This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
Talks and insights Mikhail Epikhin: Navigating the processor landscape for ApacheKafka Mikhail Epikhin began the session by sharing his team’s research on optimizing Managed Service for ApacheKafka. His presentation focused on the performance and efficiency of different instance types and processor architectures.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics. Why Pursue Real-Time Analytics for Your Organization?
After this, the data is analyzed, business logic is applied, and it is processed for further analytical tasks like visualization or machine learning. Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes.
Big Data Analytics stands apart from conventional data processing in its fundamental nature. It receives batch views from the batch layer and near-real-time views from the speed layer, utilizing this data to facilitate standard reporting and ad hoc analytics.
Apache Flink takes raw events and processes them, making them more relevant in the broader business context. The unique advantages of Apache Flink Apache Flink augments event streaming technologies like ApacheKafka to enable businesses to respond to events more effectively in real time.
This is essential for applications that demand immediate insights, such as fraud detection or real-time analytics. By centralising data from disparate sources, organisations can ensure that they have a unified view of their information, which is vital for analytics, reporting, and decision-making.
Anomaly detection can be done on your analytics data through Redshift ML by using the included XGBoost model type, local models, or remote models with Amazon SageMaker. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
ETL (Extract, Transform, Load) Processes Apache NiFi can streamline ETL processes by extracting data from multiple sources, transforming it into the desired format, and loading it into target systems such as data warehouses or databases. Its visual interface allows users to design complex ETL workflows with ease.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. ETL Design Pattern Here is an example of how the ETL design pattern can be used in a real-world scenario: A healthcare organization wants to analyze patient data to improve patient outcomes and operational efficiency.
It involves developing data pipelines that efficiently transport data from various sources to storage solutions and analytical tools. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity.
This structured approach ensures that data moves efficiently through each stage, undergoing necessary modifications to become usable for analytics or other applications. This approach supports applications requiring up-to-the-moment data insights, such as financial transactions, IoT monitoring, or real-time analytics in online platforms.
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. Then the events are ingested into TR’s centralized streaming platform, which is built on top of Amazon Managed Streaming for Kafka (Amazon MSK).
It also addresses security, privacy concerns, and real-world applications across various industries, preparing students for careers in data analytics and fostering a deep understanding of Big Data’s impact. Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities.
Efficient Incremental Processing with Apache Iceberg and Netflix Maestro Dimensional Data Modeling in the Modern Era Building Big Data Workflows: NiFi, Hive, Trino, & Zeppelin An Introduction to Data Contracts From Data Mess to Data Mesh — Data Management in the Age of Big Data and Gen AI Introduction to Containers for Data Science / Data Engineering (..)
Data Consumption : You have reached a point where the data is ready for consumption for AI, BI & other analytics. Pricing It is free to use and is licensed under Apache License Version 2.0. Best data pipeline tools: Talend | Source Categorization Open Source Batch data processing Pros Apache license makes it free to use.
Social Media Analytics: Companies may want to analyze real-time social media data to track trends, customer sentiment, and brand mentions as they happen. Streaming Analytics: Many businesses use real-time data ingestion to analyze streaming data from various sources, such as clickstreams, log files, and application metrics.
This involves working with various tools and technologies, such as ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, to move data from its source to its destination. Cloud providers offer various services such as storage, compute, and analytics, which can be used to build and operate big data systems.
A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Tools and Techniques to Manage Unstructured Data Several tools are required to properly manage unstructured data, from storage to analytical tools. is similar to the traditional Extract, Transform, Load (ETL) process.
Technologies like ApacheKafka, often used in modern CDPs, use log-based approaches to stream customer events between systems in real-time. It enables advanced analytics, makes debugging your marketing automations easier, provides natural audit trails for compliance, and allows for flexible, evolving customer data models.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















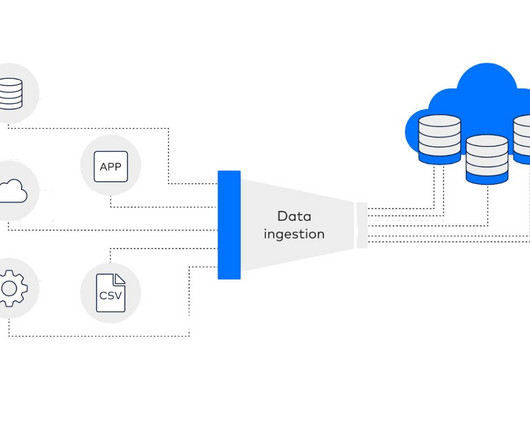










Let's personalize your content