This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Overview Lots of financial losses are caused every year due to credit card fraud transactions, the financial industry has switched from a posterior investigation approach to an a priori predictive approach with the design of fraud detection algorithms to warn and help fraud investigators. […].
The development of a Machine Learning Model can be divided into three main stages: Building your ML data pipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc. In this article, we’re going to cover 11 data exploration tools that are specifically designed for exploration and analysis. Output is a fully self-contained HTML application.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production. ExploratoryDataAnalysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
Mathematical Foundations In addition to programming concepts, a solid grasp of basic mathematical principles is essential for success in Data Science. Mathematics is critical in DataAnalysis and algorithm development, allowing you to derive meaningful insights from data.
From Predicting the behavior of a customer to automating many tasks, Machine learning has shown its capacity to convert raw data into actionable insights. Even though converting raw data into actionable insights, it is not determined by ML algorithms alone. This process is called ExploratoryDataAnalysis(EDA).
We can apply a data-centric approach by using AutoML or coding a custom test harness to evaluate many algorithms (say 20–30) on the dataset and then choose the top performers (perhaps top 3) for further study, being sure to give preference to simpler algorithms (Occam’s Razor).
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Data scientists are the master keyholders, unlocking this portal to reveal the mysteries within. They wield algorithms like ancient incantations, summoning patterns from the chaos and crafting narratives from raw numbers. Model development : Crafting magic from algorithms!
In Python, commonly used libraries include: Pandas: For data manipulation and analysis, particularly for handling structured data. Scikit-learn: For Machine Learning algorithms and preprocessing utilities. Matplotlib/Seaborn: For data visualization. During EDA, you can: Check for missing values.
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform ExploratoryDataAnalysis to uncover patterns and insights hidden within the data. Integrated data provides a comprehensive view and improves analysis accuracy.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
METAR, Miami International Airport (KMIA) on March 9, 2024, at 15:00 UTC In the recently concluded data challenge hosted on Desights.ai , participants used exploratorydataanalysis (EDA) and advanced artificial intelligence (AI) techniques to enhance aviation weather forecasting accuracy.
First of all, HR needs to collect comprehensive data about an employee, such as education, salary, experience… We also need data from supervisors such as performance, relationships, promotions… After that, HR can use this information to predict employees’ tendency to leave and take preventive action. TRAIN ==Staying Rate: 83.87%Leaving
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Time features Objective: Extracting valuable information from time-related data.
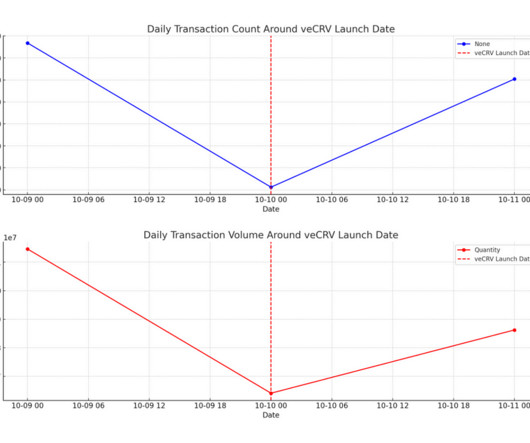
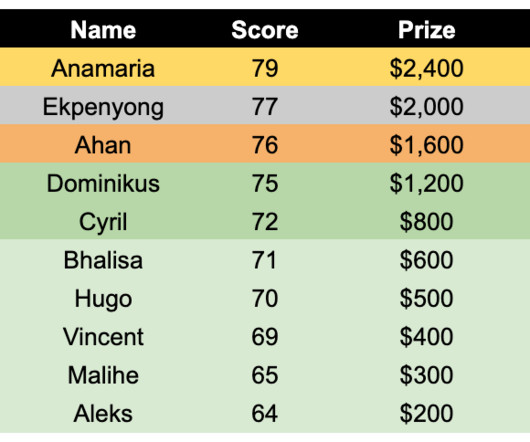
Abstract This research report encapsulates the findings from the Curve Finance Data Challenge , a competition that engaged 34 participants in a comprehensive analysis of the decentralized finance protocol. Part 1: ExploratoryDataAnalysis (EDA) MEV Over 25,000 MEV-related transactions have been executed through Curve.
ExploratoryDataAnalysis (EDA) ExploratoryDataAnalysis (EDA) is an approach to analyse datasets to uncover patterns, anomalies, or relationships. The primary purpose of EDA is to explore the data without any preconceived notions or hypotheses.
F1 :: 2024 Strategy Analysis Poster ‘The Formula 1 Racing Challenge’ challenges participants to analyze race strategies during the 2024 season. They will work with lap-by-lap data to assess how pit stop timing, tire selection, and stint management influence race performance.
ExploratoryDataAnalysis (EDA): Using statistical summaries and initial visualisations (yes, visualisation plays a role within analysis!) to understand the data’s main characteristics, distributions, and relationships. EDA: Calculate overall churn rate. This helps formulate hypotheses.
Blind 75 LeetCode Questions - LeetCode Discuss Data Manipulation and Analysis Proficiency in working with data is crucial. This includes skills in data cleaning, preprocessing, transformation, and exploratorydataanalysis (EDA).
In the Kelp Wanted challenge, participants were called upon to develop algorithms to help map and monitor kelp forests. Winning algorithms will not only advance scientific understanding, but also equip kelp forest managers and policymakers with vital tools to safeguard these vulnerable and vital ecosystems.
The challenge required a detailed analysis of Google Trends data, integration of additional data sources, and the application of advanced ML methods to predict market behaviors. Data scientists across various expertise levels engaged in this challenge to determine Google Trends’ impact on cryptocurrency valuations.
For DataAnalysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as ExploratoryDataAnalysis. Unsupervised Learning In this type of learning, the algorithm is trained on an unlabeled dataset, where no correct output is provided.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learning algorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learning algorithms.
Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data. Importance of Data in AI Quality data is the lifeblood of AI models, directly influencing their performance and reliability.
Model-centric approach In this approach, the data always remains the same and is used to iteratively improve the model to meet desired results. We use the model preview functionality to perform an initial EDA.
Collaborating with data scientists, to ensure optimal model performance in real-world applications. With expertise in Python, machine learning algorithms, and cloud platforms, machine learning engineers optimize models for efficiency, scalability, and maintenance.
Business questions to brainstorm: Since all features are anonymous, we will focus our analysis on non-anonymized features: Time, Amount How different is the amount of money used in different transaction classes? ExploratoryDataAnalysis — EDA Let us now check the missing values in the dataset.
We also demonstrate the performance of our state-of-the-art point cloud-based product lifecycle prediction algorithm. Challenges One of the challenges we faced while using fine-grained or micro-level modeling like product-level models for sale prediction was missing sales data.
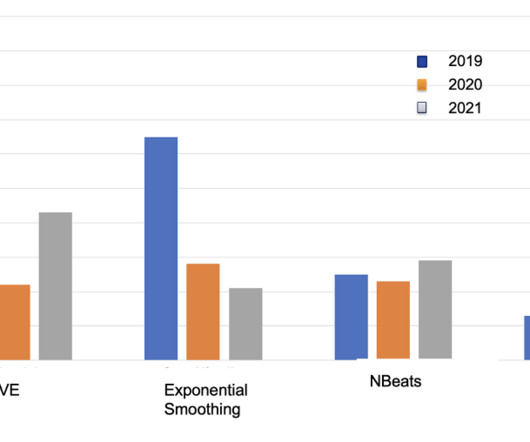
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. Advanced algorithms recognize patterns in temporal data effectively. Making Data Stationary: Many forecasting models assume stationarity.
Provided information included telemetry data covering each race, including variables like tire choices, stint lengths, lap times, and pit stop durations. Each participant performed ExploratoryDataAnalysis (EDA) to uncover relationships between variables like tire degradation and race performance.
The ML platform can utilize historic customer engagement data, also called “clickstream data”, and transform it into features essential for the success of the search platform. From an algorithmic perspective, Learning To Rank (LeToR) and Elastic Search are some of the most popular algorithms used to build a Seach system.
Basic Data Science Terms Familiarity with key concepts also fosters confidence when presenting findings to stakeholders. Below is an alphabetical list of essential Data Science terms that every Data Analyst should know. Anomaly Detection: Identifying unusual patterns or outliers in data that do not conform to expected behaviour.
Understanding the Session In this engaging and interactive session, we will delve into PySpark MLlib, an invaluable resource in the field of machine learning, and explore how various classification algorithms can be implemented using AWS Glue/EMR as our platform. But this session goes beyond just concepts and algorithms.
Predictive Analytics Projects: Predictive analytics involves using historical data to predict future events or outcomes. Techniques like regression analysis, time series forecasting, and machine learning algorithms are used to predict customer behavior, sales trends, equipment failure, and more.
Here we use data science to diagnose the issues and propose better practices to treat our planet better than the last 30 years. ExploratoryDataAnalysis (EDA) In Asia, the surge in CO2 and GHG emissions is closely linked to rapid population growth, industrialization, and the rise of emerging economies.
New developers should learn basic concepts (e.g. Submission Suggestions Generative AI in Software Development was originally published in MLearning.ai on Medium, where people are continuing the conversation by highlighting and responding to this story. New developers should learn basic concepts (e.g.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
With the completion of AdaBoost, we are one more step closer to understanding the XGBoost algorithm. load the data in the form of a csv estData = pd.read_csv("/content/realtor-data.csv") # drop NaN values from the dataset estData = estData.dropna() # split the labels and remove non-numeric data y = estData["price"].values
In this article, let’s dive deep into the Natural Language Toolkit (NLTK) data processing concepts for NLP data. Before building our model, we will also see how we can visualize this data with Kangas as part of exploratorydataanalysis (EDA). This, in turn, reduces the time complexity and space.
Guide users on how to clean and preprocess data, handle missing values, normalize datasets, and provide insights on exploratorydataanalysis (EDA) and inferential statistics.
Amongst other ML competitions, I have been in a prize-winning position for NASA SOHO comet search, NOAA Precipitation Prediction (Rodeo 2), the Spacenet-8 flood detection, and 2019 IEEE GRSS data fusion contest. I enjoy participating in machine learning/data-science challenges and have been doing it for a while. race and sex).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content