This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Image Source: GitHub Table of Contents What is DataEngineering? The post How to Implement DataEngineering in Practice? appeared first on Analytics Vidhya. Initially, we have the definition of Software […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Ref :[link] Introduction: Slack is a communication platform. The post Slack DataEngineering: Design and Architecture appeared first on Analytics Vidhya. Users send.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will be looking for a very common yet very important topic i.e. SQL also pronounced as Ess-cue-ell. The post Introduction to SQL for DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction Data Science is a team sport, we have members adding value across the analytics/data science lifecycle so that it can drive the transformation by solving challenging business problems.
This article was published as a part of the Data Science Blogathon. Introduction to DataEngineering In recent days the consignment of data produced from innumerable sources is drastically increasing day-to-day. So, processing and storing of these data has also become highly strenuous.
This article was published as a part of the Data Science Blogathon Snowflake is a cloud data platform that comes with a lot of unique features when compared to traditional on-premise RDBMS systems. The post 5 Features Of Snowflake That DataEngineers Must Know appeared first on Analytics Vidhya.
Dataengineering plays a pivotal role in the vast data ecosystem by collecting, transforming, and delivering data essential for analytics, reporting, and machine learning. Aspiring dataengineers often seek real-world projects to gain hands-on experience and showcase their expertise.
This article was published as a part of the Data Science Blogathon. With QlikView, you can analyze and visualize data and their relationships and use these analyzes to make decisions. It Supports various data sources, including […]. It Supports various data sources, including […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction First of all, we are surrounded by data in day-to-day. The post DataEngineering – Concepts and Importance appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Have you ever thought of a means to get new data? The post Web Scrapping- Tool for DataEngineering appeared first on Analytics Vidhya. The post Web Scrapping- Tool for DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Dear DataEngineers, this article is a very interesting topic. Let me give some flashback; a few years ago, Mr.Someone in the discussion coined the new word how ACID and BASE properties of DATA. Everyone started […].
In this article, I will describe three of the most promising career options within the data industry? — dataanalytics, data science, and dataengineering.
This article was published as a part of the Data Science Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native data warehouse. Since its inception, BigQuery has evolved into a more economical and fully managed data warehouse that can run lightning-fast […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction- In this article, we will explore Apache Spark and PySpark, The post Know About Apache Spark Using PySpark for DataEngineering appeared first on Analytics Vidhya.
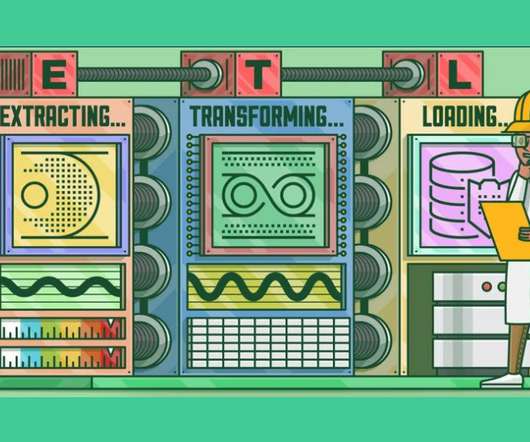
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a DataEngineer, extracting data from. The post Implementing ETL Process Using Python to Learn DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Companies struggle to manage and report all their data. The data repository should […]. The post Basics of Data Modeling and Warehousing for DataEngineers appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Machine learning and artificial intelligence, which are at the top of the list of data science capabilities, aren’t just buzzwords; many companies are keen to implement them.
This article was published as a part of the Data Science Blogathon. Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details.
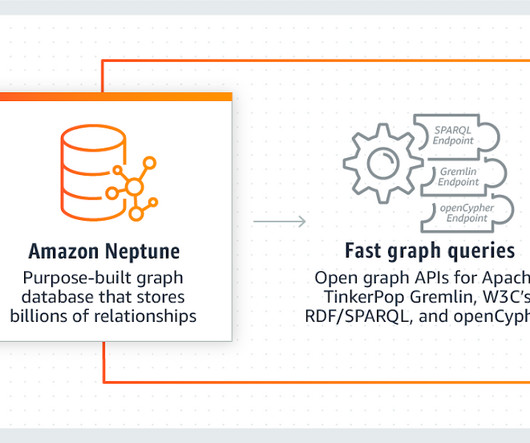
Enter the unsung heroes of the data world: graph databases. These powerful tools are designed to manage and query intricate data relationships effortlessly. This article discusses […] The post Neo4j vs. Amazon Neptune: Graph Databases in DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a big data processing framework that has long become one of the most popular and frequently encountered in all kinds of projects related to Big Data.
Overview This article will help you to achieve your goals in 2022. We will take you through a learning path that will help you achieve your dream to become a DataEngineer. Introduction Data Science is still considered a contemporary and highly advanced field. The post Hop on to your DataEngineering Career with AV!
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
This article was published as a part of the Data Science Blogathon. Introduction DataEngineering Tools DataEngineering is a growing sector that’s gaining a lot of attention as new technology creates more and more influx of Big Data.
In this contributed article, dataengineer Koushik Nandiraju discusses how a predictive data and analytics platform aligned with business objectives is no longer an option but a necessity.
This article was published as a part of the Data Science Blogathon Docker! The post End-to-End Guide to Docker for aspiring DataEngineers appeared first on Analytics Vidhya. The post End-to-End Guide to Docker for aspiring DataEngineers appeared first on Analytics Vidhya. What is it?
This article was published as a part of the Data Science Blogathon PySpark Column Operations plays a key role in manipulating and displaying desired results of PySpark DataFrame. The post Essential PySpark DataFrame Column Operations that DataEngineers Should Know appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. The post ETL & ELT – DataEngineering Essentials appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Big Data is a very commonly heard term these days. A reasonably large volume of data that cannot be handled on a small capacity configuration of servers can be called ‘Big Data’ in that particular context.
Airbyte, creators of a fast-growing open-source data integration platform, made available results of the biggest dataengineering survey in the market which provides insights into the latest trends, tools, and practices in dataengineering – especially adoption of tools in the modern data stack.
This article was published as a part of the Data Science Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
Dataanalytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. According to Gartner’s Hype Cycle, GenAI is at the peak, showcasing its potential to transform analytics.¹
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will discuss advanced topics in hives which are required for Data-Engineering. The post Hive Advance: Performance Tuning Techniques appeared first on Analytics Vidhya. Performance Tuning in […].
This article was published as a part of the Data Science Blogathon. Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for dataengineering pipelines. Most organizations today with complex data pipelines to […].
This article was published as a part of the Data Science Blogathon. Introduction on Data Preprocessing In this article, we will learn how to perform filtering operations, so why do we need filter operations? The post Data Preprocessing Using PySpark – Filter Operations appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Apache Sqoop is a big dataengine for transferring data between Hadoop and relational database servers. Big Data Sqoop can also be […]. Big Data Sqoop can also be […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction DataEngineers and data scientists often have to deal with. appeared first on Analytics Vidhya. The post Understand The concept of Indexing in depth!
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
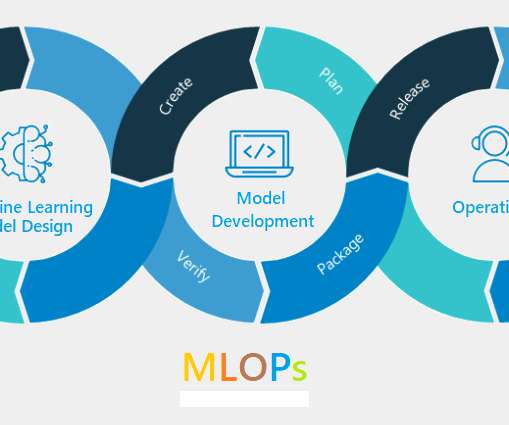
ArticleVideo Book This article was published as a part of the Data Science Blogathon ML + DevOps + DataEngineer = MLOPs Origins MLOps originated. The post DeepDive into the Emerging concpet of Machine Learning Operations or MLOPs appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Image Source: Author Introduction DataEngineers and Data Scientists need data for their Day-to-Day job. Of course, It could be for DataAnalytics, Data Prediction, Data Mining, Building Machine Learning Models Etc.,
This article was published as a part of the Data Science Blogathon. Introduction When creating data pipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
This article was published as a part of the Data Science Blogathon Overview Running data projects takes a lot of time. Poor data results in poor judgments. Running unit tests in data science and dataengineering projects assures data quality. You know your code does what you want it to do.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. Traditionally, ETL processes are […].
This article was published as a part of the Data Science Blogathon. Introduction As a Machine Learning Engineer or DataEngineer, your main task is to identify and clean duplicate data and remove errors from the dataset. The […].
This article was published as a part of the Data Science Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many dataengineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content