This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction on ExploratoryDataAnalysis When we start with data science we all want to dive in and apply some cool sounding algorithms like Naive Bayes, XGBoost directly to our data and expects to get some magical results.
Overview Lots of financial losses are caused every year due to credit card fraud transactions, the financial industry has switched from a posterior investigation approach to an a priori predictive approach with the design of fraud detection algorithms to warn and help fraud investigators. […].
Understanding supervised learning In supervised learning, algorithms learn from training data that includes input-output pairs. Advantages of using linear regression Linear regression has several benefits, including: Its a straightforward method, facilitating exploratorydataanalysis.
The development of a Machine Learning Model can be divided into three main stages: Building your ML data pipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
Ability to apply math and statistics appropriately Exploratorydataanalysis is a crucial step in the data science process, as it allows data scientists to identify important patterns and relationships in the data, and to gain insights that inform decisions and drive business growth.
Their expertise lies in designing algorithms, optimizing models, and integrating them into real-world applications. The rise of machine learning applications in healthcare Data scientists, on the other hand, concentrate on dataanalysis and interpretation to extract meaningful insights.
It involves exploratorydataanalysis, data cleansing, selecting the optimal set of independent variables, picking the most appropriate algorithm, implementing it efficiently, fine-tuning the parameters to predict the outcome more accurately, and a long list of other elements.
It could explain how these distributions are used in different machine learning algorithms and why understanding them is crucial for data scientists. 32 datasets to uplift your skills in data science Data Science Dojo has created an archive of 32 data sets for you to use to practice and improve your skills as a data scientist.
Some of the applications of data science are driverless cars, gaming AI, movie recommendations, and shopping recommendations. Since the field covers such a vast array of services, data scientists can find a ton of great opportunities in their field. Data scientists use algorithms for creating data models.
There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc. In this article, we’re going to cover 11 data exploration tools that are specifically designed for exploration and analysis. Output is a fully self-contained HTML application.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production. ExploratoryDataAnalysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
It could explain how these distributions are used in different machine learning algorithms and why understanding them is crucial for data scientists. The data sets are categorized according to varying difficulty levels to be suitable for everyone.
Once you have downloaded the dataset, you can upload it to the Watson Studio instance by going to the Assets tab and then dropping the data files as shown below. Add Data You can access the data from the notebook once it has been added to the Watson Studio project. Dataframe head 2. sample(frac=0.8,
Data Pre-Processing Handling Missing Values Encoding Categorical Variables Feature Scaling Data Splitting (Training and Validation) 4. Model Development & Model Evaluation Algorithm Selection Model Training Model Evaluation Metrics 1. You can see the code as mentioned below to gather data and to do exploratorydataanalysis.
Mathematical Foundations In addition to programming concepts, a solid grasp of basic mathematical principles is essential for success in Data Science. Mathematics is critical in DataAnalysis and algorithm development, allowing you to derive meaningful insights from data.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Nevertheless, its applications across classification, regression, and anomaly detection tasks highlight its importance in modern data analytics methodologies.
Although a data pipeline can serve several functions, here are a few main use cases of them in the industry: Data Visualizations represent any data via graphics like plots, infographics, charts, and motion graphics. Data Pipeline Architecture Planning.
We can apply a data-centric approach by using AutoML or coding a custom test harness to evaluate many algorithms (say 20–30) on the dataset and then choose the top performers (perhaps top 3) for further study, being sure to give preference to simpler algorithms (Occam’s Razor).
Python machine learning packages have emerged as the go-to choice for implementing and working with machine learning algorithms. These libraries, with their rich functionalities and comprehensive toolsets, have become the backbone of data science and machine learning practices. Why do you need Python machine learning packages?
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
Data scientists are the master keyholders, unlocking this portal to reveal the mysteries within. They wield algorithms like ancient incantations, summoning patterns from the chaos and crafting narratives from raw numbers. Model development : Crafting magic from algorithms!
From Predicting the behavior of a customer to automating many tasks, Machine learning has shown its capacity to convert raw data into actionable insights. Even though converting raw data into actionable insights, it is not determined by ML algorithms alone. This process is called ExploratoryDataAnalysis(EDA).
These models, which are based on artificial intelligence and machine learning algorithms, are designed to process vast amounts of natural language data and generate new content based on that data. It wasn’t until the development of deep learning algorithms in the 2000s and 2010s that LLMs truly began to take shape.
The existing algorithms were not efficient. He was director of science at Zilliant when he left to join the Gap, where he oversees three data science subteams: price optimization, inventory management, and fulfillment optimization. There are eight of what he calls spokes in data science.
An entire statistical analysis of those entities in the dataset should be carried out. Finally, specific algorithms should run on top of that analysis. LLMs are broadly incapable of solving such multifaceted tasks, contrary to most text analysis tools, which can seamlessly solve all of the mentioned tasks.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. It entails developing computer programs that can improve themselves on their own based on expertise or data. What is Unsupervised Machine Learning?
You will collect and clean data from multiple sources, ensuring it is suitable for analysis. You will perform ExploratoryDataAnalysis to uncover patterns and insights hidden within the data. Data Integration Data integration combines data from different sources into a single dataset.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Text data is often unstructured, making it challenging to directly apply machine learning algorithms for sentiment analysis.
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Time features Objective: Extracting valuable information from time-related data.
In Python, commonly used libraries include: Pandas: For data manipulation and analysis, particularly for handling structured data. Scikit-learn: For Machine Learning algorithms and preprocessing utilities. Matplotlib/Seaborn: For data visualization. NumPy: For numerical operations and handling arrays.
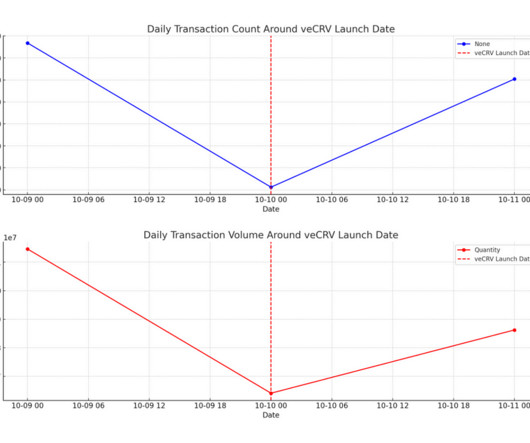
Abstract This research report encapsulates the findings from the Curve Finance Data Challenge , a competition that engaged 34 participants in a comprehensive analysis of the decentralized finance protocol. Part 1: ExploratoryDataAnalysis (EDA) MEV Over 25,000 MEV-related transactions have been executed through Curve.
it’s possible to build a robust image recognition algorithm with high accuracy. Who Can Benefit from the Visual Data? Submit Data. After ExploratoryDataAnalysis is completed, you can look at your data. Image recognition is one of the most relevant areas of machine learning.
METAR, Miami International Airport (KMIA) on March 9, 2024, at 15:00 UTC In the recently concluded data challenge hosted on Desights.ai , participants used exploratorydataanalysis (EDA) and advanced artificial intelligence (AI) techniques to enhance aviation weather forecasting accuracy.
First of all, HR needs to collect comprehensive data about an employee, such as education, salary, experience… We also need data from supervisors such as performance, relationships, promotions… After that, HR can use this information to predict employees’ tendency to leave and take preventive action. TRAIN ==Staying Rate: 83.87%Leaving
If your dataset is not in time order (time consistency is required for accurate Time Series projects), DataRobot can fix those gaps using the DataRobot Data Prep tool , a no-code tool that will get your data ready for Time Series forecasting. Prepare your data for Time Series Forecasting. Perform exploratorydataanalysis.
We use this extracted dataset for exploratorydataanalysis and feature engineering. You can choose to sample the data from Snowflake in the SageMaker Data Wrangler UI. Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs.
In the Kelp Wanted challenge, participants were called upon to develop algorithms to help map and monitor kelp forests. Winning algorithms will not only advance scientific understanding, but also equip kelp forest managers and policymakers with vital tools to safeguard these vulnerable and vital ecosystems.
Summary: In the tech landscape of 2024, the distinctions between Data Science and Machine Learning are pivotal. Data Science extracts insights, while Machine Learning focuses on self-learning algorithms. The collective strength of both forms the groundwork for AI and Data Science, propelling innovation.
For example, handling missing values, formatting data, and normalising data are all simplified through these libraries. ExploratoryDataAnalysisExploratoryDataAnalysis involves performing computations on data to understand its distribution and identify patterns.
By transitioning from computer science to data science, you can tap into a broader range of job opportunities and potentially increase your earning potential. Leveraging existing skills: Computer science provides a strong foundation in programming, algorithms, and problem-solving, which are highly valuable in data science.
It accomplishes this by finding new features, called principal components, that capture the most significant patterns in the data. These principal components are ordered by importance, with the first component explaining the most variance in the data. Visualize the data in the new feature space to gain insights.
With the emergence of data science and AI, clustering has allowed us to view data sets that are not easily detectable by the human eye. Thus, this type of task is very important for exploratorydataanalysis. 3 feature visual representation of a K-means Algorithm.
Introduction Clustering Clustering is a fundamental technique in the field of machine learning that aims to group similar data points together based on their inherent characteristics or properties. It is a form of unsupervised learning , which means it does not require labeled training data or predefined target variables.
Blind 75 LeetCode Questions - LeetCode Discuss Data Manipulation and Analysis Proficiency in working with data is crucial. This includes skills in data cleaning, preprocessing, transformation, and exploratorydataanalysis (EDA).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content