This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Research Data Scientist Description : Research Data Scientists are responsible for creating and testing experimental models and algorithms. Applied Machine Learning Scientist Description : Applied ML Scientists focus on translating algorithms into scalable, real-world applications.
Python, R, and SQL: These are the most popular programming languages for data science. Algorithms: Decision trees, random forests, logistic regression, and more are like different techniques a detective might use to solve a case. Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly.
The processes of SQL, Python scripts, and web scraping libraries such as BeautifulSoup or Scrapy are used for carrying out the data collection. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and big data frameworks (Hadoop, Apache Spark).
Data Science intertwines statistics, problem-solving, and programming to extract valuable insights from vast data sets. This discipline takes raw data, deciphers it, and turns it into a digestible format using various tools and algorithms. Tools such as Python, R, and SQL help to manipulate and analyze data.
Python, R, and SQL: These are the most popular programming languages for data science. Algorithms: Decision trees, random forests, logistic regression, and more are like different techniques a detective might use to solve a case. Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is Apache Hadoop? What is Apache Spark?
Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions. Big Data technologies include Hadoop, Spark, and NoSQL databases. Database Knowledge: Like SQL for retrieving data. Machine Learning: Understanding and applying various algorithms.
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Machine learning algorithms play a central role in building predictive models and enabling systems to learn from data. Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently.
Concepts such as linear algebra, calculus, probability, and statistical theory are the backbone of many data science algorithms and techniques. Coding skills are essential for tasks such as data cleaning, analysis, visualization, and implementing machine learning algorithms. Specializing can make you stand out from other candidates.
Different algorithms and techniques are employed to achieve eventual consistency. Hadoop Distributed File System (HDFS) : HDFS is a distributed file system designed to store vast amounts of data across multiple nodes in a Hadoop cluster. They use redundancy and replication to ensure data availability.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
This will enable you to leverage the right algorithms to create good, well structured, and performing software. As such, you should begin by learning the basics of SQL. SQL is an established language used widely in data engineering. Just like programming, SQL has multiple dialects.
Enrolling in a Data Science course keeps you updated on the latest advancements, such as machine learning algorithms and data visualisation techniques. Students learn to work with tools like Python, R, SQL, and machine learning frameworks, which are essential for analysing complex datasets and deriving actionable insights1.
Data scientists are the bridge between programming and algorithmic thinking. The power of data science comes from a deep understanding of statistics,algorithms, programming, and communication skills. Hadoop, SQL, Python, R, Excel are some of the tools you’ll need to be familiar using. Data Scientists.
Many functions of data analytics—such as making predictions—are built on machine learning algorithms and models that are developed by data scientists. And you should have experience working with big data platforms such as Hadoop or Apache Spark. Those who work in the field of data science are known as data scientists.
Familiarise yourself with essential tools like Hadoop and Spark. What are the Main Components of Hadoop? Hadoop consists of the Hadoop Distributed File System (HDFS) for storage and MapReduce for processing data across distributed systems. What is the Role of a NameNode in Hadoop ? What is a DataNode in Hadoop?
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. ETL Tools: Apache NiFi, Talend, etc.
Machine Learning Engineer Machine Learning Engineers develop algorithms and models that enable machines to learn from data. Strong understanding of data preprocessing and algorithm development. Proficiency in programming languages like Python and SQL. They explore new algorithms and techniques to improve machine learning models.
This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. This allowed them to focus on SQL-based query optimization to the nth degree. What is Presto? It also provides features like indexing and caching.”
SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. While it may not be a traditional programming language, SQL plays a crucial role in Data Science by enabling efficient querying and extraction of data from databases.
These skills encompass proficiency in programming languages, data manipulation, and applying Machine Learning Algorithms , all essential for extracting meaningful insights and making data-driven decisions. Programming Languages (Python, R, SQL) Proficiency in programming languages is crucial.
Familiarity with libraries like pandas, NumPy, and SQL for data handling is important. This includes skills in data cleaning, preprocessing, transformation, and exploratory data analysis (EDA). Additionally, knowledge of model evaluation, hyperparameter tuning, and model selection is valuable.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. It is built on the Hadoop Distributed File System (HDFS) and utilises MapReduce for data processing. Once data is collected, it needs to be stored efficiently.
Machine learning works on a known problem with tools and techniques, creating algorithms that let a machine learn from data through experience and with minimal human intervention. It’s unnecessary to know SQL, as programs are written in R, Java, SAS and other programming languages.
data visualization tools, machine learning algorithms, and statistical models to uncover valuable information hidden within data. Finance: In the financial sector, data science is used for fraud detection, risk assessment, algorithmic trading, and personalized financial advice.
In-depth knowledge of distributed systems like Hadoop and Spart, along with computing platforms like Azure and AWS. Having a solid understanding of ML principles and practical knowledge of statistics, algorithms, and mathematics. Hands-on experience working with SQLDW and SQL-DB. Knowledge in using Azure Data Factory Volume.
Further, Data Scientists are also responsible for using machine learning algorithms to identify patterns and trends, make predictions, and solve business problems. Effectively, Data Analysts use other tools like SQL, R or Python, Excel, etc., Effectively, they analyse, interpret, and model complex data sets.
Knowledge of Core Data Engineering Concepts Ensure one possess a strong foundation in core data engineering concepts, which include data structures, algorithms, database management systems, data modeling , data warehousing , ETL (Extract, Transform, Load) processes, and distributed computing frameworks (e.g., Hadoop, Spark).
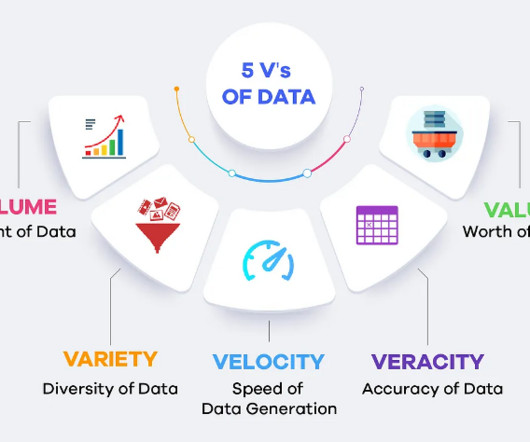
Advances in big data technology like Hadoop, Hive, Spark and Machine Learning algorithms have made it possible to interpret and utilize this variety of data effectively. Examples include Excel files, SQL databases, and data warehouses. Variety Data comes in a myriad of formats including text, images, videos, and more.
The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and Big Data technologies. Issues such as algorithmic bias, data privacy, and transparency are becoming critical topics of discussion within the industry.
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and soon. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
Computer Science A computer science background equips you with programming expertise, knowledge of algorithms and data structures, and the ability to design and implement software solutions – all valuable assets for manipulating and analyzing data. Databases and SQL Data doesn’t exist in a vacuum.
Data science is an interdisciplinary field that combines scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. They employ advanced statistical modeling techniques, machine learning algorithms, and data visualization tools to derive meaningful insights.
Here is the tabular representation of the same: Technical Skills Non-technical Skills Programming Languages: Python, SQL, R Good written and oral communication Data Analysis: Pandas, Matplotlib, Numpy, Seaborn Ability to work in a team ML Algorithms: Regression Classification, Decision Trees, Regression Analysis Problem-solving capability Big Data: (..)
Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as Power BI and Tableau as well. Like their counterparts in the machine learning world, engineers need to know a variety of scripted languages such as SQL for database management, Scala, Java, and of course Python.
The company employs advanced algorithms and BI tools to analyse vast amounts of data generated from user interactions across its platforms. By consolidating data from over 10,000 locations and multiple websites into a single Hadoop cluster, Walmart can analyse customer purchasing trends and optimize inventory management.
Database Extraction: Retrieval from structured databases using query languages like SQL. However, inefficient data processing algorithms and network congestion can introduce significant delays. API Integration: Accessing data through Application Programming Interfaces (APIs) provided by external services.
Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decision trees, and support vector machines. To obtain practical expertise, run the algorithms on datasets. You should be skilled in using a variety of tools including SQL and Python libraries like Pandas.
Predictive Analytics: Forecasting future outcomes based on historical data and statistical algorithms. SQL (Structured Query Language): Language for managing and querying relational databases. Hadoop/Spark: Frameworks for distributed storage and processing of big data.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. This text has a lot of information, but it is not structured.
These tools leverage advanced algorithms and methodologies to process large datasets, uncovering valuable insights that can drive strategic decision-making. Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently.
Predictive analytics utilizes statistical algorithms and machine learning to forecast future outcomes based on historical data. Additionally, biases in algorithms can lead to skewed results, highlighting the need for careful data validation. Roles of data professionals Various professionals contribute to the data science ecosystem.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content