This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
That’s why you need to know about ApacheKafka, a publish-subscribe messaging system you can use to build distributed applications. The post ApacheKafka Architecture and Use Cases Explained appeared first on Analytics Vidhya. It is scalable and fault-tolerant, making […].
The post Handling Streaming Data with ApacheKafka – A First Look appeared first on Analytics Vidhya. Streaming Data is generated continuously, by multiple data sources say, sensors, server logs, stock prices, etc. These records are usually small and in the order […].
The post ApacheKafka Use Cases and Installation Guide appeared first on Analytics Vidhya. As applications cover more aspects of our daily lives, it is increasingly difficult to provide users with a quick response. Source: kafka.apache.org Caching is used to solve […].
Introduction Earlier, I had introduced basic concepts of ApacheKafka in my blog on Analytics Vidhya(link is available under references). This article introduced concepts involved in ApacheKafka and further built the understanding by using the python API of Kafka to write some […].
The post Introduction to ApacheKafka: Fundamentals and Working appeared first on Analytics Vidhya. Introduction Have you ever wondered how Instagram recommends similar kinds of reels while you are scrolling through your feed or ad recommendations for similar products that you were browsing on Amazon?
Introduction ApacheKafka is a framework for dealing with many real-time data streams in a way that is spread out. It was made on LinkedIn and shared with the public in 2011.
Introduction ApacheKafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
Overview Learn about viewing data as streams of immutable events in contrast to mutable containers Understand how ApacheKafka captures real-time data through event. The post ApacheKafka: A Metaphorical Introduction to Event Streaming for Data Scientists and Data Engineers appeared first on Analytics Vidhya.
Dale Carnegie” ApacheKafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime Data Pipeline appeared first on Analytics Vidhya. Only knowledge that is used sticks in your mind.- The Internet of Things(IoT) devices can generate a large […].
At the forefront of this event-driven revolution is ApacheKafka, the widely recognized and dominant open-source technology for event streaming. While most enterprises have already recognized how ApacheKafka provides a strong foundation for EDA, they often fall behind in unlocking its true potential.
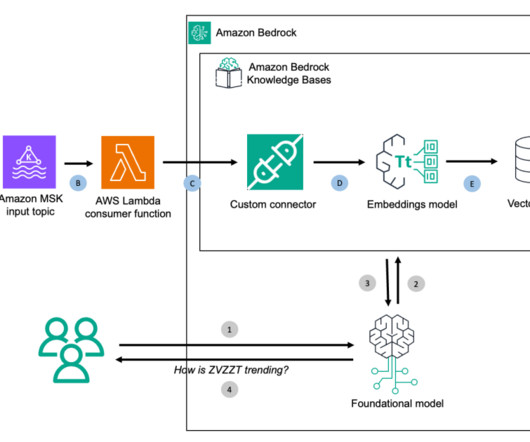
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
ApacheKafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with ApacheKafka: the de-facto enterprise standard for open-source event streaming. With ApacheKafka, you get a raw stream of events from everything that is happening within your business.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
The post 22 Widely Used Data Science and Machine Learning Tools in 2020 appeared first on Analytics Vidhya. Overview There are a plethora of data science tools out there – which one should you pick up? Here’s a list of over 20.
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Complex Event Processing (CEP) is at the forefront of modern analytics, enabling organizations to extract valuable insights from vast streams of real-time data. Real-time data management The importance of real-time data in todays analytics landscape cannot be overstated.
Users can add and manage new cameras, view footage, perform analytical searches, and enforce GDPR compliance with automatic person anonymization. It is backed by Amazon Managed Streaming for ApacheKafka (Amazon MSK) (8). The next important step is to use these model results with proper analytics and data science.
appeared first on Analytics Vidhya. Overview Know which are the top 9 skills required to be a data engineer Find suitable resources to learn about these tools By no. The post 9 Must-Have Skills to Become a Data Engineer!
Talks and insights Mikhail Epikhin: Navigating the processor landscape for ApacheKafka Mikhail Epikhin began the session by sharing his team’s research on optimizing Managed Service for ApacheKafka. His presentation focused on the performance and efficiency of different instance types and processor architectures.
Be sure to check out his talk, “ Building a Real-time Analytics Application for a Pizza Delivery Service ,” there! Gartner defines Real-Time Analytics as follows: Real-time analytics is the discipline that applies logic and mathematics to data to provide insights for making better decisions quickly.
Two of the most popular message brokers are RabbitMQ and ApacheKafka. In this blog, we will explore RabbitMQ vs Kafka, their key differences, and when to use each. Kafka excels in real-time data streaming and scalability. RabbitMQ uses a push-based model, while Kafka follows a pull-based model.
Ultimately, leveraging Big Data analytics provides a competitive advantage and drives innovation across various industries. Competitive Advantage Organisations that leverage Big Data Analytics can stay ahead of the competition by anticipating market trends and consumer preferences.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data. The global Big Data and data engineering market, valued at $75.55
Solution overview The Noodoe AI-enhanced diagnostics flow is built on a multi-step process that combines data collection, AI-powered analytics, and seamless translation for global accessibility, as illustrated in the following figure. Read on to discover how AI is transforming EV charging management.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics. Why Pursue Real-Time Analytics for Your Organization?
They often use ApacheKafka as an open technology and the de facto standard for accessing events from a various core systems and applications. IBM provides an Event Streams capability build on ApacheKafka that makes events manageable across an entire enterprise.
Confluent Confluent provides a robust data streaming platform built around ApacheKafka. empower teams to explore use cases in real-time analytics, personalized recommendations, and search. With AI credits, teams can streamline the annotation process using intelligent suggestions and quality control mechanisms.
Big Data Analytics stands apart from conventional data processing in its fundamental nature. It receives batch views from the batch layer and near-real-time views from the speed layer, utilizing this data to facilitate standard reporting and ad hoc analytics.
More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. It also allows for applications, analytics, and reporting to process information as it happens. One very popular platform is ApacheKafka , a powerful open-source tool used by thousands of companies.
Apache Flink takes raw events and processes them, making them more relevant in the broader business context. The unique advantages of Apache Flink Apache Flink augments event streaming technologies like ApacheKafka to enable businesses to respond to events more effectively in real time.
Apache Flink for stream processing: Wrapping up In conclusion, stream processing with distributed systems like ApacheKafka, Apache Flink, and Apache Spark Streaming empowers organizations to harness real-time data insights, enabling timely decision-making and enhanced user experiences.
After this, the data is analyzed, business logic is applied, and it is processed for further analytical tasks like visualization or machine learning. Data Ingestion: Data is collected and funneled into the pipeline using batch or real-time methods, leveraging tools like ApacheKafka, AWS Kinesis, or custom ETL scripts.
In this contributed article, Sijie Guo, Founder and CEO of Streamnative, believes that with remote work entrenched in the post-pandemic enterprise, organizations are restructuring their technology stack and software strategy for a new, distributed workforce.
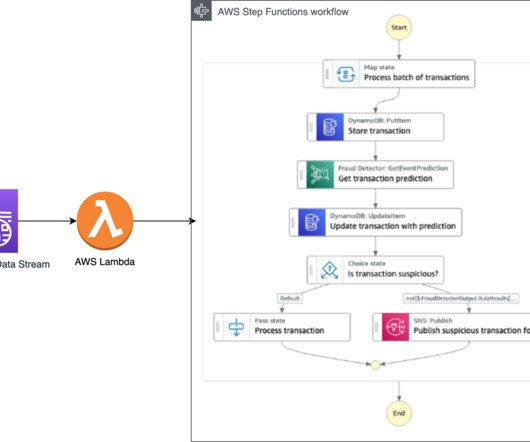
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
The same architecture applies if you use Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a data streaming service. You can use this metadata in your data analytics solutions, machine learning model training tasks, or visualizations and dashboards that consume transaction data. An example use case is claims processing.
The demand for instant results is not limited […] The post Architecting Real-Time Analytics for Speed and Scale appeared first on DATAVERSITY. If Netflix takes too long to load or the nearest Lyft is too far, users are quick to switch to alternative options.
Stream analytics can be used to help improve the speed and accuracy of models’ predictions. IBM Event Automation is a fully composable solution, built on open technologies, with capabilities for: Event streaming : Collect and distribute raw streams of real-time business events with enterprise-grade ApacheKafka.
In this contributed article, Sijie Guo, Founder and CEO of Streamnative, believes that with remote work entrenched in the post-pandemic enterprise, organizations are restructuring their technology stack and software strategy for a new, distributed workforce.
ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer. REGISTER NOW Data Orchestration and Workflow Management Apache Airflow Apache Airflow is renowned for its ability to build and schedule complex data pipelines.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. However, you might be looking for a guide to help you understand the different types of Data Analytics projects you may undertake.
As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions. Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content