This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With QuickSight, all users can meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics, and natural language queries. For this post we’ll use a provisioned Amazon Redshift cluster. You can now view the predictions and download them as CSV.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
With these hyperlinks, we can bypass traditional memory and storage-intensive methods of first downloading and subsequently processing images locally—a task made even more daunting by the size and scale of our dataset, spanning over 4 TB. These batches are then evenly distributed across the machines in a cluster. format("/".join(tile_prefix),
Data analytics has created new opportunities for employers and workers around the world. A server cluster refers to a group of servers that share information and data. Data analytics has created new risks with digital security. However, analytics can also create new opportunities to protect digital data in other ways.
To upload the dataset Download the dataset : Go to the Shoe Dataset page on Kaggle.com and download the dataset file (350.79MB) that contains the images. OpenSearch Serverless is a serverless option for OpenSearch Service, a powerful storage option built for distributed search and analytics use cases.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform big data analytics and gain valuable insights from their data.
New advances in predictive analytics are helping solve many of these threats. Here are some reasons that predictive analytics technology is going to be the best line of defense against hackers and malware for the foreseeable future. This is where predictive analytics technology can be invaluable for security purposes.
Under Settings , enter a name for your database cluster identifier. Amazon S3 bucket Download the sample file 2020_Sales_Target.pdf in your local environment and upload it to the S3 bucket you created. Delete the Aurora MySQL instance and Aurora cluster. He has experience across analytics, big data, and ETL.
A growing number of DevOps platforms are using new data analytics and machine learning tools to boost performance. Teams that use Windows Enterprise also download and install Docker Desktop with a simple download. Similarly, you can download artifact management applications such as JFrog on your Windows system.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. The four kinds of dashboard are Operational , Analytical, Strategic and Self-service.
According to the 2021 CMO Spend Survey by Gartner, budget allocation for marketing analytics failed to make the top 3 in priority falling behind digital commerce, marketing operations and brand strategy. Building a buyer persona is more than just downloading a template online, filling in the blanks, and giving a fancy name to your customer.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics. Why Pursue Real-Time Analytics for Your Organization?
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Choose Choose File and navigate to the location on your computer where the CloudFormation template was downloaded and choose the file. Enter a stack name, such as Demo-Redshift.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. Although hardware failures while training on a single instance may be rare, issues resulting in stalled training become more prevalent as a cluster grows to tens or hundreds of instances.
In the world of data analytics, detecting anomalies is crucial for uncovering patterns that deviate from the norm. Whether it’s identifying fraudulent transactions, spotting manufacturing defects, or analyzing climate data, the ability to find outliers can significantly enhance decision-making processes. Thakur, eds.,
Summary: Incorporating TabPy into Tableau allows users to execute Python scripts directly within their dashboards, significantly enhancing analytical capabilities. Introduction In today’s data-driven landscape, organisations are increasingly looking for ways to enhance their Data Analytics capabilities. What is TabPy?
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. You want to gather insights on this data and build an ML model to predict how new restaurants will be rated, but find it challenging to perform analytics on unstructured data.
Summary: Elasticsearch transforms data management by enabling fast searches and real-time analytics. Introduction Elasticsearch is a powerful, open-source search and analytics engine designed for handling large volumes of data in real-time. Learn the difference between Business Intelligence and Business Analytics by clicking here.
Sprinklr’s specialized AI models streamline data processing, gather valuable insights, and enable workflows and analytics at scale to drive better decision-making and productivity. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
OLTP vs OLAP OLTP and online analytical processing ( OLAP ) are two distinct online data processing systems, although they share similar acronyms. Additionally, it streamlines analytics, making it easier for analysts and data scientists to extract insights from the data.
Project Search, Time Series Clustering, Multiple Excel / CSV Files Import, & more! And not only the data frame names you can also search by the chart (or analytics) tab names and the comments. This is not just for Search, but the pop-up window that shows up when you mouseover on the data frames now shows analytics as well.
Seamless data transfer between different platforms is crucial for effective data management and analytics. If you don’t have a Spark environment set up in your Cloudera environment, you can easily set up a Dataproc cluster on Google Cloud Platform (GCP) or an EMR cluster on AWS to do hands-on on your own.
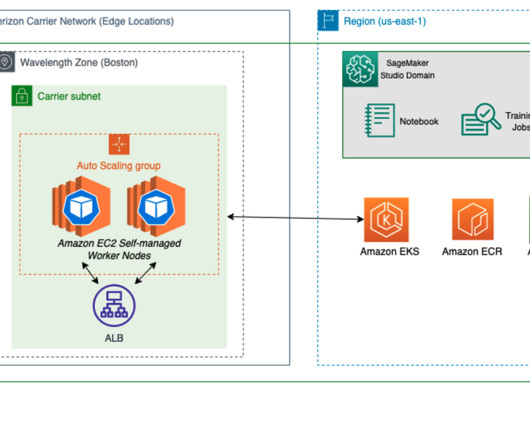
As an example, smart venue solutions can use near-real-time computer vision for crowd analytics over 5G networks, all while minimizing investment in on-premises hardware networking equipment. To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength.
Download and install the Chrome browser extension For the best meeting streaming experience, install the LMA browser plugin (currently available for Chrome): Choose Download Chrome Extension to download the browser extension.zip file ( lma-chrome-extension.zip ). Enable Developer mode. This loads your extension.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. This method leverages data from various sensors and advanced analytics to monitor the condition of equipment in real-time.
For Secret type , choose Credentials for Amazon Redshift cluster. Choose the Redshift cluster associated with the secrets. If you specify model_id=defog/sqlcoder-7b-2 , DJL Serving will attempt to directly download this model from the Hugging Face Hub. Enter a name for the secret, such as sm-sql-redshift-secret.
With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems. Moreover, the library can be downloaded in its entirety from reliable sources such as GitHub at no cost, ensuring its accessibility to a wide range of developers.
It supports large-scale analysis and collaborative research through HealthOmics storage, analytics, and workflow capabilities. Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics.
Anomaly detection can be done on your analytics data through Redshift ML by using the included XGBoost model type, local models, or remote models with Amazon SageMaker. Anomalies data for each measure can be downloaded for a detector by using the Amazon Lookout for Metrics APIs for a particular detector. Choose Delete.
To get started, download the Anaconda installer from the official Anaconda website and follow the installation instructions for your operating system. Scikit-learn covers various classification , regression , clustering , and dimensionality reduction algorithms. Once Anaconda is installed, launch the Anaconda Navigator.
We provide a comprehensive guide on how to deploy speaker segmentation and clustering solutions using SageMaker on the AWS Cloud. You use the same script for downloading the model file when creating the SageMaker endpoint. He has also developed the advanced analytics platform as a part of the digital transformation journey.
The integration of these multimodal capabilities has unlocked new possibilities for businesses and individuals, revolutionizing fields such as content creation, visual analytics, and software development. These models are released under different licenses designated by their respective sources. You can access the Meta Llama 3.2
Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. Download the dataset from Kaggle and upload it to an Amazon Simple Storage Service (Amazon S3) bucket. He works closely with enterprise customers building data lakes and analytical applications on the AWS platform.
For CSV, we still recommend splitting up large files into smaller ones to reduce data download time and enable quicker reads. The single-GPU training path still has some advantage in downloading and reading only part of the data in each instance, and therefore low data download time. However, it’s not a requirement. Tony Cruz
Download a free PDF by filling out the form. Thirty seconds is a good default for human users; if you find that queries are regularly queueing, consider making your warehouse a multi-cluster that scales on-demand. For most transformation and ingest warehouses, you can leave the cluster default of one minimum and one maximum.
The Hugging Face transformers , tokenizers , and datasets libraries provide APIs and tools to download and predict using pre-trained models in multiple languages. When scaling up your training job to a large GPU cluster, you can reduce the per-GPU memory footprint of the model by sharding the training state over multiple GPUs.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. OpenSearch Service is a fully managed service that makes it easy for you to perform interactive log analytics, real-time application monitoring, website search, and more. Prerequisites.
This process is essential for automatic speech recognition (ASR), meeting transcription, call center analytics, and more. Using a clustering method, want to determine the greatest number of speakers that could reasonably be heard in the audio. Speaker Diarization is also a powerful analytic tool. Why overestimate?
Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. EKS Blueprints helps compose complete EKS clusters that are fully bootstrapped with the operational software that is needed to deploy and operate workloads. You can also download these models from the website.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content