This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
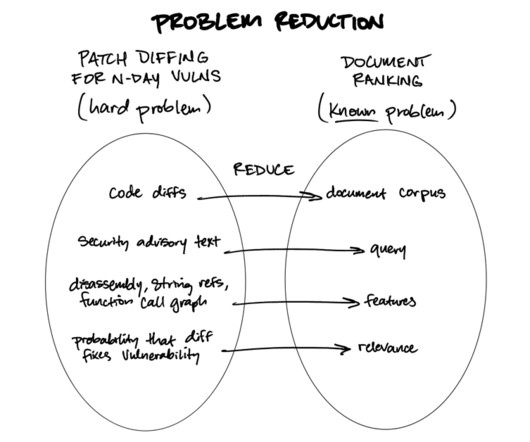
There are two claims I’d like to make: LLMs can be used effectively1 for listwise document ranking. Some complex problems can (surprisingly) be solved by transforming them into document ranking problems.
Introduction DocVQA (Document Visual Question Answering) is a research field in computer vision and natural language processing that focuses on developing algorithms to answer questions related to the content of a document, like a scanned document or an image of a text document.
Introduction Document information extraction involves using computer algorithms to extract structured data (like employee name, address, designation, phone number, etc.) from unstructured or semi-structured documents, such as reports, emails, and web pages.
Introduction Intelligent document processing (IDP) is a technology that uses artificial intelligence (AI) and machine learning (ML) to automatically extract information from unstructured documents such as invoices, receipts, and forms.
Rapid Automatic Keyword Extraction(RAKE) is a Domain-Independent keyword extraction algorithm in Natural Language Processing. It is an Individual document-oriented dynamic Information retrieval method. The post Rapid Keyword Extraction (RAKE) Algorithm in Natural Language Processing appeared first on Analytics Vidhya.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
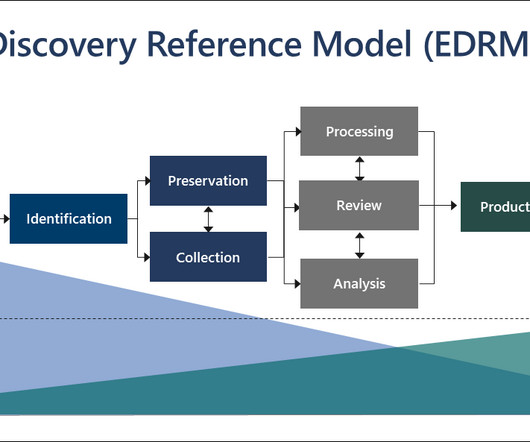
Anyhow, with the exponential growth of digital data, manual document review can be a challenging task. Hence, AI has the potential to revolutionize the eDiscovery process, particularly in document review, by automating tasks, increasing efficiency, and reducing costs. The model can review and categorize new documents automatically.
For years, businesses, governments, and researchers have struggled with a persistent problem: How to extract usable data from Portable Document Format (PDF) files. Read full article Comments
The complexity of SuperGLUE tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques. The complexity of HumanEval tasks drives researchers to develop more sophisticated models, leading to advanced algorithms and techniques.
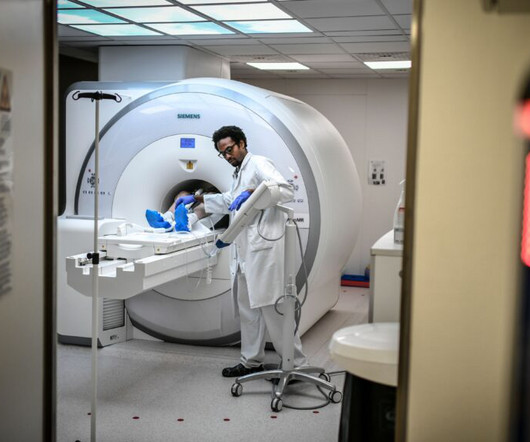
Medical imaging already leads the way in the clinical application of artificial intelligence: Algorithms that help to analyze CT scans, MRIs, and X-rays account for more than three-quarters of AI-based devices authorized by the Food and Drug Administration.
Overview In NLP, tf-idf is an important measure and is used by algorithms like cosine similarity to find documents that are similar to a given search query. This article was published as a part of the Data Science Blogathon. Here in this blog, we will try to break tf-idf and see how sklearn’s TfidfVectorizer calculates […].
Just like people, Algorithmic biases can occur sometimes. AI algorithms are used to make decisions about everything from who gets a loan to what ads we see online. However, AI algorithms can be biased, which can have a negative impact on people’s lives. Thinking why? Well, think of AI as making those characters.
This process is typically facilitated by document loaders, which provide a “load” method for accessing and loading documents into the memory. This involves splitting lengthy documents into smaller chunks that are compatible with the model and produce accurate and clear results.
The model then uses a clustering algorithm to group the sentences into clusters. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks. It works by first embedding the sentences in the text using BERT.
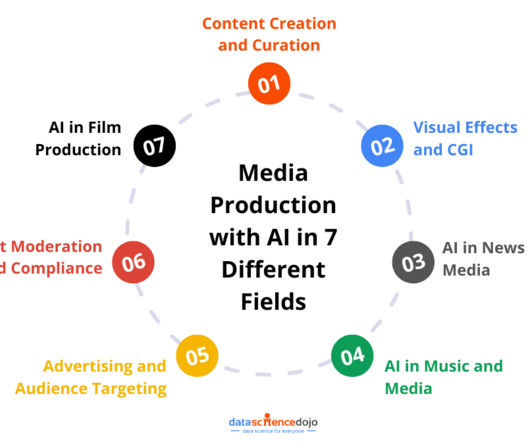
By leveraging AI-powered algorithms, media producers can improve production processes and enhance creativity. Some key benefits of integrating the production process with AI are as follows: Personalization AI algorithms can analyze user data to offer personalized recommendations for movies, TV shows, and music.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Evaluation ensures the RAG pipeline retrieves relevant documents, generates […] The post A Guide to Evaluate RAG Pipelines with LlamaIndex and TRULens appeared first on Analytics Vidhya. Over the past few months, I’ve fine-tuned my RAG pipeline and learned that effective evaluation and continuous improvement are crucial.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
However, there are more options and opportunities thanks to technological development, including AI algorithms and field boundary detection with satellite technologies. In this piece, we will delve into technologies driving the field, such as remote sensing and cutting-edge algorithms.
improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. Lexical search relies on exact keyword matching between the query and documents. For a natural language query searching for super hero toys, it retrieves documents containing those exact terms.
Models like Sentence Transformers map words, sentences, or documents into high-dimensional vectors. To find relevant text, you compare vectors using metrics like cosine similarity, retrieving documents whose embeddings are closest to the query embedding. It scores documents based on: 1. Its not purely vector space.
Introduction Document image analysis is the name for the algorithms and methods used to turn the pixels in an image into a description that a computer can understand. Optical Character Recognition, or OCR, uses computer vision to find and read the text in images.
You can then run searches for the top K documents in an index that are most similar to a given query vector, which could be a question, keyword, or content (such as an image, audio clip, or text) that has been encoded by the same ML model. To learn more, refer to the documentation.
has expanded its Phi line of open-source language models with the introduction of two new algorithms designed for multimodal processing and hardware efficiency: Phi-4-mini and Phi-4-multimodal. Microsoft Corp. Phi-4-mini and Phi-4-multimodal features Phi-4-mini is a text-only model that incorporates 3.8
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. Key components include: Orchestrated document processing with AWS Step Functions – The document processing workflow begins with AWS Step Functions , which orchestrates each step in the process.
Introducing BMX, an iteration on the industry standard BM25 search algorithm. Through the incorporation of entropy-weighted query-document similarity and weighted query augmentation, the algorithm can increase search performance on the most relevant information retrieval benchmarks.
One area where AI has made substantial strides is medical scribing, transforming the way healthcare professionals document patient encounters. In this article, we will delve into the best 5 medical AI scribes that have garnered attention for their contributions to streamlining medical documentation processes in healthcare.
By analyzing diverse data sources and incorporating advanced machine learning algorithms, LLMs enable more informed decision-making, minimizing potential risks. Entity recognition: It reduces human error by classifying documents and minimizing manual and repetitive work.
Heres how embeddings power these advanced systems: Semantic Understanding LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate Nearest Neighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
You can also learn the skills needed to use LLMs for updating software documentation to maintain accurate and up-to-date documentation, improving the overall quality and reliability of software projects. It will empower you to focus more on complex problem-solving and less on repetitive coding tasks.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
We shall look at various machine learning algorithms such as decision trees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
Providers struggle with the administrative burden of documentation and coding, which consumes 2531% of total healthcare spending and detracts from their ability to deliver quality care. healthcare billing system is a maze of documentation, coding, and reimbursement processes that creates significant friction for providers.
Collaborative text editing algorithms allow several users to concurrently modify a text file, and automatically merge concurrent edits into a consistent state. We introduce Eg-walker, a collaboration algorithm for text that avoids these weaknesses. Compared to OT, merging long-running branches is orders of magnitude faster.
The following example shows how prompt optimization converts a typical prompt for a summarization task on Anthropics Claude Haiku into a well-structured prompt for an Amazon Nova model, with sections that begin with special markdown tags such as ## Task, ### Summarization Instructions , and ### Document to Summarize.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
In addition to SageMaker enabling you to build your own models, Amazon SageMaker JumpStart offers built-in computer vision algorithms and pre-trained defect detection models that can be fine-tuned to your specific use case.
It also reduces the time to value from a single API, eliminating the need for multiple web threat intelligence integrations into SIEM, SOAR, TIP, and security tooling. aM IntelligenceTM offers a comprehensive 360-degree threat intelligence for any domain or IP address. am-intelligence. am-intelligence.
A users question is used as the query to retrieve relevant documents from a database. The documents returned by the search are added to the prompt that is passed to the LLM together with the users question. Overview of a baseline RAG system. The LLM uses the information in the prompt to generate an answer. Source What is LangChain?
Feature engineering encompasses a variety of techniques aimed at converting raw data into informative features that machine learning algorithms can utilize efficiently. High-quality features allow algorithms to recognize patterns and correlations in data more effectively. What is feature engineering?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content