This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Now, in the realm of geographic information systems (GIS), professionals often experience a complex interplay of emotions akin to the love-hate relationship one might have with neighbors. Enter KNearestNeighbor (k-NN), a technique that personifies the very essence of propinquity and Neighborly dynamics.
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! Let’s unravel the technicalities behind this technique: The Core Function: Regression algorithms learn from labeled data , similar to classification.
These scenarios demand efficient algorithms to process and retrieve relevant data swiftly. This is where Approximate NearestNeighbor (ANN) search algorithms come into play. ANN algorithms are designed to quickly find data points close to a given query point without necessarily being the absolute closest.
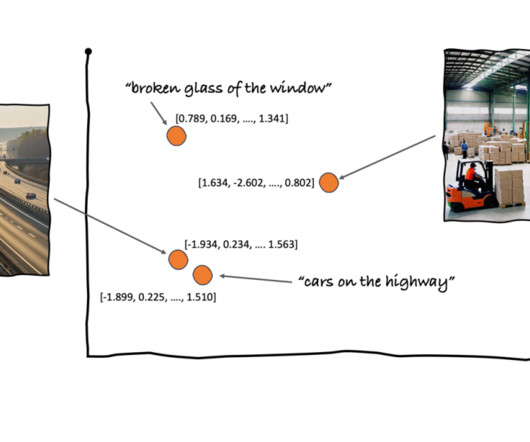
You can then run searches for the top Kdocuments in an index that are most similar to a given query vector, which could be a question, keyword, or content (such as an image, audio clip, or text) that has been encoded by the same ML model. To learn more, refer to the documentation.
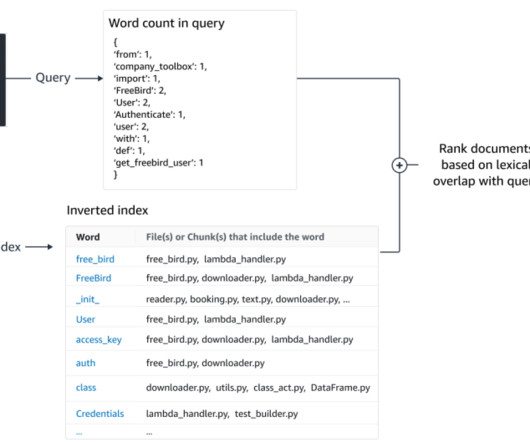
improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases.
When it comes to the three best algorithms to use for spatial analysis, the debate is never-ending. The competition for best algorithms can be just as intense in machine learning and spatial analysis, but it is based more objectively on data, performance, and particular use cases. Also, what project are you working on?
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
In this piece, we shall look at tips and tricks on how to perform particular GIS machine learning algorithms regardless of your expertise in GIS, if you are a fresh beginner with no experience or a seasoned expert in geospatial machine learning. Load required librarieslibrary(sf) # spatial datalibrary(raster) # for raster manipulation 1.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in Machine Learning Machine learning algorithms are significantly impacting diverse fields.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? For example, it takes millions of images and runs them through a training algorithm.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
For more information on managing credentials securely, see the AWS Boto3 documentation. For example: aws s3 cp /Users/username/Documents/training/loafers s3://footwear-dataset/ --recursive Confirm the upload : Go back to the S3 console, open your bucket, and verify that the images have been successfully uploaded to the bucket.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. The CRAG dataset also provides top five search result pages for each query.
These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests. This approach allows for tailored responses and processes for different types of user needs, whether its a simple question, a document translation, or a complex inquiry about IDIADAs services.
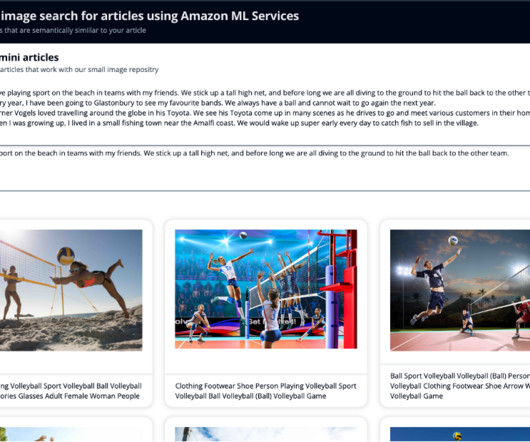
OpenSearch Service allows you to store vectors and other data types in an index, and offers rich functionality that allows you to search for documents using vectors and measuring the semantical relatedness, which we use in this post. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Another example is in the field of text document similarity. Imagine you have a vast library of documents and want to identify near-duplicate documents or find documents similar to a query document. text documents, images, and other multimedia content). Google search, YouTube search, etc.).
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
Each service uses unique techniques and algorithms to analyze user data and provide recommendations that keep us returning for more. By analyzing how users have interacted with items in the past, we can use algorithms to approximate the utility function and make personalized recommendations that users will love.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). Conversely, a smaller K leads to faster search times and lower costs, but may lower result quality.
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists. It is easy to use, with a well-documented API and a wide range of tutorials and examples available. What really makes Django are a few things. It’s also a powerful framework.
This benefits enterprise software development and helps overcome the following challenges: Sparse documentation or information for internal libraries and APIs that forces developers to spend time examining previously written code to replicate usage. This retrieval can happen using different algorithms.
Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. We will generate a measure called Term Frequency, Inverse Document Frequency, shortened to tf-idf for each term in our dataset. This data shows promise for the binary classifier that will be built.
You can reach the documentation from here. For each sample in the minority class, it selects knearestneighbors from the same class. It then selects one of these kneighbors at random and computes the difference between the feature vector of the original sample and the selected neighbor.
Spotify’s Discover Weekly ( Figure 3 ) is an algorithm-generated playlist released every Monday to offer its listeners custom, curated music recommendations. to train their algorithm. Alternating Least Squares The matrices and are optimized using alternate least squares algorithm as follows: Step 1: Initialize and randomly.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Decision Trees: A supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks.
HOGs are great feature detectors and can also be used for object detection with SVM but due to many other State of the Art object detection algorithms like YOLO, SSD, present out there, we don’t use HOGs much for object detection. This is a simple project. I have used Boston Housing Data for this use case. So without any further due.
For instance, given a certain sample if the active learning algorithm is uncertain about the correct response it can send the sample to the human annotator. Key Characteristics Synthetic Data Generation : Query synthesis algorithms actively generate new training examples rather than selecting from an existing pool.
Amazon Titan Text Embeddings models generate meaningful semantic representations of documents, paragraphs, and sentences. It supports exact and approximate nearest-neighboralgorithms and multiple storage and matching engines. RAG helps FMs deliver more relevant, accurate, and customized responses.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content