This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction YARN stands for Yet Another Resource Negotiator, a large-scale distributed data operating system used for BigDataAnalytics. The post The Tale of ApacheHadoop YARN! appeared first on Analytics Vidhya. Apart from resource management, […].
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process bigdata. It is a core component of the ApacheHadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers.
In today’s world, data is being generated at an ever-growing pace, leading to a boom in demand for BigData tools such as Hadoop, Pig, Spark, Hive, and many more. The tool that stands out the most is ApacheHadoop, and one of its core components is YARN. ApacheHadoop YARN, or as it is […].
This article was published as a part of the Data Science Blogathon. Introduction MapReduce is part of the ApacheHadoop ecosystem, a framework that develops large-scale data processing. Other components of ApacheHadoop include Hadoop Distributed File System (HDFS), Yarn, and Apache Pig.
Every time you put on a dog filter, watch cat videos or order food from your favourite restaurant, you generate data. Imagine how much data millions of other people are doing the […]. The post An Introduction to Hadoop Ecosystem for BigData appeared first on Analytics Vidhya.
Introduction ApacheHadoop is an open-source framework designed to facilitate interaction with bigdata. Still, for those unfamiliar with this technology, one question arises, what is bigdata? Bigdata is a term for data sets that cannot be efficiently processed using a traditional […].
Introduction Bigdata processing is crucial today. Bigdataanalytics and learning help corporations foresee client demands, provide useful recommendations, and more. Hadoop, the Open-Source Software Framework for scalable and scattered computation of massive data sets, makes it easy.
Recent technology advances within the ApacheHadoop ecosystem have provided a big boost to Hadoop’s viability as an analytics environment—above and beyond just being a good place to store data. The post 3 Reasons Why In-HadoopAnalytics are a Big Deal appeared first on Dataconomy.
Google BigQuery: Google BigQuery is a serverless, cloud-based data warehouse designed for bigdataanalytics. It offers scalable storage and compute resources, enabling data engineers to process large datasets efficiently. It provides a scalable and fault-tolerant ecosystem for bigdata processing.
From the tech industry to retail and finance, bigdata is encompassing the world as we know it. More organizations rely on bigdata to help with decision making and to analyze and explore future trends. BigData Skillsets. They’re looking to hire experienced data analysts, data scientists and data engineers.
Hadoop has become synonymous with bigdata processing, transforming how organizations manage vast quantities of information. As businesses increasingly rely on data for decision-making, Hadoop’s open-source framework has emerged as a key player, offering a powerful solution for handling diverse and complex datasets.
Summary: Business Analytics focuses on interpreting historical data for strategic decisions, while Data Science emphasizes predictive modeling and AI. Introduction In today’s data-driven world, businesses increasingly rely on analytics and insights to drive decisions and gain a competitive edge.
What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. However, instead of using Hadoop, data lakes are increasingly being constructed using cloud object storage services. Which one is right for your business?
We’re well past the point of realization that bigdata and advanced analytics solutions are valuable — just about everyone knows this by now. Bigdata alone has become a modern staple of nearly every industry from retail to manufacturing, and for good reason.
It is designed to be more flexible and generic than the original Hadoop MapReduce system, making it an attractive choice for companies looking to implement Hadoop. It allows companies to process data types and run […] The post YARN for Large Scale Computing: Beginner’s Edition appeared first on Analytics Vidhya.
Introduction Impala is an open-source and native analytics database for Hadoop. The post What is Apache Impala- Features and Architecture appeared first on Analytics Vidhya. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. source: -[link] It rapidly processes large […].
HDFS and […] The post Top 10 Hadoop Interview Questions You Must Know appeared first on Analytics Vidhya. Still, it does include shell commands and Java Application Programming Interface (API) functions that are similar to other file systems.
Summary: This blog delves into the multifaceted world of BigData, covering its defining characteristics beyond the 5 V’s, essential technologies and tools for management, real-world applications across industries, challenges organisations face, and future trends shaping the landscape.
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdata pipeline.
Introduction YARN is an open-source project for Apache representing “Yet Another Resource Negotiator” Hadoop Collection Manager is responsible for sharing resources (such as CPU, memory, disk, and network), and organizing and monitoring tasks throughout the Hadoop collection.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData encompasses vast amounts of structured and unstructured data from various sources. Key components include data storage solutions, processing frameworks, analytics tools, and governance practices. Key Takeaways BigData originates from diverse sources, including IoT and social media.
Summary: BigData as a Service (BDaaS) offers organisations scalable, cost-effective solutions for managing and analysing vast data volumes. By outsourcing BigData functionalities, businesses can focus on deriving insights, improving decision-making, and driving innovation while overcoming infrastructure complexities.
ApacheHadoop needs no introduction when it comes to the management of large sophisticated storage spaces, but you probably wouldn’t think of it as the first solution to turn to when you want to run an email marketing campaign. Leveraging Hadoop’s Predictive Analytic Potential.
Regular audits, data validation, and cleansing processes can help companies confirm that data is reliable and actionable. Skills gap : These strategies rely on dataanalytics, artificial intelligence tools, and machine learning expertise. Unify Data Sources Collect data from multiple systems into one cohesive dataset.
Top 15 DataAnalytics Projects in 2023 for Beginners to Experienced Levels: DataAnalytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. These may range from DataAnalytics projects for beginners to experienced ones.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. What is ApacheHadoop?
Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation. With a user-friendly interface and robust features, NiFi simplifies complex data workflows and enhances real-time data integration.
Java: Scalability and Performance Java is renowned for its scalability and robustness, making it an excellent choice for handling large-scale data processing. With its powerful ecosystem and libraries like ApacheHadoop and Apache Spark, Java provides the tools necessary for distributed computing and parallel processing.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring data quality and integrity.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle BigData and perform effective data analysis and statistical modelling.
The message broker can then distribute the events to various subscribers such as data processing pipelines, machine learning models, and real-time analytics dashboards. Data processing pipelines can subscribe to specific events and perform various transformations such as data enrichment, aggregation, and filtering.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, Natural Language Processing , Statistics and Mathematics. It is critical for knowing how to work with huge data sets efficiently. Is Python Necessary in the data science field?
To combine the collected data, you can integrate different data producers into a data lake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the data lake.
Data Structuring: The output from web scraping is often organised into structured formats, making it easier to analyse and use. Structured data can be easily imported into databases or analytical tools. Use Cases for Web Scraping Web scraping is a powerful technique that extracts data from websites.
BigData tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. BigData wurde zum Business-Sprech der darauffolgenden Jahre. In der Parallelwelt der ITler wurde das Tool und Ökosystem ApacheHadoop quasi mit BigData beinahe synonym gesetzt.
DFS optimises data retrieval through caching mechanisms and load balancing across nodes, ensuring that AI applications can quickly access the latest information. This efficiency is crucial for applications like real-time analytics or recommendation systems.
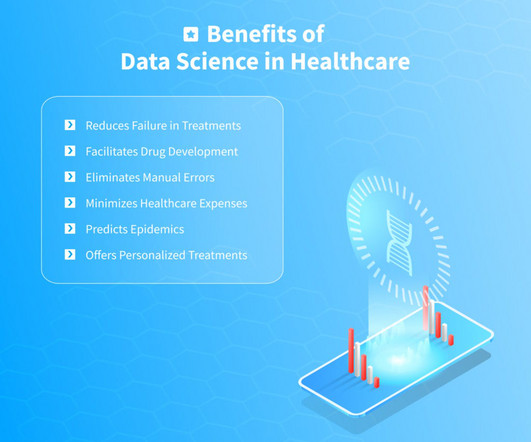
As a discipline that includes various technologies and techniques, data science can contribute to the development of new medications, prevention of diseases, diagnostics, and much more. Utilizing BigData, the Internet of Things, machine learning, artificial intelligence consulting , etc.,
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigDataanalytics provides a competitive advantage and drives innovation across various industries.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content