This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. Within the data flow, add an Amazon S3 destination node.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWSanalytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
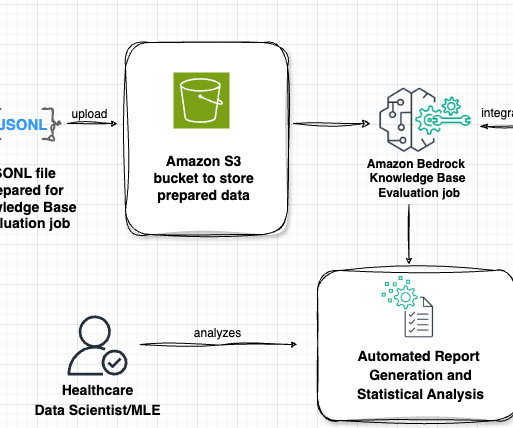
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
Prerequisites Before proceeding with this tutorial, make sure you have the following in place: AWS account – You should have an AWS account with access to Amazon Bedrock. Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. model in Amazon Bedrock.
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. AWS CodeBuild is a fully managed continuous integration service in the cloud.
ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. Let’s delve into the database portfolio from IBM available on AWS.
It does so by covering the end-to-end ML workflow: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, or the ability to configure foundation models for generative AI , SageMaker Canvas can help you achieve your goals. Choose Enable with AWS Organizations.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. It supports large-scale analysis and collaborative research through HealthOmics storage, analytics, and workflow capabilities.
Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images. The model was then fine-tuned with training data from the datapreparation stage. About the authors Scott Patterson is a Senior Solutions Architect at AWS.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
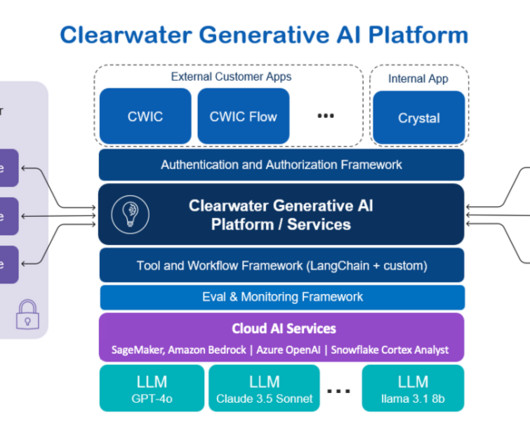
This post was written with Darrel Cherry, Dan Siddall, and Rany ElHousieny of Clearwater Analytics. The explosion of data creation and utilization, paired with the increasing need for rapid decision-making, has intensified competition and unlocked opportunities within the industry.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. Choose Create stack.
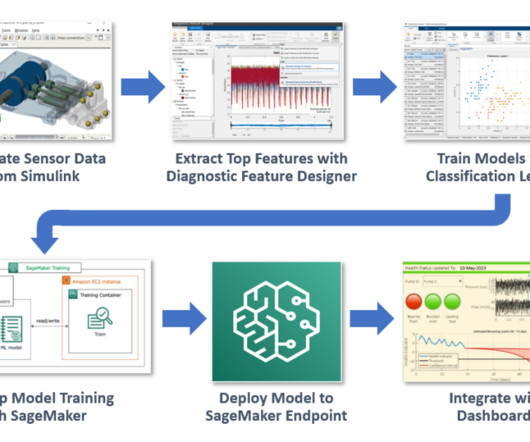
Working with AWS, Light & Wonder recently developed an industry-first secure solution, Light & Wonder Connect (LnW Connect), to stream telemetry and machine health data from roughly half a million electronic gaming machines distributed across its casino customer base globally when LnW Connect reaches its full potential.
The recently published IDC MarketScape: Asia/Pacific (Excluding Japan) AI Life-Cycle Software Tools and Platforms 2022 Vendor Assessment positions AWS in the Leaders category. AWS met the criteria and was evaluated by IDC along with eight other vendors. AWS is positioned in the Leaders category based on current capabilities.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
Prerequisites To use this feature, make sure that you have satisfied the following requirements: An active AWS account. model customization is available in the US West (Oregon) AWS Region. The required training dataset (and optional validation dataset) prepared and stored in Amazon Simple Storage Service (Amazon S3).
This post is co-written with Suhyoung Kim, General Manager at KakaoGames DataAnalytics Lab. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWSdata and ML services such as AWS Glue and Amazon SageMaker.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account. For Select a data source , choose Athena.
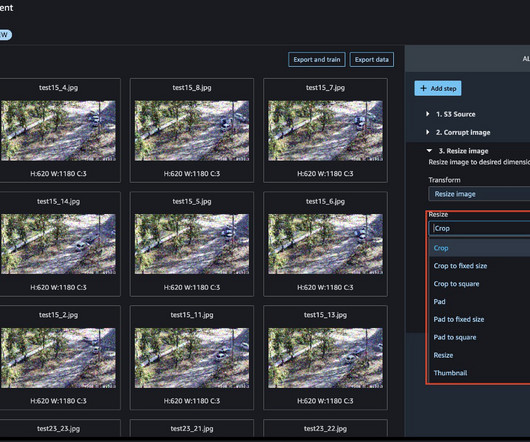
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import.
This allows SageMaker Studio users to perform petabyte-scale interactive datapreparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics.
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
In recent years, MathWorks has brought many product offerings into the cloud, especially on Amazon Web Services (AWS). Here is a quick guide on how to run MATLAB on AWS. Installation of AWS Command-Line Interface (AWS CLI) , AWS Configure , and Python3. Set up AWS Configure to interact with AWS resources.
For more information on Mixtral-8x7B Instruct on AWS, refer to Mixtral-8x7B is now available in Amazon SageMaker JumpStart. Before you get started with the solution, create an AWS account. This identity is called the AWS account root user. For more detailed steps to prepare the data, refer to the GitHub repo.
It supports all stages of ML development—from datapreparation to deployment, and allows you to launch a preconfigured JupyterLab IDE for efficient coding within seconds. To effectively utilize the wealth of information contained in such datasets for ML and analytics, access to the right tools for geospatial data handling is crucial.
We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket. Store your Snowflake account credentials in AWS Secrets Manager. Ingest the data in a table in your Snowflake account.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. Twilio needed to implement an MLOps pipeline that queried data from PrestoDB. All pipeline parameters used in this solution exist in a single config.yml file.
Finally, they can also train and deploy models with SageMaker Autopilot , schedule jobs, or operationalize datapreparation in a SageMaker Pipeline from Data Wrangler’s visual interface. Solution overview With SageMaker Studio setups, data professionals can quickly identify and connect to existing EMR clusters.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. To do this, we provide an AWS CloudFormation template to create a stack that contains the resources.
The solution required collecting and preparing user behavior data, training an ML model using Amazon Personalize, generating personalized recommendations through the trained model, and driving marketing campaigns with the personalized recommendations. The user interactions data from various sources is persisted in their data warehouse.
SageMaker Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Amazon SageMaker Canvas is a powerful no-code ML tool designed for business and data teams to generate accurate predictions without writing code or having extensive ML experience.
This is a joint blog with AWS and Philips. Since 2014, the company has been offering customers its Philips HealthSuite Platform, which orchestrates dozens of AWS services that healthcare and life sciences companies use to improve patient care.
Datapreparation is important at multiple stages in Retrieval Augmented Generation ( RAG ) models. Create a dataflow Complete the following steps to create a data flow in SageMaker Canvas: On the SageMaker Canvas home page, choose Datapreparation. This will land on a data flow page. Choose your domain.
Although the Amazon Kendra console comes equipped with an analytics dashboard, many of our customers prefer to build a custom dashboard. An AWS Glue crawler creates or updates the AWS Glue Data Catalog from the uploaded file in the S3 bucket for an Amazon Athena table. amazonaws.com docker build -t.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content