recommendations and retrieval! Traditional databases? They tap out.
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
Previously, OfferUps search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. The search microservice processes the query requests and retrieves relevant listings from Elasticsearch using keyword search (BM25 as a ranking algorithm).
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Refinement: The candidate set is then refined by computing the actual distances between the query point and the candidates to find the approximate nearestneighbors. Random Projection The first step in the algorithm is to sample random vectors in the same -dimensional space as input vector.
You then use Exact k-NN with scoring script so that you can search by two fields: celebrity names and the vector that captured the semantic information of the article. You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. What is Unsupervised Machine Learning?
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module.
We stored the embeddings in a vector database and then used the Large Language-and-Vision Assistant (LLaVA 1.5-7b) 7b) model to generate text responses to user questions based on the most similar slide retrieved from the vector database. OpenSearch Serverless is an on-demand serverless configuration for Amazon OpenSearch Service.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). Conversely, a smaller K leads to faster search times and lower costs, but may lower result quality.
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. The selection of the number of neighbors and feature selection is a daunting task.
Key steps involve problem definition, data preparation, and algorithm selection. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data. Types of Machine Learning Machine Learning algorithms can be categorised based on how they learn and the data type they use.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping. Data Cleaning: Raw data often contains errors, inconsistencies, and missing values.
Lesson 1: Mitigating data sparsity problems within ML classification algorithms What are the most popular algorithms used to solve a multi-class classification problem? The selection of the correct loss function plays a pivotal role in the success of the algorithm. Let’s take a look at some of them.
A great example of traditional image features is SIFT (Scale Invariant Feature Transform) which is a quite involved algorithm that finds key points in images: Source: [link] By leveraging image embeddings, all the weight lifting of feature extraction is done by a neural network.
Often, it requires you to co-design the algorithm and also the system set. If they’re necessary, how can we create a new algorithm to accommodate it? On one hand, there’s a data management community trying to understand data transformation and computing some functions over exponentially many databases for decades.
Often, it requires you to co-design the algorithm and also the system set. If they’re necessary, how can we create a new algorithm to accommodate it? On one hand, there’s a data management community trying to understand data transformation and computing some functions over exponentially many databases for decades.
#LuxuryBrand #TimelessElegance #ExclusiveCollection Retrieve and analyze the top three relevant posts The next step involves using the generated image and text to search for the top three similar historical posts from a vector database. The following code snippet shows the implementation of this step.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science? Let us see some examples.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content