This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In a data-driven world, behind-the-scenes heroes like dataengineers play a crucial role in ensuring smooth data flow. A dataengineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless datapipelines.
The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
The needs and requirements of a company determine what happens to data, and those actions can range from extraction or loading tasks […]. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers. Nevertheless, setting up a streaming datapipeline to power such dashboards may […] The post DataEngineering for Streaming Data on GCP appeared first on Analytics Vidhya.
We are proud to announce two new analyst reports recognizing Databricks in the dataengineering and data streaming space: IDC MarketScape: Worldwide Analytic.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and dataengineering. They transform data into a consistent format for users to consume.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Although data forms the basis for effective and efficient analysis, large-scale data processing requires complete data-driven import and processing techniques […]. The post All About DataPipeline and Its Components appeared first on Analytics Vidhya.
Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for dataengineeringpipelines. Most organizations today with complex datapipelines to […]. The post Airflow for Orchestrating REST API Applications appeared first on Analytics Vidhya.
Dataanalytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. According to Gartner’s Hype Cycle, GenAI is at the peak, showcasing its potential to transform analytics.¹
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Introduction Apache Airflow is a crucial component in data orchestration and is known for its capability to handle intricate workflows and automate datapipelines. Many organizations have chosen it due to its flexibility and strong scheduling capabilities.
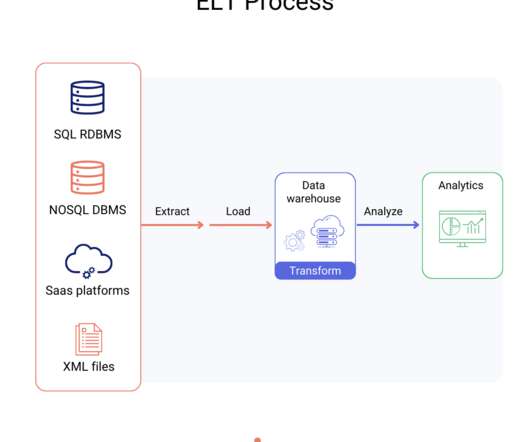
An ELT pipeline is a datapipeline that extracts (E) data from a source, loads (L) the data into a destination, and then transforms (T) data after it has been stored in the destination. If you can’t import all your data, you may only have a partial picture of your business.
Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method. Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. What is Microsoft Fabric?
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
Data must be combined and harmonized from multiple sources into a unified, coherent format before being used with AI models. Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as data integration, one of the key components to a strong data fabric.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Through these webinars, you’ll gain hands-on experience, deepen your understanding […] The post Join DataHour Sessions With Industry Experts appeared first on Analytics Vidhya.
A McKinsey survey found that companies that use customer analytics intensively are 19 times higher to achieve above-average profitability. But with the sheer amount of data continually increasing, how can a business make sense of it? Robust datapipelines. What is a DataPipeline? The answer?
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
Azure data factory helps organizations across the globe in making critical business decisions by collecting data from various sources such as e-commerce websites, supply chains, logistics, […] The post Most Frequently Asked Azure Data Factory Interview Questions appeared first on Analytics Vidhya.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Automation Automating datapipelines and models ➡️ 6. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? Big Ideas What to look out for in 2022 1.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
DataEngineer. In this role, you would perform batch processing or real-time processing on data that has been collected and stored. As a dataengineer, you could also build and maintain datapipelines that create an interconnected data ecosystem that makes information available to data scientists.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
The machine sensor data can be monitored directly in real time via respective datapipelines (real-time stream analytics) or brought into an overall picture of aggregated key figures (reporting). material flow analysis) for manufacturing and supply chain.
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. A feature platform should automatically process the datapipelines to calculate that feature.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. In the meantime, check out our first group of sessions.
Chatbots and virtual assistants are some of the common applications developed by NLP engineers for modern businesses. Big dataengineer Potential pay range – US$206,000 to 296,000/yr They operate at the backend to build and maintain complex systems that store and process the vast amounts of data that fuel AI applications.
Leaders feel the pressure to infuse their processes with artificial intelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement. Indeed, IDC has predicted that by the end of 2024, 65% of CIOs will face pressure to adopt digital tech , such as generative AI and deep analytics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content