This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. These algorithms use existing data like text, images, and audio to generate content that looks like it comes from the real world.
In vec t o r d a ta b a s e s , this process of querying is more optimized and efficient with the use of a sim i l a r i ty metric for searching the most sim i l a r vec t o r to our query. This may involve techniques like naturallanguageprocessing for medical records or dimensionality reduction for complex biomolecular data.
adults use only work when they can turn audio data into words, and then apply naturallanguageprocessing (NLP) to understand it. Choose an Appropriate Algorithm As with all machine learning processes, algorithm selection is also crucial. The voice assistants that 62% of U.S.
Each type and sub-type of ML algorithm has unique benefits and capabilities that teams can leverage for different tasks. Instead of using explicit instructions for performance optimization, ML models rely on algorithms and statistical models that deploy tasks based on data patterns and inferences. What is machine learning?
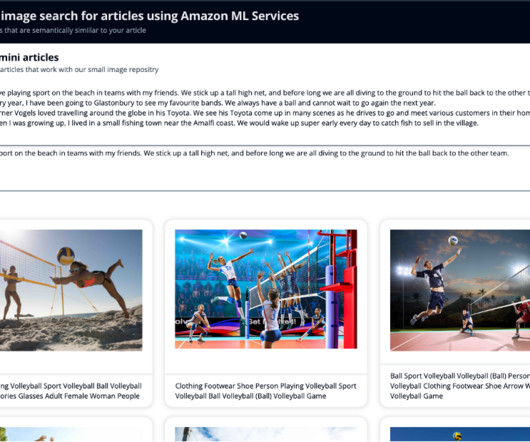
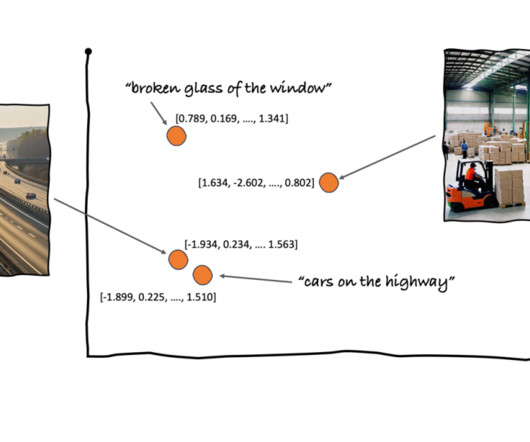
You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results. For this example, we use cosine similarity.
Model invocation We use Anthropics Claude 3 Sonnet model for the naturallanguageprocessing task. This LLM model has a context window of 200,000 tokens, enabling it to manage different languages and retrieve highly accurate answers. temperature This parameter controls the randomness of the language models output.
Machine Learning is a subset of artificial intelligence (AI) that focuses on developing models and algorithms that train the machine to think and work like a human. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. What is Unsupervised Machine Learning?
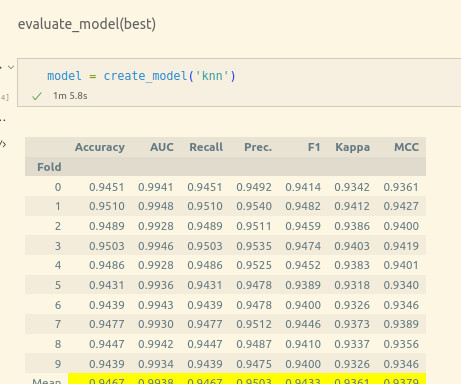
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. K-nearestNeighbors For both regression and classification tasks, the K-nearestNeighbors (kNN) model provides a straightforward supervised ML solution.
These vectors are typically generated by machine learning models and enable fast similarity searches that power AI-driven applications like recommendation engines, image recognition, and naturallanguageprocessing. How is it Different from Traditional Databases? 💡 Why?
This retrieval can happen using different algorithms. Formally, often k-nearestneighbors (KNN) or approximate nearestneighbor (ANN) search is often used to find other snippets with similar semantics. Her research interests lie in NaturalLanguageProcessing, AI4Code and generative AI.
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of NaturalLanguageProcessing (NLP), machine learning, and sociolinguistics.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). The following diagram visualizes the semantic search with naturallanguageprocessing (NLP).
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. The summary describes an image related to the progression of naturallanguageprocessing and generative AI technologies, but it does not mention anything about particle physics or the concept of quarks.
Types of inductive bias include prior knowledge, algorithmic bias, and data bias. Types of Inductive Bias Inductive bias plays a significant role in shaping how Machine Learning algorithms learn and generalise. This bias allows algorithms to make informed guesses when faced with incomplete or sparse data.
Introduction In naturallanguageprocessing, text categorization tasks are common (NLP). Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. For many classification applications, random forest is now one of the best-performing algorithms.
Key steps involve problem definition, data preparation, and algorithm selection. It involves algorithms that identify and use data patterns to make predictions or decisions based on new, unseen data. Types of Machine Learning Machine Learning algorithms can be categorised based on how they learn and the data type they use.
A Algorithm: A set of rules or instructions for solving a problem or performing a task, often used in data processing and analysis. Decision Trees: A supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks.
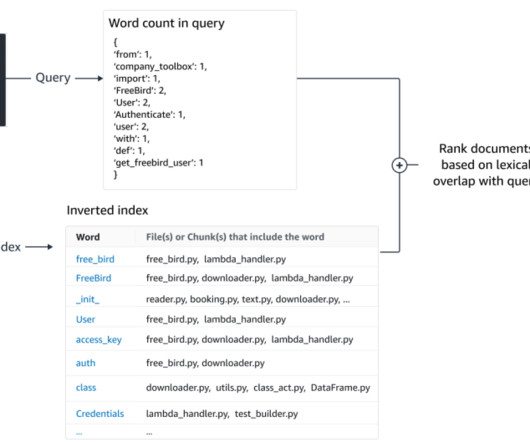
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-NearestNeighbor (k-NN) search in Amazon OpenSearch Service ), among others.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters. The results show that most of them were indeed labeled incorrectly.
Transformer Models: Originally designed for naturallanguageprocessing, transformers have been adapted to vision transformers (ViT) and are now used for image analysis. In which a machine learning algorithm is trained with a small dataset, in this case made of embeddings.
HOGs are great feature detectors and can also be used for object detection with SVM but due to many other State of the Art object detection algorithms like YOLO, SSD, present out there, we don’t use HOGs much for object detection. This is a simple project. I have used Boston Housing Data for this use case.
Gender Bias in NaturalLanguageProcessing (NLP) NLP models can develop biases based on the data they are trained on. K-NearestNeighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance.
For instance, given a certain sample if the active learning algorithm is uncertain about the correct response it can send the sample to the human annotator. Key Characteristics Synthetic Data Generation : Query synthesis algorithms actively generate new training examples rather than selecting from an existing pool.
These vectors encapsulate essential characteristics of data, enabling algorithms to learn patterns and make predictions effectively. Understanding feature vectors is key to grasping how diverse fields like image processing and text classification leverage data for insightful analyses.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content