This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ETL during the process of producing effective machine learning algorithms is found at the base - the foundation. Let’s go through the steps on how ETL is important to machine learning.
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. However, the exponential growth in data volume, velocity, and variety is challenging the traditional paradigms of ETL, ushering in a transformative era.
How to Perform Motion Detection Using Python • The Complete Collection of Data Science Projects – Part 2 • Free AI for Beginners Course • Decision Tree Algorithm, Explained • What Does ETL Have to Do with Machine Learning?
Learn the basics of data engineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. When the data is not good, the algorithms trained on it will not be good either. The whole thing is very exciting, but where do I get the data from?
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
Here are a few of the things that you might do as an AI Engineer at TigerEye: - Design, develop, and validate statistical models to explain past behavior and to predict future behavior of our customers’ sales teams - Own training, integration, deployment, versioning, and monitoring of ML components - Improve TigerEye’s existing metrics collection and (..)
They require strong programming skills, expertise in machine learning algorithms, and knowledge of data processing. Machine Learning Engineer Machine learning engineers are responsible for designing and building machine learning systems.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
It uses algorithms to find patterns and make predictions based on the data, such as predicting what a user will click on. It focuses on two aspects of data management: ETL (extract-transform-load) and data lifecycle management. It also has ML algorithms built into the platform. It has built-in support for machine learning.
Keboola, for example, is a SaaS solution that covers the entire life cycle of a data pipeline from ETL to orchestration. Next is Stitch, a data pipeline solution that specializes in smoothing out the edges of the ETL processes thereby enhancing your existing systems. K2View leaps at the traditional approach to ETL and ELT tools.
ABOUT EVENTUAL Eventual is a data platform that helps data scientists and engineers build data applications across ETL, analytics and ML/AI. OUR PRODUCT IS OPEN-SOURCE AND USED AT ENTERPRISE SCALE Our distributed data engine Daft [link] is open-sourced and runs on 800k CPU cores daily. WE'RE GROWING - COME GROW WITH US!
For data at rest within the castle, Advanced Encryption Standard (AES) algorithms ensure that even if unauthorized access occurs, the data remains indecipherable. Secure Data Integration and ETL Processes : Implement secure data integration practices to ensure that data flowing into your warehouse is not compromised.
Iris was designed to use machine learning (ML) algorithms to predict the next steps in building a data pipeline. Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines. We use the following prompt: Human: Your job is to act as an expert on ETL pipelines.
In this new reality, leveraging processes like ETL (Extract, Transform, Load) or API (Application Programming Interface) alone to handle the data deluge is not enough. AI-data mapping tools allow even non-technical business users to create intelligent data mappings using Machine Learning algorithms.
Transform raw insurance data into CSV format acceptable to Neptune Bulk Loader , using an AWS Glue extract, transform, and load (ETL) job. Run an AWS Glue ETL job to merge the raw property and auto insurance data into one dataset and catalog the merged dataset. Under Data classification tools, choose Record Matching.
These software tools rely on sophisticated big data algorithms and allow companies to boost their sales, business productivity and customer retention. This tool is designed to connect various data sources, enterprise applications and perform analytics and ETL processes.
With the help of the insights, we make further decisions on how to experiment and optimize the data for further application of algorithms for developing prediction or forecast models. What are ETL and data pipelines? The data pipelines follow the Extract, Transform, and Load (ETL) framework.
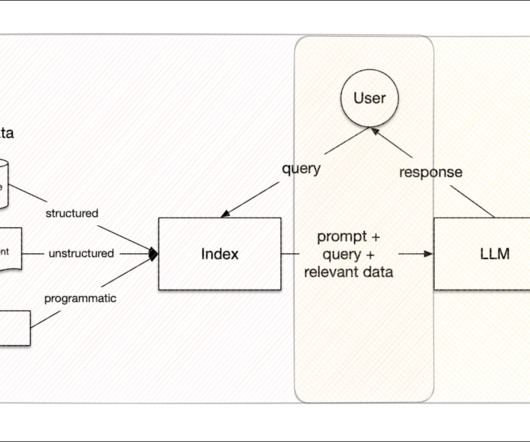
It possesses a suite of features that streamline data tasks and amplify the performance of LLMs for a variety of applications, including: Data Connectors: Data connectors simplify the integration of data from various sources to the data repository, bypassing manual and error-prone extraction, transformation, and loading (ETL) processes.
From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes. Have you ever wondered how these algorithms arrive at their conclusions? Executives evaluating decisions made by ML algorithms need to have faith in the conclusions they produce.
Predictive analytics: Predictive analytics leverages historical data and statistical algorithms to make predictions about future events or trends. Machine learning and AI analytics: Machine learning and AI analytics leverage advanced algorithms to automate the analysis of data, discover hidden patterns, and make predictions.
From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Implementing these practices can enhance the efficiency and consistency of ETL workflows.
There’s a massive number of different systems, strategies, and algorithms out there for indexing and querying data. For those new around here: our platform, Flow, is in effect a real-time ETL tool, but it’s also a real-time data lake with transactional support. And there’s a perfectly good reason for that! The world of data is huge.
They build production-ready systems using best-practice containerisation technologies, ETL tools and APIs. Below we outline three of our favourites: From XGBoost to NGBoost NGBoost is a machine learning algorithm that goes beyond the already powerful XGBoost by predicting an interval , instead of a single point estimate.
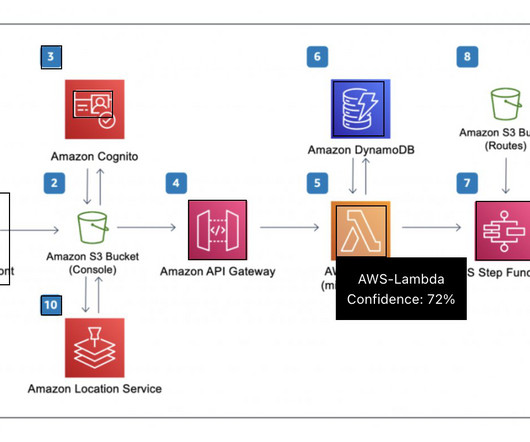
To obtain such insights, the incoming raw data goes through an extract, transform, and load (ETL) process to identify activities or engagements from the continuous stream of device location pings. As part of the initial ETL, this raw data can be loaded onto tables using AWS Glue.
Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. What is Data Profiling in ETL? The method makes use of business rules and analytical algorithms to minutely analyse data for discrepancies. FAQ: What is the difference between data profiling and ETL?
Using Amazon CloudWatch for anomaly detection Amazon CloudWatch supports creating anomaly detectors on specific Amazon CloudWatch Log Groups by applying statistical and ML algorithms to CloudWatch metrics. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for data preparation before analysis. Data Analysis and Modeling This stage is focused on discovering patterns, trends, and insights through statistical methods, machine-learning models, and algorithms. And Why did it happen?).
Solution overview The following diagram shows the architecture reflecting the workflow operations into AI/ML and ETL (extract, transform, and load) services. Here we built a custom key phrases extraction model in SageMaker using the RAKE (Rapid Automatic Keyword Extraction) algorithm, following the process shown in the following figure.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Data Engineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
It offers the advantage of having a single ETL platform to develop and maintain. Requirements that clearly speak in favor of Kappa: When the algorithms applied to the real-time data and the historical data are identical. When fast responses are required, but the system must be able to handle different update cycles.
Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools. Azure Synapse also integrates Azure Data Factory for ETL processes and includes robust security features such as encryption and role-based access control. Its PostgreSQL foundation ensures compatibility with most SQL clients.
Towhee is a framework that provides ETL for unstructured data using SoTA machine learning models. Flexibility: Milvus supports various distance metrics and indexing algorithms, allowing you to customize the search based on your specific needs. It allows to create data processing pipelines.
The customer used this pipeline for small and medium scale models, which included using various types of open-source algorithms. One of the key benefits of SageMaker is that various types of algorithms can be brought into SageMaker and deployed using a bring your own container (BYOC) technique.
They assert that you can achieve significant outcomes with just a few lines of code, sidestepping the complexities of machine learning, AI, ETL processes, or detailed system tuning. To demonstrate this concept, I wrote a short demo in just ten lines of Python code using the k-nearest neighbors algorithm (KNN).
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. For example, searching for the terms “How to orchestrate ETL pipeline” returns results of architecture diagrams built with AWS Glue and AWS Step Functions.
This unstructured nature poses challenges for direct analysis, as sentiments cannot be easily interpreted by traditional machine learning algorithms without proper preprocessing. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Amazon Personalize offers a variety of recommendation recipes (algorithms), such as the User Personalization and Trending Now recipes, which are particularly suitable for training news recommender models. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema.
The system used advanced analytics and mostly classic machine learning algorithms to identify patterns and anomalies in claims data that may indicate fraudulent activity. If you aren’t aware already, let’s introduce the concept of ETL. We primarily used ETL services offered by AWS. Redshift, S3, and so on.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets. Early warning systems prevent degradation at scale.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in Python, machine learning algorithms, and cloud platforms, machine learning engineers optimize models for efficiency, scalability, and maintenance. ETL Tools: Apache NiFi, Talend, etc. Read more to know.
This involves several key processes: Extract, Transform, Load (ETL): The ETL process extracts data from different sources, transforms it into a suitable format by cleaning and enriching it, and then loads it into a data warehouse or data lake. What Are Some Common Tools Used in Business Intelligence Architecture?
New algorithms are constantly being added to the platform, from classic linear regression to adaptive neural networks, using an intelligent search to automatically configure the architecture. The process is simple, and if you have a Snowflake account, getting data from the Snowflake Data Marketplace involves only a few clicks.
Knowledge of Core Data Engineering Concepts Ensure one possess a strong foundation in core data engineering concepts, which include data structures, algorithms, database management systems, data modeling , data warehousing , ETL (Extract, Transform, Load) processes, and distributed computing frameworks (e.g., Hadoop, Spark).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content