This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
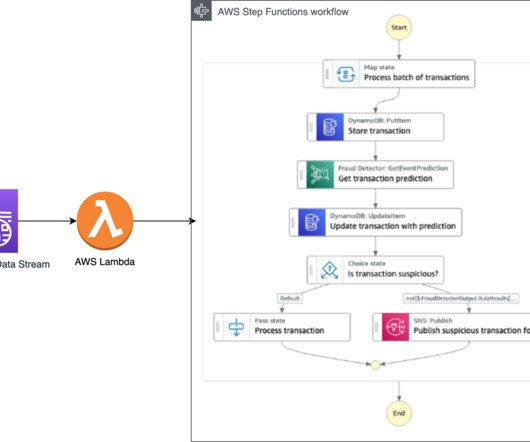
The same architecture applies if you use Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a data streaming service. You can use this metadata in your data analytics solutions, machine learning model training tasks, or visualizations and dashboards that consume transaction data. An example use case is claims processing.
Confluent Confluent provides a robust data streaming platform built around ApacheKafka. Amazon Web Services(AWS) AWS offers one of the most extensive AI and ML infrastructures in the world. Access Production-Grade Infrastructure Cloud providers such as AWS and Azure allow you to simulate real-world deployment scenarios.
In recent years, MathWorks has brought many product offerings into the cloud, especially on Amazon Web Services (AWS). Here is a quick guide on how to run MATLAB on AWS. Installation of AWS Command-Line Interface (AWS CLI) , AWS Configure , and Python3. Set up AWS Configure to interact with AWS resources.
Common examples of time series data include sales revenue, system performance data (such as CPU utilization and memory usage), credit card transactions, sensor readings, and user activity analytics. It offers an AWS CloudFormation template for straightforward deployment in an AWS account.
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). We’ve implemented an AWS Lambda function with the specific task of retrieving the calculated shot speed from the relevant Kafka topic.
Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS). It provides fault tolerance and high throughput for Big Data storage and processing. It allows organizations to store and retrieve any amount of data, making it popular for storing and managing Big Data in the cloud.
After this, the data is analyzed, business logic is applied, and it is processed for further analytical tasks like visualization or machine learning. Data Ingestion: Data is collected and funneled into the pipeline using batch or real-time methods, leveraging tools like ApacheKafka, AWS Kinesis, or custom ETL scripts.
TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting. TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations.
ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer. REGISTER NOW Data Orchestration and Workflow Management Apache Airflow Apache Airflow is renowned for its ability to build and schedule complex data pipelines.
As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions. It utilises Amazon Web Services (AWS) as its main data lake, processing over 550 billion events daily—equivalent to approximately 1.3 petabytes of data.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. However, you might be looking for a guide to help you understand the different types of Data Analytics projects you may undertake.
This is essential for applications that demand immediate insights, such as fraud detection or real-time analytics. By centralising data from disparate sources, organisations can ensure that they have a unified view of their information, which is vital for analytics, reporting, and decision-making.
Summary: The future of Data Science is shaped by emerging trends such as advanced AI and Machine Learning, augmented analytics, and automated processes. Data privacy regulations will shape how organisations handle sensitive information in analytics. Continuous learning and adaptation will be essential for data professionals.
It involves developing data pipelines that efficiently transport data from various sources to storage solutions and analytical tools. OLAP (Online Analytical Processing): OLAP tools allow users to analyse data from multiple perspectives. ETL is vital for ensuring data quality and integrity.
A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Tools and Techniques to Manage Unstructured Data Several tools are required to properly manage unstructured data, from storage to analytical tools. You also need the right technique to help manage unstructured data.
Data Consumption : You have reached a point where the data is ready for consumption for AI, BI & other analytics. Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a data lake. The origins of a data pipeline connect it to the need for reusability and efficiency.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., As usage increased, the system had to be scaled vertically, approaching AWS instance-type limits. Today different stages exist within ML pipelines built to meet technical, industrial, and business requirements. 1 Data Ingestion (e.g.,
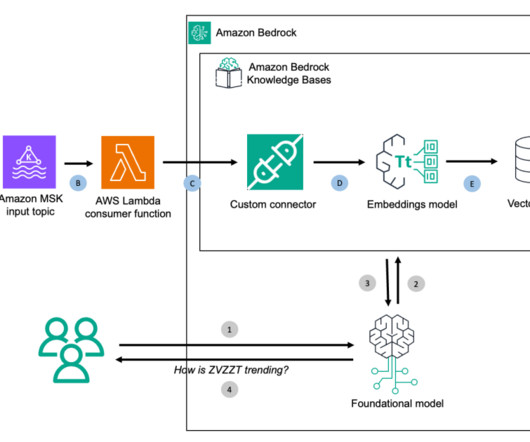
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
In this post, we dive deep into how CONXAI hosts the state-of-the-art OneFormer segmentation model on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS), KServe, and NVIDIA Triton. Our journey to AWS Initially, CONXAI started with a small cloud provider specializing in offering affordable GPUs.
Ultimately, leveraging Big Data analytics provides a competitive advantage and drives innovation across various industries. Competitive Advantage Organisations that leverage Big Data Analytics can stay ahead of the competition by anticipating market trends and consumer preferences.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content