This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
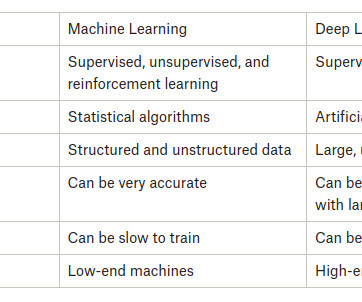
Summary: Machine Learning’s key features include automation, which reduces human involvement, and scalability, which handles massive data. It uses predictive modelling to forecast future events and adaptiveness to improve with new data, plus generalization to analyse fresh data.
Data scientists use algorithms for creating data models. Probability is the measurement of the likelihood of events. Probability distributions are collections of all events and their probabilities. Whereas in machine learning, the algorithm understands the data and creates the logic. Semi-SupervisedLearning.
They dive deep into artificial neural networks, algorithms, and data structures, creating groundbreaking solutions for complex issues. These professionals venture into new frontiers like machine learning, natural language processing, and computer vision, continually pushing the limits of AI’s potential.
Amazon Simple Queue Service (Amazon SQS) Amazon SQS is used to queue events. It consumes one event at a time so it doesnt hit the rate limit of Cohere in Amazon Bedrock. This is the k-nearest neighbor (k-NN) algorithm. This algorithm is used to perform classification and regression tasks. What are embeddings?
As organizations collect larger data sets with potential insights into business activity, detecting anomalous data, or outliers in these data sets, is essential in discovering inefficiencies, rare events, the root cause of issues, or opportunities for operational improvements. But what is an anomaly and why is detecting it important?
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions.
AI practitioners choose an appropriate machine learning model or algorithm that aligns with the problem at hand. Common choices include neural networks (used in deep learning), decision trees, support vector machines, and more. Over time, the algorithm improves its accuracy and can make better predictions on new, unseen data.
In the world of data science, few events garner as much attention and excitement as the annual Neural Information Processing Systems (NeurIPS) conference. 2023’s event, held in New Orleans in December, was no exception, showcasing groundbreaking research from around the globe.
With its advanced algorithms and language comprehension, it can navigate complex datasets and distill valuable insights. This synthetic data serves as a viable alternative for training models, testing algorithms, and ensuring privacy compliance. Interested in attending an ODSC event? Learn more about our upcoming events here.
Three years later, the code was released as hey solution for machine learningalgorithms in conjunction with Google and several other major companies. Scikit-learn is a library that contains several implementations of machine learningalgorithms. Decision boundary learning with SVMs.
Then identifying issues that allow fine-tuning of code, optimizing algorithms, and making strategic use of parallel processing. With a full track devoted to NLP and LLMs , you’ll enjoy talks, sessions, events, and more that squarely focus on this fast-paced field. Interested in attending an ODSC event?
Mathematics is critical in Data Analysis and algorithm development, allowing you to derive meaningful insights from data. Linear algebra is vital for understanding Machine Learningalgorithms and data manipulation. Calculus Learn to understand derivatives and integrals.
It can also be used to generate code for specific purposes, such as generating code to implement a specific algorithm or to generate code to solve a specific problem. With a full track devoted to NLP and LLMs , you’ll enjoy talks, sessions, events, and more that squarely focus on this fast-paced field.
The emergence of transformers and self-supervisedlearning methods has allowed us to tap into vast quantities of unlabeled data, paving the way for large pre-trained models, sometimes called “ foundation models.” But this is starting to change. Efficiency and sustainability are core design principles for watsonx.ai.
Machine Learning has become a fundamental part of people’s lives and it typically holds two segments. It includes supervised and unsupervised learning. SupervisedLearning deals with labels data and unsupervised learning deals with unlabelled data. What is Regression in ML?
Data is carefully analyzed and using mining algorithms, hidden patterns are extracted from the data. The models created using these algorithms could be evaluated against appropriate metrics to verify the model’s credibility. The unusual data points may point to a problem or rare event that can be subject to further investigation.
The Snorkel papers cover a broad range of topics including fairness, semi-supervisedlearning, large language models (LLMs), and domain-specific models. We are excited to present the following papers and presentations during this year’s event. Characterizing the Impacts of Semi-supervisedLearning for Weak Supervision Li et al.
AI began back in the 1950s as a simple series of “if, then rules” and made its way into healthcare two decades later after more complex algorithms were developed. Since the advent of deep learning in the 2000s, AI applications in healthcare have expanded. A few AI technologies are empowering drug design.
Posted by Catherine Armato, Program Manager, Google The Eleventh International Conference on Learning Representations (ICLR 2023) is being held this week as a hybrid event in Kigali, Rwanda. We are proud to be a Diamond Sponsor of ICLR 2023, a premier conference on deep learning, where Google researchers contribute at all levels.
As industries begin to scale and learn how to fully utilize the power of AI, it’s likely that more and more machine learning engineers will work closely to further refine prompt strategies, curbing biases and advancing human-AI conversations.
Introduction Data annotation is the process of adding meaningful labels, tags, or metadata to raw data to provide context and structure for Machine Learningalgorithms. It lays the groundwork for training models, ensuring accuracy, and facilitating supervisedlearning.
The Snorkel papers cover a broad range of topics including fairness, semi-supervisedlearning, large language models (LLMs), and domain-specific models. We are excited to present the following papers and presentations during this year’s event. Characterizing the Impacts of Semi-supervisedLearning for Weak Supervision Li et al.
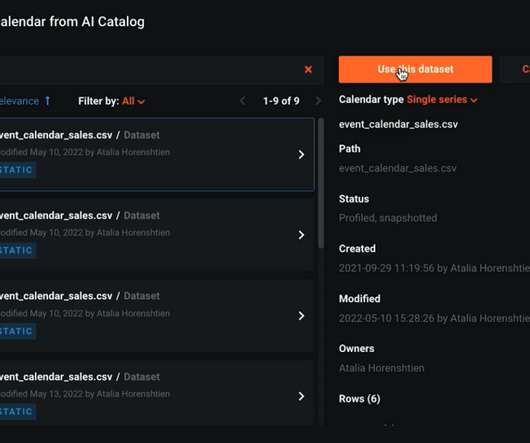
supervisedlearning and time series regression). For example, how holidays and events affect forecasting. ML pipelines containing preprocessing steps, modeling algorithms, and post-processing steps. For example, choosing the ‘tourist event’ feature shows us that holding such events results in higher sales.
Building a Solid Foundation in Mathematics and Programming To become a successful machine learning engineer, it’s essential to have a strong foundation in mathematics and programming. Mathematics is crucial because machine learningalgorithms are built on concepts such as linear algebra, calculus, probability, and statistics.
With a foundation model, often using a kind of neural network called a “transformer” and leveraging a technique called self-supervisedlearning, you can create pre-trained models for a vast amount of unlabeled data. This is usually text, but it can also be code, IT events, time series, geospatial data, or even molecules.
AI for cybersecurity leverages AI ML services to assess and correlate events and security threats across multiple sources and turn them into actionable insights that the security team uses for further assessment, response, and reporting. AI uses machine learningalgorithms to consistently learn the data that the system assesses.
EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI. Interested in attending an ODSC event? Learn more about our upcoming events here.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Looking for the source code to this post?
Synthetic data is artificial data that is created by algorithms. Teams that use synthetic data are in greater control of the data they use so they can even go so far as to create data about rare events or data that is sensitive or confidential, such as with delicate medical information or time-series data.
Posted by Cat Armato, Program Manager, Google Groups across Google actively pursue research in the field of machine learning (ML), ranging from theory and application. We build ML systems to solve deep scientific and engineering challenges in areas of language, music, visual processing, algorithm development, and more.
Week 1: Introduction to AI Dive deep into the basics of AI and machine learning during week 1. Explore the different types of AI and then fundamental concepts like algorithms, models, and features. Week 2: Machine Learning Data Prep with Python Learn the fundamentals of one of the most powerful tools for data prep during week 2.
Finding efficient and fast matrix multiplication algorithms is therefore paramount given that they will supercharge every neural network, potentially allowing us to run models prohibited by our current hardware limitations. Recently, DeepMind devised a method to automatically discover new faster matrix multiplication algorithms.
AI algorithms can analyze large data sets containing patient health records and find patterns that can point to a specific disease or condition. Synthetic data and creating better records When creating these AI programs, synthetic data is key to anonymous algorithms since they mimic real-world datasets. But that’s not all.
This event sparked significant advancements in autonomy, not just for self-driving cars but also for the broader field of robotics. In supervisedlearning , as Francis explained, a robot is trained by being given correct answers for tasks — such as identifying toys from images — over many iterations.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Decision Trees: A supervisedlearningalgorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. What is self-supervisedlearning? Self-supervisedlearning is a kind of machine learning that creates labels directly from the input data. Find out in the guide below.
A key component of artificial intelligence is training algorithms to make predictions or judgments based on data. This process is known as machine learning or deep learning. Two of the most well-known subfields of AI are machine learning and deep learning. What is Machine Learning?
ScikitLLM is interesting because it seamlessly integrates LLMs into your traditional Scikit-learn (Sklearn) library. This means Scikit-LLM brings the power of powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks.
Bioinformatics algorithms and tools have played a crucial role in analyzing NGS data, enabling researchers to study genetic variations, gene expression patterns, and epigenetic modifications on a large scale. While bioinformatics has made remarkable strides in advancing biological research, it faces several challenges that must be overcome.
Over the past year, new terms, developments, algorithms, tools, and frameworks have emerged to help data scientists and those working with AI develop whatever they desire. There’s a lot to learn for those looking to take a deeper dive into generative AI and actually develop those tools that others will use.
This technology has broad applications, including aiding individuals with visual impairments, improving image search algorithms, and integrating optical recognition with advanced language generation to enhance human-machine interactions. Various algorithms are employed in image captioning, including: 1.
Data Streaming Learning about real-time data collection methods using tools like Apache Kafka and Amazon Kinesis. Students should understand the concepts of event-driven architecture and stream processing. Students should learn how to apply machine learning models to Big Data.
Mapping these farms allows policy-makers to allocate resources and monitor the impacts of extreme events on food production and food security. In this challenge, the objective is to design machine learningalgorithms for classifying crop field boundaries using multispectral observations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content