This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction This article concerns one of the supervised ML classification algorithm-KNN(K. The post A Quick Introduction to K – NearestNeighbor (KNN) Classification Using Python appeared first on Analytics Vidhya. ArticleVideos This article was published as a part of the Data Science Blogathon.
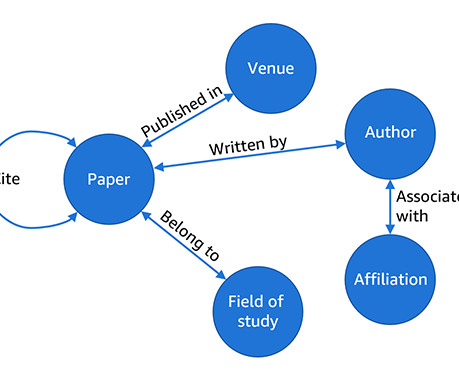
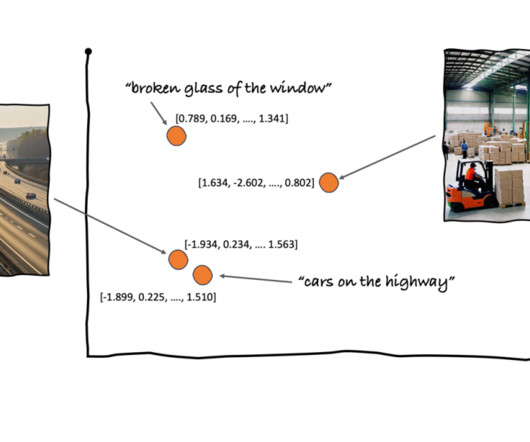
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. These algorithms are integral to applications like recommendations and spam detection, shaping our interactions with technology daily. These intelligent predictions are powered by various Machine Learning algorithms.
Let’s discuss two popular MLalgorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both MLAlgorithms, and we’ll explore them more in detail in a bit. They are both MLAlgorithms, and we’ll explore them more in detail in a bit.
The K-NearestNeighborsAlgorithm Math Foundations: Hyperplanes, Voronoi Diagrams and Spacial Metrics. Throughout this article we’ll dissect the math behind one of the most famous, simple and old algorithms in all statistics and machine learning history: the KNN. Photo by Who’s Denilo ? Photo from here 2.1
improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases.
We shall look at various machine learning algorithms such as decision trees, random forest, Knearestneighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. I wrote about Python ML here. Join thousands of data leaders on the AI newsletter.
Summary: The KNN algorithm in machine learning presents advantages, like simplicity and versatility, and challenges, including computational burden and interpretability issues. Unlocking the Power of KNN Algorithm in Machine Learning Machine learning algorithms are significantly impacting diverse fields.
Created by the author with DALL E-3 Statistics, regression model, algorithm validation, Random Forest, KNearestNeighbors and Naïve Bayes— what in God’s name do all these complicated concepts have to do with you as a simple GIS analyst? For example, it takes millions of images and runs them through a training algorithm.
Created by the author with DALL E-3 Machine learning algorithms are the “cool kids” of the tech industry; everyone is talking about them as if they were the newest, greatest meme. Shall we unravel the true meaning of machine learning algorithms and their practicability?
The goal is to index these five webpages dynamically using a common embedding algorithm and then use a retrieval (and reranking) strategy to retrieve chunks of data from the indexed knowledge base to infer the final answer. Dr. Hemant Joshi has over 20 years of industry experience building products and services with AI/ML technologies.
a low-code enterprise graph machine learning (ML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. With GraphStorm, we release the tools that Amazon uses internally to bring large-scale graph ML solutions to production. license on GitHub. GraphStorm 0.1
Previously, OfferUps search engine was built with Elasticsearch (v7.10) on Amazon Elastic Compute Cloud (Amazon EC2), using a keyword search algorithm to find relevant listings. The search microservice processes the query requests and retrieves relevant listings from Elasticsearch using keyword search (BM25 as a ranking algorithm).
To search against the database, you can use a vector search, which is performed using the k-nearestneighbors (k-NN) algorithm. He is particularly passionate about AI/ML and enjoys building proof-of-concept solutions for his customers.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
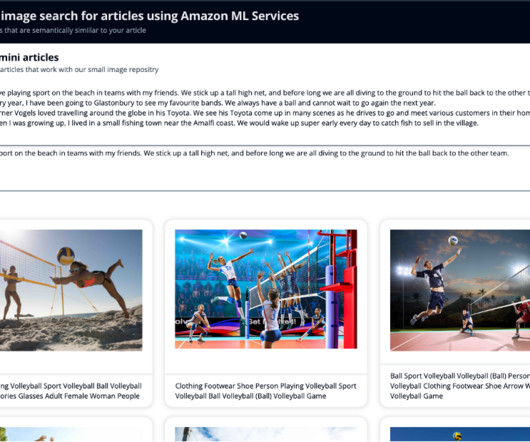
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
However, with a wide range of algorithms available, it can be challenging to decide which one to use for a particular dataset. ⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ?
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. For the classfier, we employed a classic MLalgorithm, k-NN, using the scikit-learn Python module.
How to Use Machine Learning (ML) for Time Series Forecasting — NIX United The modern market pace calls for a respective competitive edge. ML-based predictive models nowadays may consider time-dependent components — seasonality, trends, cycles, irregular components, etc. — to
MLalgorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning. Strictly, everything that I said earlier is based on Machine learning algorithms and, of course, strong math and theory of algorithms behind them. The most commonly used algorithms are Apriori and Eclat.
Kinesis Video Streams makes it straightforward to securely stream video from connected devices to AWS for analytics, machine learning (ML), playback, and other processing. Determining the optimal value of K in the k-NN algorithm for vector similarity search is significant for balancing accuracy, performance, and cost.
The Multi-Armed Bandit (MAB) algorithm is a type of reinforcement learning algorithm that addresses the trade-off between exploration and exploitation in decision-making. In the context of the MAB algorithm, each arm represents a decision that can be taken, and the reward corresponds to some measure of performance or utility.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. What is Unsupervised Machine Learning?
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. As per the AI/ML flywheel, what do the AWS AI/ML services provide? Based on the summary, the AWS AI/ML services provide a range of capabilities that fuel an AI/ML flywheel.
Among the multitude of techniques available to enhance the efficacy of Machine Learning algorithms, feature scaling stands out as a fundamental process. This feature equality fosters an environment where the algorithm can discern patterns and relationships accurately across all dimensions of the data.
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
Introduction In the world of machine learning, where algorithms learn from data to make predictions, it’s important to get the best out of our models. Steps to Perform Hyperparameter Tuning Hyperparameter Tuning process (Image by author) Select Hyperparameters to Tune: Different algorithms have different hyperparameters.
The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. Often, it requires you to co-design the algorithm and also the system set. If they’re necessary, how can we create a new algorithm to accommodate it? A transcript of the talk follows.
The talk explored Zhang’s work on how debugging data can lead to more accurate and more fair ML applications. Often, it requires you to co-design the algorithm and also the system set. If they’re necessary, how can we create a new algorithm to accommodate it? A transcript of the talk follows.
Through a collaboration between the Next Gen Stats team and the Amazon ML Solutions Lab , we have developed the machine learning (ML)-powered stat of coverage classification that accurately identifies the defense coverage scheme based on the player tracking data. In this post, we deep dive into the technical details of this ML model.
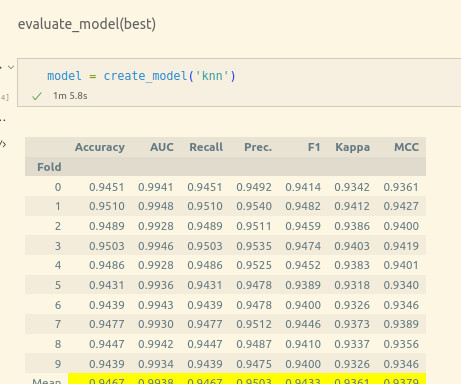
By leveraging pyCaret’s rich collection of classification algorithms, including support vector machines, random forests, and gradient boosting, we can train and compare multiple models to identify the most accurate and reliable approach for predicting race from tweets.
Effective recommendations that present students with relevant reading material helps keep students reading, and this is where machine learning (ML) can help. ML has been widely used in building recommender systems for various types of digital content, ranging from videos to books to e-commerce items.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. The following is a transcript of his presentation, edited lightly for readability. I’m super excited to chat with you all today.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. The following is a transcript of his presentation, edited lightly for readability. I’m super excited to chat with you all today.
I’m Cody Coleman and I’m really excited to share my research on how careful data selection can make ML development faster, cheaper, and better by focusing on quality rather than quantity. The following is a transcript of his presentation, edited lightly for readability. I’m super excited to chat with you all today.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
Scikit-learn A machine learning powerhouse, Scikit-learn provides a vast collection of algorithms and tools, making it a go-to library for many data scientists. PyTorch This essential library is an open-source ML framework capable of speeding up research prototyping, allowing companies to enter the production deployment phase.
On the other hand, 48% use ML and AI for gaining insights into the prospects and customers. The specific techniques and algorithms used can vary based on the nature of the data and the problem at hand. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm.
For each sample in the minority class, it selects knearestneighbors from the same class. It then selects one of these kneighbors at random and computes the difference between the feature vector of the original sample and the selected neighbor.
find_similar_items performs semantic search using the k-nearestneighbors (kNN) algorithm on the input image prompt. Bishesh Adhikari , is a Senior ML Prototyping Architect at AWS with over a decade of experience in software engineering and AI/ML.
Source code projects provide valuable hands-on experience and allow you to understand the intricacies of machine learning algorithms, data preprocessing, model training, and evaluation. Wine Quality Prediction In this blog, we will build a simple Wine Quality Prediction model using the Random Forest algorithm.
HOGs are great feature detectors and can also be used for object detection with SVM but due to many other State of the Art object detection algorithms like YOLO, and SSD , present out there, we don’t use HOGs much for object detection. Checkout the code walkthrough [link] 13. Checkout the code walkthrough [link] 18. This is a simple project.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content