This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Understanding Naïve Bayes and SupportVectorMachine and their implementation in Python appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon. Introduction In this digital world, spam is the most troublesome challenge that.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, we will be discussing SupportVectorMachines. The post SupportVectorMachine: Introduction appeared first on Analytics Vidhya.
Ever wondered, how great would it be, if we could predict, whether our request for a loan, will be approved or not, simply by the use of machine learning, from the ease and comfort […]. The post Loan Status Prediction using SupportVectorMachine (SVM) Algorithm appeared first on Analytics Vidhya.
The post Start Learning SVM (SupportVectorMachine) Algorithm Here! ArticleVideo Book This article was published as a part of the Data Science Blogathon Source Overview In this article, we will learn the working of. appeared first on Analytics Vidhya.
Introduction Classification problems are often solved using supervised learning algorithms such as Random Forest Classifier, SupportVectorMachine, Logistic Regressor (for binary class classification) etc. The post One Class Classification Using SupportVectorMachines appeared first on Analytics Vidhya.
Unlocking a New World with the SupportVector Regression AlgorithmSupportVectorMachines (SVM) are popularly and widely used for classification problems in machine. The post SupportVector Regression Tutorial for Machine Learning appeared first on Analytics Vidhya.
At the heart of this discipline lie four key building blocks that form the foundation for effective data science: statistics, Python programming, models, and domain knowledge. Some of the most popular Python libraries for data science include: NumPy is a library for numerical computation. SciPy is a library for scientific computing.
These features can be used to improve the performance of Machine Learning Algorithms. Python, with its extensive libraries and tools, offers a streamlined and efficient process for simplifying feature scaling. Feature Engineering is a process of using domain knowledge to extract and transform features from raw data.
We shall look at various machine learning algorithms such as decision trees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. In addition, it’s also adapted to many other programming languages, such as Python or SQL.
Popular tools for implementing it include WEKA, RapidMiner, and Python libraries like mlxtend. For instance, a classification algorithm could predict whether a transaction is fraudulent or not based on various features. Key applications include fraud detection, customer segmentation, and medical diagnosis.
Some popular data mining tools include R, Python, and Weka. Selecting the right algorithm There are several data mining algorithms available, each with its strengths and weaknesses. In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering.
The articles cover a range of topics, from the basics of Rust to more advanced machine learning concepts, and provide practical examples to help readers get started with implementing ML algorithms in Rust. Rust has several libraries and frameworks for machine learning, lets talk about a few of them!
Summary: SupportVectorMachine (SVM) is a supervised Machine Learning algorithm used for classification and regression tasks. Among the many algorithms, the SVM algorithm in Machine Learning stands out for its accuracy and effectiveness in classification tasks.
The field of data science changes constantly, and some frameworks, tools, and algorithms just can’t get the job done anymore. Machine Learning for Beginners Learn the essentials of machine learning including how SupportVectorMachines, Naive Bayesian Classifiers, and Upper Confidence Bound algorithms work.
A generative AI company exemplifies this by offering solutions that enable businesses to streamline operations, personalise customer experiences, and optimise workflows through advanced algorithms. Data forms the backbone of AI systems, feeding into the core input for machine learning algorithms to generate their predictions and insights.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Introduction Artificial Intelligence (AI) transforms industries by enabling machines to mimic human intelligence.
Machine learning for text extraction with Python is one of the best combos out there for this task. In this blog post, we’ll talk about how one can use Machine learning and Python to perform text extraction with the highest level of accuracy. Pandas – This works best for model evaluation and machine learning algorithms.
This article will explain the concept of hyperparameter tuning and the different methods that are used to perform this tuning, and their implementation using python Photo by Denisse Leon on Unsplash Table of Content Model Parameters Vs Model Hyperparameters What is hyperparameter tuning? What is hyperparameter tuning?
The main focus of this blog is to explore a range of statistical and machine learning methods that can be utilized for detecting anomalies in data. Our approach will emphasize on providing illustrative Python code to effectively demonstrate each of these methods. quantile(0.25) Q3 = data['value'].quantile(0.75)
In this article, we will explore the concept of applied text mining in Python and how to do text mining in Python. Introduction to Applied Text Mining in Python Before going ahead, it is important to understand, What is Text Mining in Python? How To Do Text Mining in Python?
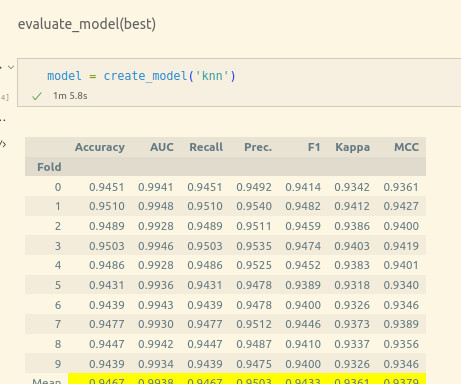
Libraries The programming language used in this code is Python, complemented by the LangChain module, which is specifically designed to facilitate the integration and use of LLMs. For the classfier, we employed a classic ML algorithm, k-NN, using the scikit-learn Python module. This method takes a parameter, which we set to 3.
Python is still one of the most popular programming languages that developers flock to. In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick.
Python is one of the widely used programming languages in the world having its own significance and benefits. Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science. Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you.
This type of machine learning is useful in known outlier detection but is not capable of discovering unknown anomalies or predicting future issues. Local outlier factor (LOF ): Local outlier factor is similar to KNN in that it is a density-based algorithm.
Among the multitude of techniques available to enhance the efficacy of Machine Learning algorithms, feature scaling stands out as a fundamental process. Understanding Feature Scaling in Machine Learning: Feature scaling stands out as a fundamental process.
Text categorization is supported by a number of programming languages, including R, Python, and Weka, but the main focus of this article will be text classification with R. The e1071 package provides a suite of statistical classification functions, including supportvectormachines (SVMs), which are commonly used for spam detection.
Algorithms: AI algorithms are used to process the data and extract insights from it. There are several types of AI algorithms, including supervised learning, unsupervised learning, and reinforcement learning. Develop AI models using machine learning or deep learning algorithms.
Photo by Shahadat Rahman on Unsplash Introduction Machine learning (ML) focuses on developing algorithms and models that can learn from data and make predictions or decisions. In the same way, ML algorithms can be trained on large datasets to learn patterns and make predictions based on that data.
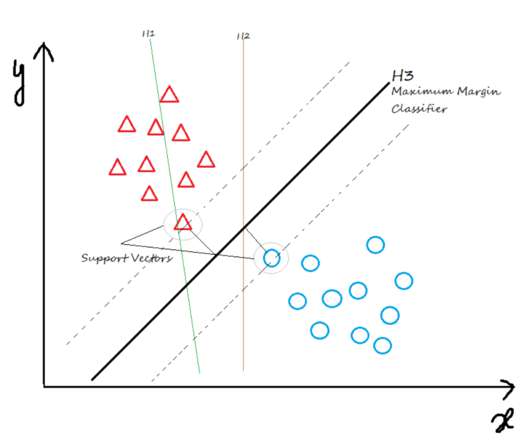
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Machine learning algorithms rely on mathematical functions called “kernels” to make predictions based on input data.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Key programming languages include Python and R, while mathematical concepts like linear algebra and calculus are crucial for model optimisation. during the forecast period.
Covering a comprehensive range of topics, the course provides a deep dive into the fundamental principles and practical applications of machine learning algorithms. This professional certificate provides a holistic approach to machine learning, combining theoretical knowledge with practical skills.
Technical Proficiency Data Science interviews typically evaluate candidates on a myriad of technical skills spanning programming languages, statistical analysis, Machine Learning algorithms, and data manipulation techniques. Differentiate between supervised and unsupervised learning algorithms.
The following blog will provide you a thorough evaluation on how Anomaly Detection Machine Learning works, emphasising on its types and techniques. Further, it will provide a step-by-step guide on anomaly detection Machine Learning python. Key Takeaways: As of 2021, the market size of Machine Learning was USD 25.58
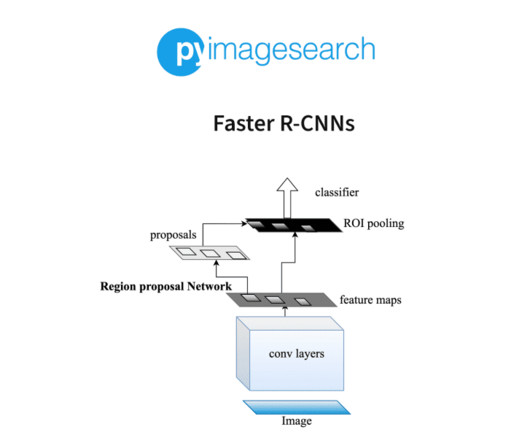
One of the most popular deep learning-based object detection algorithms is the family of R-CNN algorithms, originally introduced by Girshick et al. Since then, the R-CNN algorithm has gone through numerous iterations, improving the algorithm with each new publication and outperforming traditional object detection algorithms (e.g.,
Just as humans can learn through experience rather than merely following instructions, machines can learn by applying tools to data analysis. Machine learning works on a known problem with tools and techniques, creating algorithms that let a machine learn from data through experience and with minimal human intervention.
Using LLMs Use vs build ($) — Pretrained Vs Train Vs Finetune LLMs Pretraining vs Fine-tuning vs In-context Learning of LLM (GPT-x) EXPLAINED | Ultimate Guide ($) — YouTube Using 3rd party models Proprietary -OpenAI Getting Started with OpenAI API and GPT-3 | Beginner Python Tutorial — YouTube Introduction — OpenAI API Open Source ?
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of Natural Language Processing (NLP), machine learning, and sociolinguistics. With the preprocessed data in hand, we can now employ pyCaret, a powerful machine learning library, to build our predictive models.
Summary: In the tech landscape of 2024, the distinctions between Data Science and Machine Learning are pivotal. Data Science extracts insights, while Machine Learning focuses on self-learning algorithms. Markets for each field are booming, offering diverse job roles, especially in Machine Learning for Data Analytics.
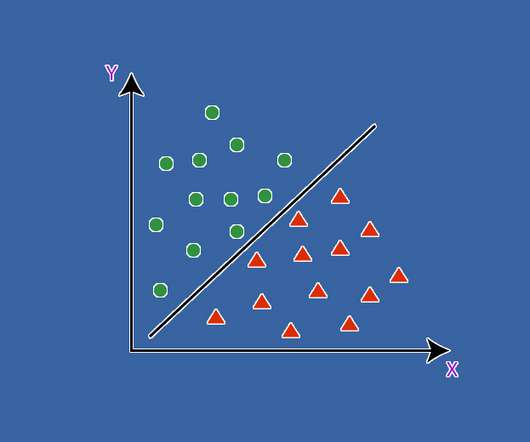
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. SupportVectorMachines In order to classify data more precisely, supportvectormachine methods create a partition (a hyperplane).
Artificial Intelligence (AI) models are the building blocks of modern machine learning algorithms that enable machines to learn and perform complex tasks. SupportVectorMachines In order to classify data more precisely, supportvectormachine methods create a partition (a hyperplane).
Key Takeaways Machine Learning Models are vital for modern technology applications. Key steps involve problem definition, data preparation, and algorithm selection. Ethical considerations are crucial in developing fair Machine Learning solutions. Let’s break down the key components and types of Machine Learning.
Understanding Data Science Data Science is a multidisciplinary field that uses scientific methods, algorithms, and systems to extract knowledge and insights from structured and unstructured data. Finance In finance, Data Science is critical in fraud detection, risk management, and algorithmic trading.
Just as a writer needs to know core skills like sentence structure and grammar, data scientists at all levels should know core data science skills like programming, computer science, algorithms, and soon. While knowing Python, R, and SQL is expected, youll need to go beyond that. Employers arent just looking for people who can program.
As it pertains to social media data, text mining algorithms (and by extension, text analysis) allow businesses to extract, analyze and interpret linguistic data from comments, posts, customer reviews and other text on social media platforms and leverage those data sources to improve products, services and processes.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content