This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Machine Learningalgorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learningalgorithms.
Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning. The two main approaches of interest for embeddings include unsupervised and supervisedlearning. BoW does not focus on the order of words in a text.
The model then uses a clustering algorithm to group the sentences into clusters. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks. It works by first embedding the sentences in the text using BERT.
Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning. The two main approaches of interest for embeddings include unsupervised and supervisedlearning. BoW does not focus on the order of words in a text.
When it comes to the three best algorithms to use for spatial analysis, the debate is never-ending. The competition for best algorithms can be just as intense in machine learning and spatial analysis, but it is based more objectively on data, performance, and particular use cases. Also, what project are you working on?
Multi-class classification in machine learning Multi-class classification in machine learning is a type of supervisedlearning problem where the goal is to predict one of multiple classes or categories based on input features.
Increasingly, FMs are completing tasks that were previously solved by supervisedlearning, which is a subset of machine learning (ML) that involves training algorithms using a labeled dataset. An FM-driven solution can also provide rationale for outputs, whereas a traditional classifier lacks this capability.
By dividing the workload and data across multiple nodes, distributed learning enables parallel processing, leading to faster and more efficient training of machine learning models. There are various types of machine learningalgorithms, including supervisedlearning, unsupervised learning, and reinforcement learning.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. What is machine learning? Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences.
From predicting disease outbreaks to identifying complex medical patterns and helping researchers develop targeted therapies, the potential applications of machine learning in healthcare are vast and varied. What is machine learning? From personalized medicine to disease prevention, the possibilities are endless.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, K Nearest Neighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? You just want to create and analyze simple maps not to learn algebra all over again.
Summary: This blog highlights ten crucial Machine Learningalgorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Each algorithm is explained with its applications, strengths, and weaknesses, providing valuable insights for practitioners and enthusiasts in the field.
These complex algorithms are the backbone upon which our modern technological advancements rest and which are doing wonders for natural language communication. PaLM 2 stands for “ Progressive and Adaptive Language Model 2 ” and Llama 2 is short for “ Language Learning and Mastery Algorithm 2 ”.
The built-in BlazingText algorithm offers optimized implementations of Word2vec and text classification algorithms. Text classification is essential for applications like web searches, information retrieval, ranking, and document classification. Set the learning mode hyperparameter to supervised.
INTRODUCTION Machine Learning is a subfield of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn and make predictions or decisions based on data, without being explicitly programmed. and divides them as per the presence and absence of those similar patterns.
Let us look at how the K Nearest Neighbor algorithm can be applied to geospatial analysis. A non-parametric, supervisedlearning classifier, the K-Nearest Neighbors (k-NN) algorithm uses proximity to classify or predict how a single data point will be grouped. What is K Nearest Neighbor? Benefits of k-NN for GIS 1.
Semi-Supervised Sequence Learning As we all know, supervisedlearning has a drawback, as it requires a huge labeled dataset to train. Having used multiple source documents, there have been duplicates and resulted in a huge set, which is impossible to train a model on, due to lack of processing power.
Summary: Support Vector Machine (SVM) is a supervised Machine Learningalgorithm used for classification and regression tasks. Among the many algorithms, the SVM algorithm in Machine Learning stands out for its accuracy and effectiveness in classification tasks. What is the SVM Algorithm in Machine Learning?
In this piece, we shall look at tips and tricks on how to perform particular GIS machine learningalgorithms regardless of your expertise in GIS, if you are a fresh beginner with no experience or a seasoned expert in geospatial machine learning. Load machine learning libraries. Decision Tree and R.
The answer lies in the various types of Machine Learning, each with its unique approach and application. In this blog, we will explore the four primary types of Machine Learning: SupervisedLearning, UnSupervised Learning, semi-SupervisedLearning, and Reinforcement Learning.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
With these fairly complex algorithms often being described as “giant black boxes” in news and media, a demand for clear and accessible resources is surging. Fine-tuning may involve further training the pre-trained model on a smaller, task-specific labeled dataset, using supervisedlearning.
Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data. Linear algebra is vital for understanding Machine Learningalgorithms and data manipulation. Calculus Learn to understand derivatives and integrals.
Accurate and performant algorithms are critical in flagging and removing inappropriate content. Self-supervision: As in the Image Similarity Challenge , all winning solutions used self-supervisedlearning and image augmentation (or models trained using these techniques) as the backbone of their solutions.
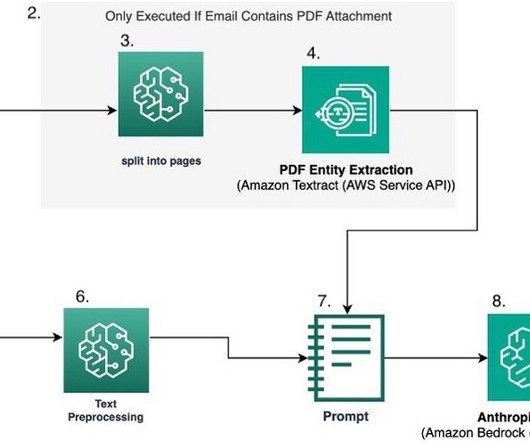
This includes formats like emails, PDFs, scanned documents, images, audio, video, and more. While this data holds valuable insights, its unstructured nature makes it difficult for AI algorithms to interpret and learn from it. Solution overview In this post, we work with a PDF documentation dataset— Amazon Bedrock user guide.
Unlike traditional software programs, AI agents use machine learning models to adapt their behavior based on data. Decision-Making: Algorithms to process inputs and decide on actions. Learning: Ability to improve performance over time using feedback loops. Unsupervised Learning: Finding hidden structures in unlabeled data.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learningalgorithms and effective data handling are also critical for success in the field.
Data is carefully analyzed and using mining algorithms, hidden patterns are extracted from the data. The models created using these algorithms could be evaluated against appropriate metrics to verify the model’s credibility. For example, clustering is used to group a large set of documents into categories based on the content.
It includes text documents, social media posts, customer reviews, emails, and more. Here are seven benefits of text mining: Information Extraction Text mining enables the extraction of relevant information from unstructured text sources such as documents, social media posts, customer feedback, and more.
Introduction Data annotation is the process of adding meaningful labels, tags, or metadata to raw data to provide context and structure for Machine Learningalgorithms. It lays the groundwork for training models, ensuring accuracy, and facilitating supervisedlearning.
Or, an LLM that is focused on the task of translating languages could be used to translate documents from one language to another. It can also be used to generate code for specific purposes, such as generating code to implement a specific algorithm or to generate code to solve a specific problem.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. There are three main types of Machine Learning: supervisedlearning, unsupervised learning, and reinforcement learning.
" } In general cases, we always have data in the form of paragraphs and documents. Even though traditional datasets are always in the form of a series of documents of either text files or word files, The problem with it is we can not feed it directly to LLM models as it requires data in a specific format.
K-Means Clustering is an unsupervised machine learningalgorithm used for clustering data points into groups or clusters based on their similarity. The algorithm tries to minimize the sum of squared distances between each data point and its assigned centroid, known as the Within-Cluster Sum of Squares (WCSS).
Why machine learning systems need annotated examples Most AI systems today rely on supervisedlearning : you provide labelled input and output pairs, and get a program that can perform analogous computation for new data. To get started, we’ll want to search for a query that returns a decent number of documentation issues.
Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data. They can also perform self-supervisedlearning to generalize and apply their knowledge to new tasks.
Speech recognition algorithms has the ability to understand natural language and allows us to interact with the machines in a natural way. One notable application of machine learning speech recognition algorithms can be observed in the legal field. This facilitates faster access to relevant information.
We previously explored a single job optimization, visualized the outcomes for SageMaker built-in algorithm, and learned about the impact of particular hyperparameter values. In this post, we run multiple HPO jobs with a custom training algorithm and different HPO strategies such as Bayesian optimization and random search.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Decision Trees: A supervisedlearningalgorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks.
Artificial Intelligence (AI) models are the building blocks of modern machine learningalgorithms that enable machines to learn and perform complex tasks. These models are designed to replicate the human brain’s cognitive functions, enabling them to perceive, reason, learn, and make decisions based on data.
Artificial Intelligence (AI) models are the building blocks of modern machine learningalgorithms that enable machines to learn and perform complex tasks. These models are designed to replicate the human brain’s cognitive functions, enabling them to perceive, reason, learn, and make decisions based on data.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. What is machine learning (ML)?
AI algorithms can analyze large data sets containing patient health records and find patterns that can point to a specific disease or condition. Synthetic data and creating better records When creating these AI programs, synthetic data is key to anonymous algorithms since they mimic real-world datasets. But that’s not all.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content