This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachines (SVM) are a cornerstone of machine learning, providing powerful techniques for classifying and predicting outcomes in complex datasets. What are SupportVectorMachines (SVM)? They define the way data is transformed and can greatly affect the performance of the algorithm.
Definition and importance Convex optimization revolves around functions and constraints that exhibit specific properties. The importance of this discipline becomes clear when considering the vast range of optimization issues faced in industries like finance, engineering, and machine learning.
Instead of relying on predefined, rigid definitions, our approach follows the principle of understanding a set. Its important to note that the learned definitions might differ from common expectations. Instead of relying solely on compressed definitions, we provide the model with a quasi-definition by extension.
For centuries before the existence of computers, humans have imagined intelligent machines that were capable of making decisions autonomously. At the early era of Artificial Intelligence, programmers tried to teach machines from the definition of logical rules that the machine itself could extend during the execution of the program.
In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations. However, typical algorithms do not produce a binary result but instead, provide a relevancy score for which labels are the most appropriate. Thus tail labels have an inflated score in the metric.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
In this article, we will delve into the concepts of generative and discriminative models, exploring their definitions, working principles, and applications. Examples of Generative Models Generative models encompass various algorithms that capture patterns in data to generate realistic new examples.
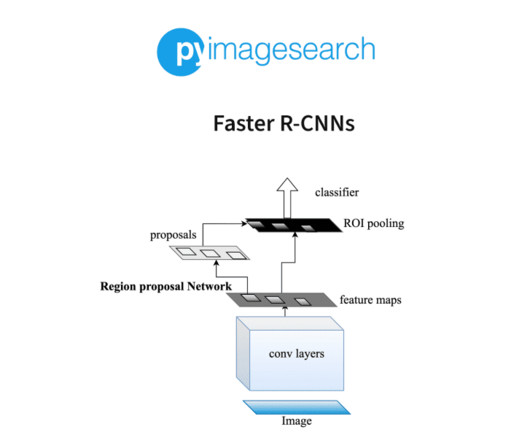
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
Machine Learning by Stanford University (Andrew Ng) This legendary program, taught by the AI pioneer Andrew Ng , is often considered the definitive introduction to machine learning. This professional certificate provides a holistic approach to machine learning, combining theoretical knowledge with practical skills.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Machine learning algorithms rely on mathematical functions called “kernels” to make predictions based on input data.
Summary: In the tech landscape of 2024, the distinctions between Data Science and Machine Learning are pivotal. Data Science extracts insights, while Machine Learning focuses on self-learning algorithms. Markets for each field are booming, offering diverse job roles, especially in Machine Learning for Data Analytics.
The thought of machine learning and AI will definitely pop into your mind when the conversation is about emerging technologies. Today, we see tools and systems with machine-learning capabilities in almost every industry. It dramatically shortens computing times for complex algorithms. Isn’t it so?
Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Understanding the Basics of AI Artificial Intelligence (AI) represents the capability of machines to imitate intelligent human behaviour. Python offers a robust ecosystem for implementing various supervised learning algorithms.
Key Takeaways Machine Learning Models are vital for modern technology applications. Key steps involve problem definition, data preparation, and algorithm selection. Ethical considerations are crucial in developing fair Machine Learning solutions. Let’s break down the key components and types of Machine Learning.
An interdisciplinary field that constitutes various scientific processes, algorithms, tools, and machine learning techniques working to help find common patterns and gather sensible insights from the given raw input data using statistical and mathematical analysis is called Data Science. What is Data Science?
Understanding these concepts is paramount for any data scientist, machine learning engineer, or researcher striving to build robust and accurate models. K-Nearest Neighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decision trees, and supportvectormachines.
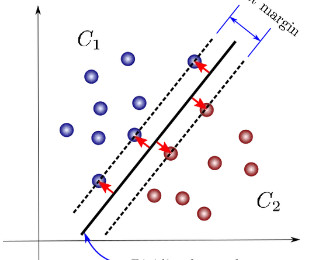
SupportVectorMachines, or SVM, is a machine learning algorithm that, in its original form, is utilized for binary classification. MARGIN Before delving into the model, it is essential to understand the concept of margin, which comprises the dividing hyperplane together with the supportvector lines.
Machine learning algorithms represent a transformative leap in technology, fundamentally changing how data is analyzed and utilized across various industries. What are machine learning algorithms? Regression: Focuses on predicting continuous values, such as forecasting sales or estimating property prices.
Definition of decision boundary The definition of a decision boundary is rooted in its functionality within classification algorithms. It can manifest in various forms, such as linear or non-linear, depending on the underlying data distribution and the algorithm employed.
Hyperplanes are pivotal fixtures in the landscape of machine learning, acting as crucial decision boundaries that help classify data into distinct categories. Their role extends beyond mere classification; they also facilitate regression and clustering, demonstrating their versatility across various algorithms. What is a hyperplane?
Supervised learning is a powerful approach within the expansive field of machine learning that relies on labeled data to teach algorithms how to make predictions. Supervised learning refers to a subset of machine learning techniques where algorithms learn from labeled datasets.
Let us now look at the key differences starting with their definitions and the type of data they use. Definition of Supervised Learning and Unsupervised Learning Supervised learning is a process where an ML model is trained using labeled data. After training, the machine learning model can predict outcomes for new, unseen data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content