This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Gradient boosting decisiontrees (GBDT) are at the forefront of machine learning, combining the simplicity of decisiontrees with the power of ensemble techniques. Understanding the mechanics behind GBDT requires diving into decisiontrees, ensemble learning methods, and the intricacies of optimization strategies.
In this post, I will show how to develop, deploy, and use a decisiontree model in a Db2 database. Using examples from the dataset, we’ll build a classification model with decisiontreealgorithm. I extract the hour part of these values to create, hopefully, better features for the learning algorithm.
Through various statistical methods and machine learning algorithms, predictive modeling transforms complex datasets into understandable forecasts. Definition and overview of predictive modeling At its core, predictive modeling involves creating a model using historical data that can predict future events.
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. Data mining During the data mining phase, various techniques and algorithms are employed to discover patterns and correlations. It’s an integral part of data analytics and plays a crucial role in data science.
Base model training Next, each bootstrap sample undergoes independent training with base models, which can be decisiontrees or other machine learning algorithms. Definition and purpose The Bagging Regressor is an application of the bagging method designed for regression analysis.
They influence the choice of algorithms and the structure of models. This includes converting categorical data into numerical values, which is often necessary for algorithms to work effectively. Definition and types of categorical data Categorical data can be classified into two primary types: nominal and ordinal.
These two techniques, while related, have distinct definitions and applications. Definition of extrapolation Extrapolation involves estimating unknown values that lie outside the range of your known data points. Decisiontrees: Estimation methods help build these algorithms, enhancing their predictive power.
Support Vector Machines (SVM) are a type of supervised learning algorithm designed for classification and regression tasks. This decision boundary is crucial for achieving accurate predictions and effectively dividing data points into categories. What are Support Vector Machines (SVM)?
For centuries before the existence of computers, humans have imagined intelligent machines that were capable of making decisions autonomously. At the early era of Artificial Intelligence, programmers tried to teach machines from the definition of logical rules that the machine itself could extend during the execution of the program.
First bringing together conflicting literature on what XAI is and some important definitions and distinctions. The current state of explainability … explained Any research on explainability will show that there is little by way of a concrete definition. Interpretability — Explaining the meaning of a model/model decisions to humans.
In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. However, typical algorithms do not produce a binary result but instead, provide a relevancy score for which labels are the most appropriate. Thus tail labels have an inflated score in the metric.
This one is definitely one of the most practical and inspiring. So you definitely can trust his expertise in Machine Learning and Deep Learning. So you definitely can trust his expertise in Machine Learning and Deep Learning. Lesson #5: What ML algorithms to use Nowadays, there are a lot of different ML techniques.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
The Last Dinner, Leonard Da Vinci, 1494–1498 Data structures used in algorithms As mentioned in the previous article, the right data structures are required for the performance of an algorithm to operate. An incorrect structure could prove to be detrimental or unsustainable to an algorithm. They are numbers arranged linearly.
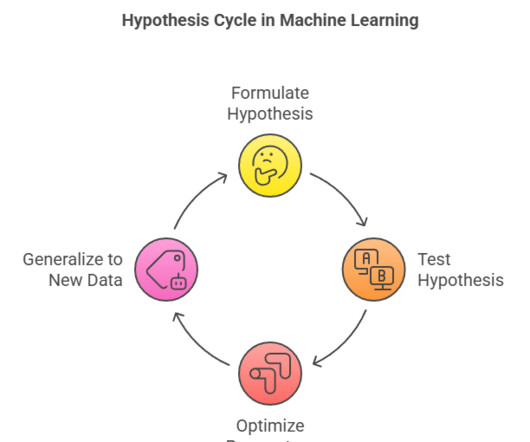
It guides algorithms in testing assumptions, optimizing parameters, and minimizing errors. hypothesis form the foundation for diverse applications, from predictive analytics and recommendation engines to autonomous systems, enabling accurate, data-driven decision-making and improved model performance.
This article will cover the basics of DecisionTrees and XGBoost, and demonstrate how to implement the latter for classifying celestial objects in the night sky as either a Galaxy, Star, or Quasar. Photo by Nathan Anderson on Unsplash Brief Intro to ML Algorithms A decisiontree is a widely used algorithm in machine learning.
Key steps involve problem definition, data preparation, and algorithm selection. Basics of Machine Learning Machine Learning is a subset of Artificial Intelligence (AI) that allows systems to learn from data, improve from experience, and make predictions or decisions without being explicitly programmed.
From deterministic software to AI Earlier examples of “thinking machines” included cybernetics (feedback loops like autopilots) and expert systems (decisiontrees for doctors). A lot : Some algorithmic advances have lowered the cost of AI by multiple orders of magnitude. When the result is unexpected, that’s called a bug.
The reasoning behind that is simple; whatever we have learned till now, be it adaptive boosting, decisiontrees, or gradient boosting, have very distinct statistical foundations which require you to get your hands dirty with the math behind them. , you already know that our approach in this series is math-heavy instead of code-heavy.
Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. AI algorithms may produce inaccurate or biased results without clean, relevant, and representative data.
Data Science extracts insights, while Machine Learning focuses on self-learning algorithms. Key takeaways Data Science lays the groundwork for Machine Learning, providing curated datasets for ML algorithms to learn and make predictions. Emphasises programming skills, understanding of algorithms, and expertise in Data Analysis.
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. This one is a widely used ML algorithm that is mostly focused on capturing complex patterns within tabular datasets.
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. Definition of AI AI refers to developing computer systems that can perform tasks that require human intelligence.
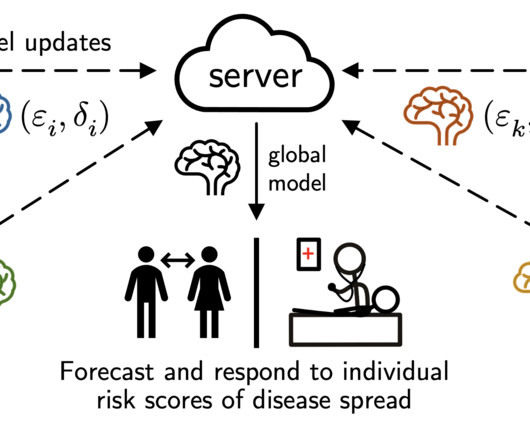
In short, this says that the (k)-th data silo may set its own ((varepsilon_k, delta_k)) example-level DP target for any learning algorithm with respect to its local dataset. Privacy definition: There are a small number of clients, but each holds many data subjects, and client-level DP isn’t suitable.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. Decisiontrees are more prone to overfitting.
We used AutoGluon to explore several classic ML algorithms. The best baseline was achieved with a weighted ensemble of gradient boosted decisiontree models. The ML model takes in the historical sequence of machine events and other metadata and predicts whether a machine will encounter a failure in a 6-hour future time window.
These statistics underscore the significant impact that Data Science and AI are having on our future, reshaping how we analyse data, make decisions, and interact with technology. For example, PayPal uses Machine Learning algorithms to analyse transaction patterns and identify anomalies that may indicate fraudulent activity.
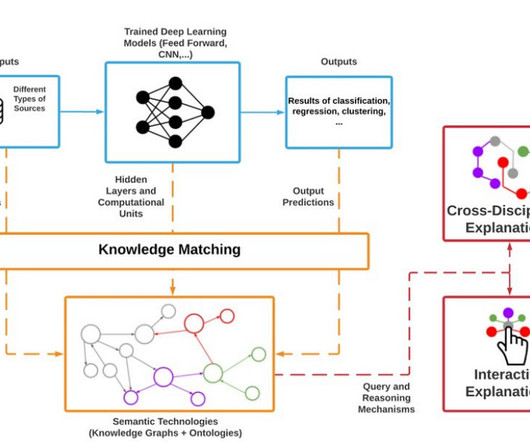
Algorithmic Accountability: Explainability ensures accountability in machine learning and AI systems. It allows developers, auditors, and regulators to examine the decision-making processes of the models, identify potential biases or errors, and assess their compliance with ethical guidelines and legal requirements.
Developing predictive models using Machine Learning Algorithms will be a crucial part of your role, enabling you to forecast trends and outcomes. This phase entails meticulously selecting and training algorithms to ensure optimal performance. You will collect and clean data from multiple sources, ensuring it is suitable for analysis.
These reference guides condense complex concepts, algorithms, and commands into easy-to-understand formats. Expertise in mathematics and statistical fields is essential for deciding algorithms, drawing conclusions, and making predictions. Let’s delve into the world of cheat sheets and understand their importance.
We went through the core essentials required to understand XGBoost, namely decisiontrees and ensemble learners. AdaBoos t A formal definition of AdaBoost (Adaptive Boosting) is “the combination of the output of weak learners into a weighted sum, representing the final output.” Table 1: The Dataset.
Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and support vector machines. To obtain practical expertise, run the algorithms on datasets. It includes regression, classification, clustering, decisiontrees, and more.
In this article, we will explore the definitions, differences, and impacts of bias and variance, along with strategies to strike a balance between them to create optimal models that outperform the competition. K-Nearest Neighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance.
Support Vector Machine Support Vector Machine ( SVM ) is a supervised learning algorithm used for classification and regression analysis. Machine learning algorithms rely on mathematical functions called “kernels” to make predictions based on input data.
During this step, AutoMLV2 will automatically pre-process your data, select algorithms, train multiple models, and tune them to find the best solution. The following figure is a decisiontree to help you decide what type of endpoint to use.
It's in contrast to a really broad and undefined definition of the word ”outcome” Paul, one of the design managers at Intercom, was struggling to differentiate between customer outcomes and business impact. Taking this intuition further, we might consider the TextRank algorithm.
Personally, I think there are definitely horizons in math, biology, and physics that we may never reach… but maybe AI can change that. This was the primary inspirations to Eureqa’s algorithm. This search for mathematical formulas makes Eureqa different from other machine learning algorithms. What to Know More about Eureqa?
Machine learning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machine learning algorithms? Outputs: The results generated by the algorithms, whether classifications, predictions, or recommendations based on the patterns identified.
Supervised learning is a powerful approach within the expansive field of machine learning that relies on labeled data to teach algorithms how to make predictions. Supervised learning refers to a subset of machine learning techniques where algorithms learn from labeled datasets.
Definition and purpose The primary purpose of ensemble modeling is to combine multiple predictive models to maximize accuracy and minimize error rates. By addressing the limitations of individual models, this methodology offers a broader perspective on data interpretation and decision-making.
The decision boundary would be a line that separates these two groups, determining whether a new point falls into the cat or dog category based on its features. Definition of decision boundary The definition of a decision boundary is rooted in its functionality within classification algorithms.
Definition and purpose Neural networks are designed to mimic human brain functions using layers of interconnected nodes, processing input data through complex mathematical computations. Symbolic approaches, such as decisiontrees, offer clarity and reasoning but may lack the speed and capacity of neural networks.
They provide a foundational understanding and a reference point from which data scientists can gauge the performance of advanced algorithms. Decisiontrees: Provide interpretable predictions based on logical rules. By understanding their performance, data scientists can design and refine complex algorithms effectively.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content