This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Intelligent document processing (IDP) is a technology that uses artificial intelligence (AI) and machine learning (ML) to automatically extract information from unstructured documents such as invoices, receipts, and forms.
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Our work further motivates novel directions for developing and evaluating tools to support human-ML interactions. Model explanations have been touted as crucial information to facilitate human-ML interactions in many real-world applications where end users make decisions informed by ML predictions.
The platform helped the agency digitize and process forms, pictures, and other documents. The federal government agency Precise worked with needed to automate manual processes for document intake and image processing. The demand for modernization is growing, and Precise can help government agencies adopt AI/ML technologies.
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. Lexical search relies on exact keyword matching between the query and documents. For a natural language query searching for super hero toys, it retrieves documents containing those exact terms.
Machine learning is a branch of artificial intelligence that focuses on developing algorithms and models that can learn from data and make predictions or decisions without being explicitly programmed. There are various types of machine learning algorithms, including supervised learning, unsupervised learning, and reinforcement learning.
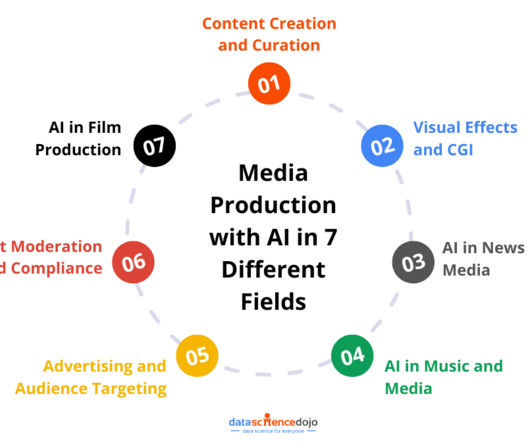
By leveraging AI-powered algorithms, media producers can improve production processes and enhance creativity. Some key benefits of integrating the production process with AI are as follows: Personalization AI algorithms can analyze user data to offer personalized recommendations for movies, TV shows, and music.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Heres how embeddings power these advanced systems: Semantic Understanding LLMs use embeddings to represent words, sentences, and entire documents in a way that captures their semantic meaning. The process enables the models to find the most relevant sections of a document or dataset, improving the accuracy and relevance of their outputs.
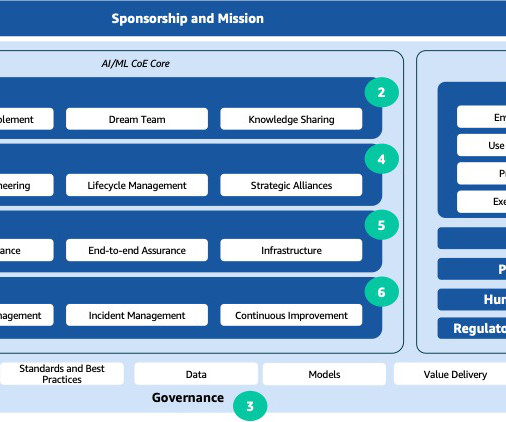
The rapid advancements in artificial intelligence and machine learning (AI/ML) have made these technologies a transformative force across industries. An effective approach that addresses a wide range of observed issues is the establishment of an AI/ML center of excellence (CoE). What is an AI/ML CoE?
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
The model then uses a clustering algorithm to group the sentences into clusters. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks. It works by first embedding the sentences in the text using BERT.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.
You can try out the models with SageMaker JumpStart, a machine learning (ML) hub that provides access to algorithms, models, and ML solutions so you can quickly get started with ML. To learn more, refer to the API documentation. You can change these configurations by specifying non-default values in JumpStartModel.
With the ability to analyze a vast amount of data in real-time, identify patterns, and detect anomalies, AI/ML-powered tools are enhancing the operational efficiency of businesses in the IT sector. Why does AI/ML deserve to be the future of the modern world? Let’s understand the crucial role of AI/ML in the tech industry.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
Amazon Lookout for Vision , the AWS service designed to create customized artificial intelligence and machine learning (AI/ML) computer vision models for automated quality inspection, will be discontinuing on October 31, 2025.
Research papers and engineering documents often contain a wealth of information in the form of mathematical formulas, charts, and graphs. Navigating these unstructured documents to find relevant information can be a tedious and time-consuming task, especially when dealing with large volumes of data.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. Deploy traditional models to SageMaker endpoints In the following examples, we showcase how to use ModelBuilder to deploy traditional ML models.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
They investigate the most suitable algorithms, identify the best weights and hyperparameters, and might even collaborate with fellow data scientists in the community to develop an effective strategy. This is where ML CoPilot enters the scene. But what if LLMs could also engage in a cooperative approach?
We don’t have better algorithms; we just have more data. Edited Photo by Taylor Vick on Unsplash In ML engineering, data quality isn’t just critical — it’s foundational. Yet, this perspective often gets sidelined and there was never a consensus in the ML community about it. Because of how ML practitioners were initially trained.
Posted by Peter Mattson, Senior Staff Engineer, ML Performance, and Praveen Paritosh, Senior Research Scientist, Google Research, Brain Team Machine learning (ML) offers tremendous potential, from diagnosing cancer to engineering safe self-driving cars to amplifying human productivity. Each step can introduce issues and biases.
Overall, we recommend openSMILE for general ML applications. Strengths: Very easy to use and well documented. The transformers approach instead relies on algorithms to identify what features are useful for downstream modeling tasks. It is focused on analyzing both speech and music.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Machine learning (ML) can help companies make better business decisions through advanced analytics. Companies across industries apply ML to use cases such as predicting customer churn, demand forecasting, credit scoring, predicting late shipments, and improving manufacturing quality.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
The explosion in deep learning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Below, we highlight a panoply of works that demonstrate Google Research’s efforts in developing new algorithms to address the above challenges.
They design, develop, and deploy the machine learning algorithms that power everything from self-driving cars to personalized recommendations. They also develop algorithms that are utilized to sort through relevant data, and scale predictive models to best suit the amount of data pertinent to the business. They build the future.
Unsupervised ML: The Basics. Unlike supervised ML, we do not manage the unsupervised model. Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised MLalgorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes.
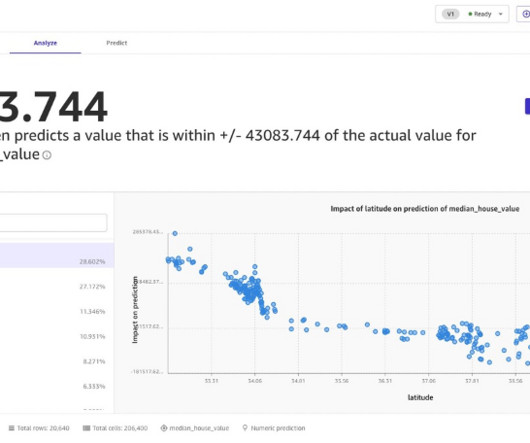
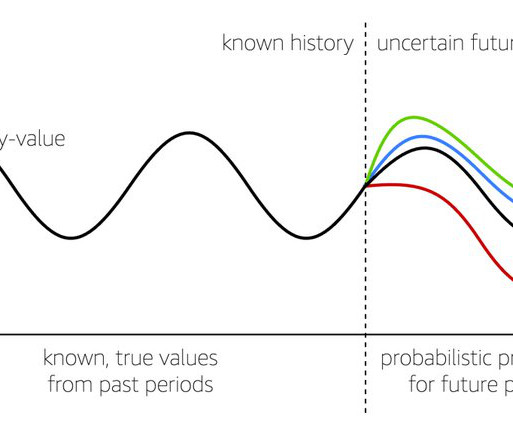
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machine learning (ML) models for forecasting. This visual, point-and-click interface democratizes ML so users can take advantage of the power of AI for various business applications. One of these methods is quantiles.
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Solution overview Document validation is a critical type of input for mortgage fraud decisions.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
We shall look at various machine learning algorithms such as decision trees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. In-depth Documentation- R facilitates repeatability by analyzing data using a script-based methodology.
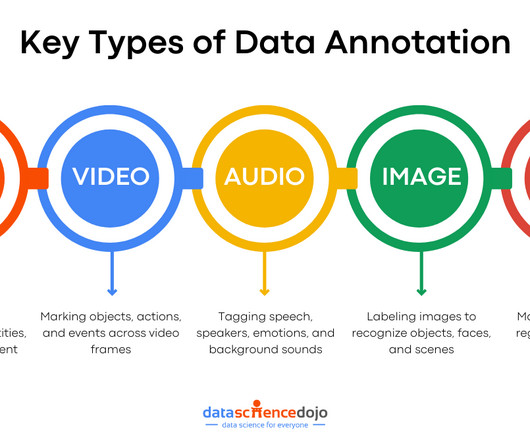
These models are trained using vast datasets and powered by sophisticated algorithms. Data annotation is the process of labeling data to make it understandable and usable for machine learning (ML) models. Legal documents, medical records, or scientific papers need experts who understand the terminology.
Companies across various industries create, scan, and store large volumes of PDF documents. There’s a need to find a scalable, reliable, and cost-effective solution to translate documents while retaining the original document formatting. It also uses the open-source Java library Apache PDFBox to create PDF documents.
Machine learning (ML) is an innovative tool that advances technology in every industry around the world. Due to its constant learning and evolution, the algorithms are able to adapt based on success and failure. Of course, these algorithms aren’t perfect, but they become more refined with every interaction. Directions.
Increasingly, FMs are completing tasks that were previously solved by supervised learning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. Foundation models (FMs) are used in many ways and perform well on tasks including text generation, text summarization, and question answering.
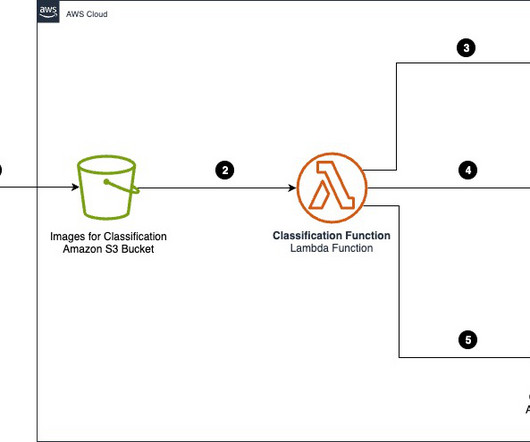
Amazon SageMaker is a comprehensive, fully managed machine learning (ML) platform that revolutionizes the entire ML workflow. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from data preparation to model deployment and monitoring. jpg") or doc.endswith(".png")) b64encode(fIn.read()).decode("utf-8")
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, MLalgorithms are increasingly being used to make decisions that impact business outcomes.
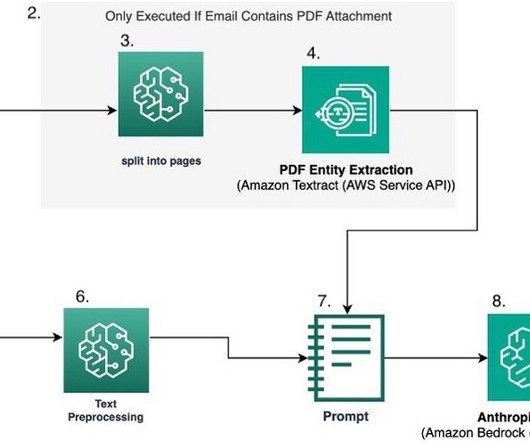
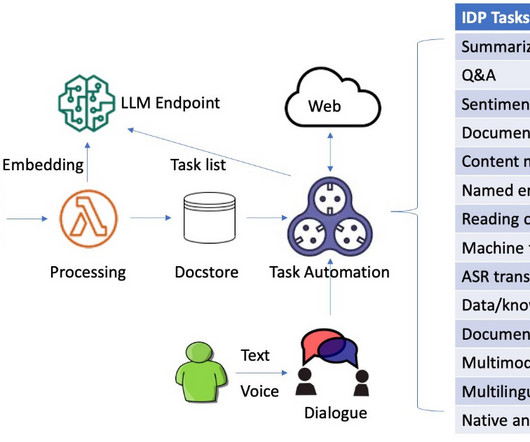
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content