This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
Support Vector Machines (SVM) are a type of supervisedlearningalgorithm designed for classification and regression tasks. Definition of SVM SVMs operate on the principle of finding the hyperplane that maximizes the margin between different classes. What are Support Vector Machines (SVM)?
At the early era of Artificial Intelligence, programmers tried to teach machines from the definition of logical rules that the machine itself could extend during the execution of the program. Although there are many types of learning, Michalski defined the two most common types of learning: SupervisedLearning.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learningalgorithms. You might be using machine learningalgorithms from everything you see on OTT or everything you shop online.
Prodigy features many of the ideas and solutions for data collection and supervisedlearning outlined in this blog post. It’s a cloud-free, downloadable tool and comes with powerful active learning models. Sometimes the unsupervised algorithm will happen to produce the output you want, but other times it won’t.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. Natural language processing (NLP): ML algorithms can be used to understand and interpret human language, enabling organizations to automate tasks such as customer support and document processing.
Your data scientists develop models on this component, which stores all parameters, feature definitions, artifacts, and other experiment-related information they care about for every experiment they run. Building a Machine Learning platform (Lemonade). Design Patterns in Machine Learning for MLOps (by Pier Paolo Ippolito).
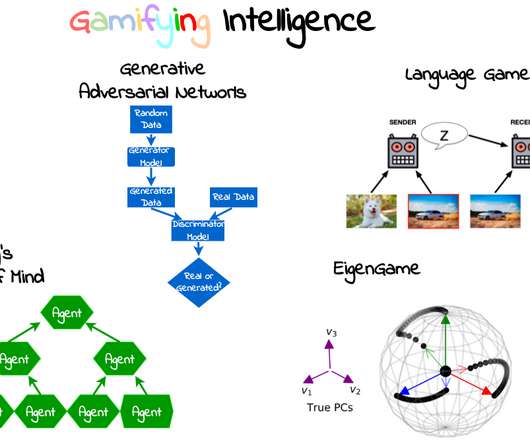
Then, we will look at three recent research projects that gamified existing algorithms by converting them from single-agent to multi-agent: ?️♀️ Our internal agents are playing games until they learn how to cooperate and trick us into believing we are an individual. Gamification There are many definitions for what a game is.
Key Takeaways Machine Learning Models are vital for modern technology applications. Types include supervised, unsupervised, and reinforcement learning. Key steps involve problem definition, data preparation, and algorithm selection. Ethical considerations are crucial in developing fair Machine Learning solutions.
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Classification. Anomaly Detection.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. Natural language processing (NLP): ML algorithms can be used to understand and interpret human language, enabling organizations to automate tasks such as customer support and document processing.
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance.
We previously explored a single job optimization, visualized the outcomes for SageMaker built-in algorithm, and learned about the impact of particular hyperparameter values. In this post, we run multiple HPO jobs with a custom training algorithm and different HPO strategies such as Bayesian optimization and random search.
Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. This section delves into its foundational definitions, types, and critical concepts crucial for comprehending its vast landscape. AI algorithms may produce inaccurate or biased results without clean, relevant, and representative data.
Why machine learning systems need annotated examples Most AI systems today rely on supervisedlearning : you provide labelled input and output pairs, and get a program that can perform analogous computation for new data. By definition, you can’t directly control what the process returns.
Reinforcement learning is a machine learning training method based on rewarding desired behaviours and punishing undesired ones. Here is a brief description of the algorithm: OpenAI collected prompts submitted by the users to the earlier versions of the model.
All the previously, recently, and currently collected data is used as input for time series forecasting where future trends, seasonal changes, irregularities, and such are elaborated based on complex math-driven algorithms. And with machine learning, time series forecasting becomes faster, more precise, and more efficient in the long run.
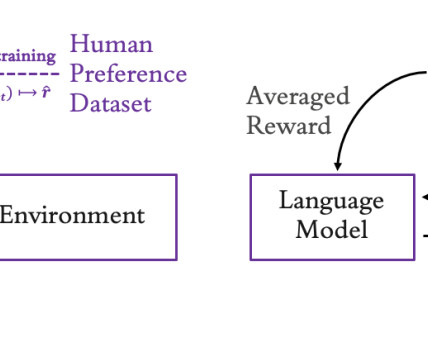
The model was fine-tuned to reduce false, harmful, or biased output using a combination of supervisedlearning in conjunction to what OpenAI calls Reinforcement Learning with Human Feedback (RLHF), where humans rank potential outputs and a reinforcement learningalgorithm rewards the model for generating outputs like those that rank highly.
They use self-supervisedlearningalgorithms to perform a variety of natural language processing (NLP) tasks in ways that are similar to how humans use language (see Figure 1). Large language models (LLMs) have taken the field of AI by storm.
Key Terms and Definitions To fully grasp the concepts of dimensionality reduction, it’s essential to understand the key terms and definitions associated with this field. This efficiency is especially valuable when working with large datasets or complex algorithms.
It may seem simple linear regression is neglected in the machine learning world of today. It helps to understand higher and more complex algorithms. So, it is important to master this algorithm. In this tutorial, you will learn about the concepts behind simple linear regression. We will also show how to code it in Python.
MicroMasters Program in Statistics and Data Science MIT – edX 1 year 2 months (INR 1,11,739) This program integrates Data Science, Statistics, and Machine Learning basics. The curriculum includes Machine LearningAlgorithms and prepares students for roles like Data Scientist, Data Analyst, System Analyst, and Intelligence Analyst.
And many of the practical challenges around neural nets—and machine learning in general—center on acquiring or preparing the necessary training data. In many cases (“supervisedlearning”) one wants to get explicit examples of inputs and the outputs one is expecting from them. First comes the embedding module.
Currently, most models are trained via supervisedlearning, which relies on well-annotated data from humans to create training examples. Data annotation is especially important when considering the amount of unstructured data that exists in the form of text, images, video, and audio.
In the beginning, we looked at the binary classification problem of how do you find label errors in data and how do you learn? How do you train machine learningalgorithms generally for any data set? Then we generalized that for the entire field of supervisedlearning. And for any model for binary classification?
In the beginning, we looked at the binary classification problem of how do you find label errors in data and how do you learn? How do you train machine learningalgorithms generally for any data set? Then we generalized that for the entire field of supervisedlearning. And for any model for binary classification?
Over the next several weeks, we will discuss novel developments in research topics ranging from responsible AI to algorithms and computer systems to science, health and robotics. of high definition video. Let’s get started! The Pix2Seq framework for object detection.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: Support Vector Machine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearningalgorithm used for classification and regression analysis.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervisedlearning such as linear regression , logistic regression, decision trees, and support vector machines.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. It’s not just about accuracy, and it’s definitely not just about one test set. We’re definitely getting there. DK: Absolutely, I think that’s a perfect metaphor. DK: For sure.
As humans, we learn a lot of general stuff through self-supervisedlearning by just experiencing the world. It’s not just about accuracy, and it’s definitely not just about one test set. We’re definitely getting there. DK: Absolutely, I think that’s a perfect metaphor. DK: For sure.
But Pattern’s algorithms are pretty crappy, and NLTK carries tremendous baggage around in its implementation because of its massive framework, and double-duty as a teaching tool. So today I wrote a 200 line version of my recommended algorithm for TextBlob. Averaged Perceptron POS tagging is a “supervisedlearning problem”.
But I definitely think there’s still much more to come. If you’ve been using the neural network model in Stanford CoreNLP , you’re using an algorithm that’s almost identical in design, but not in detail. Joint models and semi-supervisedlearning have always been the “motherhood and apple pie” of natural language understanding research.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. Text labeling has enabled all sorts of frameworks and strategies in machine learning.
Unsupervised learning has shown a big potential in large language models but high-quality labelled data remains the gold standard for AI systems to be accurate and aligned with human language and understanding. Text labeling has enabled all sorts of frameworks and strategies in machine learning.
So what that means is that when we write feature definitions, instead of writing them in Python, we write the feature for the online prediction process. So we write a SQL definition. And then of course, if you do supervisedlearning, we need labels for the model. Another challenge is an algorithm challenge.
So what that means is that when we write feature definitions, instead of writing them in Python, we write the feature for the online prediction process. So we write a SQL definition. And then of course, if you do supervisedlearning, we need labels for the model. Another challenge is an algorithm challenge.
So what that means is that when we write feature definitions, instead of writing them in Python, we write the feature for the online prediction process. So we write a SQL definition. And then of course, if you do supervisedlearning, we need labels for the model. Another challenge is an algorithm challenge.
The performance of computer vision algorithms is greatly influenced by the quality of the images used for the training and validation. Image labeling and annotation are the foundational steps in accurately labeling the image data and developing machine learning (ML) models for the computer vision task.
Supervisedlearning can help tune LLMs by using examples demonstrating some desired behaviors, which is called supervised fine-tuning (SFT). 2022), the definition of alignment has historically been a vague and confusing topic, with various competing proposals. In other words, these models are not aligned with their users.
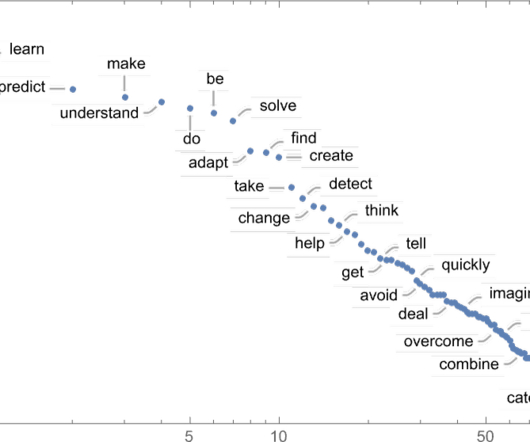
Algorithms play a crucial role in our everyday lives, often operating behind the scenes to enhance our experiences in the digital world. From the way search engines deliver results to how personal assistants predict our needs, algorithms are the foundational elements that shape modern technology. What is an algorithm?
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights. The data is raw and unstructured.
The False Positive Rate (FPR) plays a pivotal role in the evaluation of machine learning models, particularly in binary classification scenarios. In this article, we will explore the FPR, its significance, and how it impacts the efficacy of machine learning models. This flexibility is particularly beneficial in dynamic environments.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

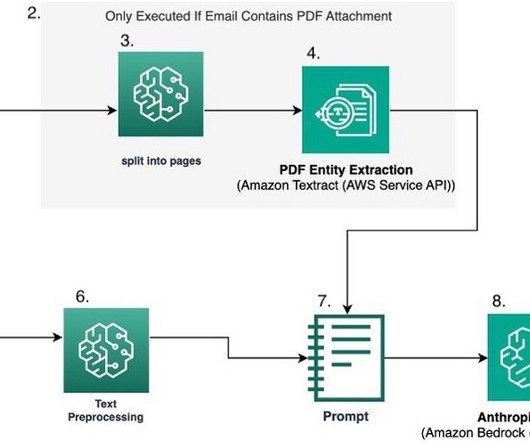





























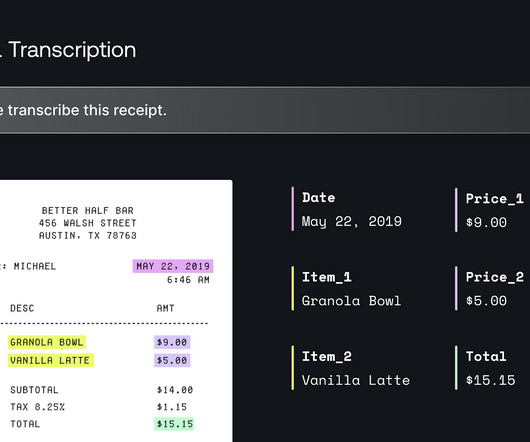
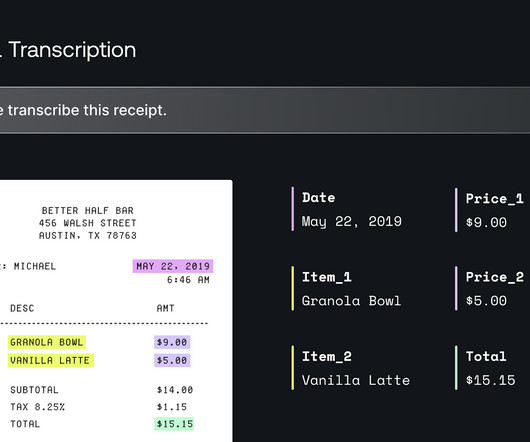



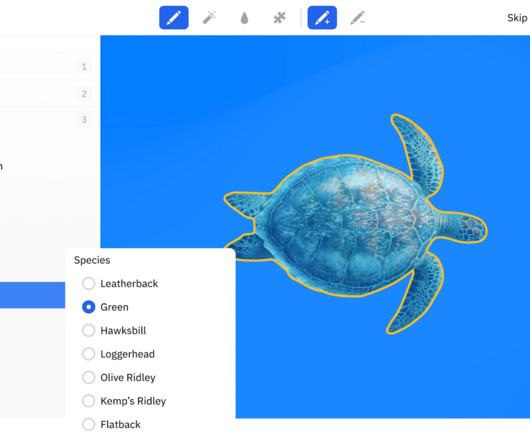









Let's personalize your content