This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy. An ecosystem consists of […].
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Data professionals across industries recognize they must effectively harness data for their businesses to innovate and gain competitive advantage. High quality, reliable data forms the backbone for all successful data endeavors, from reporting and analytics to machinelearning.
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Be sure to check out his talk, “ Apache Kafka for Real-Time MachineLearning Without a DataLake ,” there! The combination of data streaming and machinelearning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the Apache Kafka ecosystem.
Components of Data Engineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is Data Engineering? The post How to Implement Data Engineering in Practice? appeared first on Analytics Vidhya.
We have solicited insights from experts at industry-leading companies, asking: "What were the main AI, Data Science, MachineLearning Developments in 2021 and what key trends do you expect in 2022?" Read their opinions here.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
This post is part of an ongoing series about governing the machinelearning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. Data governance account – This account hosts the central data governance services provided by Amazon DataZone.
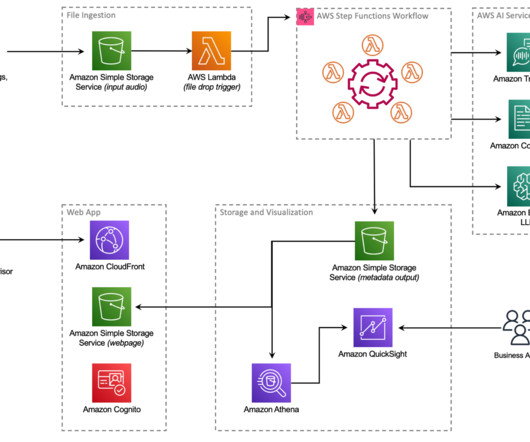
The end-to-end workflow features a supervisor agent at the center, classification and conversion agents branching off, a humanintheloop step, and Amazon Simple Storage Service (Amazon S3) as the final unstructured datalake destination. Make sure that every incoming data eventually lands, along with its metadata, in the S3 datalake.
Data virtualization refers to a method that creates a virtual representation of data, enabling access to information from multiple sources as if it were one cohesive unit. This approach eliminates the challenges of data replication, simplifies data interaction, and supports real-time analytics.
The modern corporate world is more data-driven, and companies are always looking for new methods to make use of the vast data at their disposal. Cloud analytics is one example of a new technology that has changed the game. What is cloud analytics? How does cloud analytics work?
Structured data is a fundamental component in the world of data management and analytics, playing a crucial role in how we store, retrieve, and process information. By organizing data into a predetermined format, it enables efficient access and manipulation, forming the backbone of many applications across various industries.
Starburst, the datalakeanalytics platform, today extended their support for the most widely used multi-purpose, high-level programming language, Python with PyStarburst, as well as announced a new integration with the open source Python library, Ibis, built in collaboration with composable data systems builder and Ibis maintainer, Voltron Data. (..)
Welcome to this comprehensive guide on Azure MachineLearning , Microsoft’s powerful cloud-based platform that’s revolutionizing how organizations build, deploy, and manage machinelearning models. This is where Azure MachineLearning shines by democratizing access to advanced AI capabilities.
Microsoft has made good on its promise to deliver a simplified and more efficient Microsoft Fabric price model for its end-to-end platform designed for analytics and data workloads. Microsoft’s unified pricing model for the Fabric suite marks a significant advancement in the analytics and data market.
An interactive analytics application gives users the ability to run complex queries across complex data landscapes in real-time: thus, the basis of its appeal. Interactive analytics applications present vast volumes of unstructured data at scale to provide instant insights. Why Use an Interactive Analytics Application?
By some estimates, unstructured data can make up to 80–90% of all new enterprise data and is growing many times faster than structured data. After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. These services write the output to a datalake.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
Google BigQuery: Google BigQuery is a serverless, cloud-based data warehouse designed for big dataanalytics. It offers scalable storage and compute resources, enabling data engineers to process large datasets efficiently. It can handle both batch and real-time data processing tasks efficiently.
Data is the foundation for machinelearning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
MPII is using a machinelearning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability.
LLM companies are businesses that specialize in developing and deploying Large Language Models (LLMs) and advanced machinelearning (ML) models. This platform enables developers to train custom machinelearning models for natural language processing tasks, further broadening the scope and application of Google’s LLMs.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
Among these, four primary use cases have emerged as especially prominent: intelligent process automation, anomaly detection, analytics, and operational assistance. Different types of data typically require different tools to access them. Traditionally, businesses face a challenge.
We often hear that organizations have invested in data science capabilities but are struggling to operationalize their machinelearning models. Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Data mining is a fascinating field that blends statistical techniques, machinelearning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
Principal is conducting enterprise-scale near-real-time analytics to deliver a seamless and hyper-personalized omnichannel customer experience on their mission to make financial security accessible for all. They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Organizationally the innovation of self-service analytics, pioneered by Tableau and Qlik, fundamentally transformed the user model for data analysis. The Rise of the Data Catalog.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. Call for Research Proposals Amazon is seeking proposals impact research in the Artificial Intelligence and MachineLearning areas.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
However, computerization in the digital age creates massive volumes of data, which has resulted in the formation of several industries, all of which rely on data and its ever-increasing relevance. Dataanalytics and visualization help with many such use cases. It is the time of big data. What Is DataAnalytics?
By setting up automated policy enforcement and checks, you can achieve cost optimization across your machinelearning (ML) environment. Usage of data is tracked through the data consumers, such as Amazon Athena , Amazon Redshift , or Amazon SageMaker. This identifies teams or cost centers responsible for those resources.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. He specializes in building scalable machinelearning infrastructure, distributed systems, and containerization technologies.
Customers of every size and industry are innovating on AWS by infusing machinelearning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time MachineLearning with Spark and SBERT Learn more about real-time machinelearning by using this approach that uses Apache Spark and SBERT. Register for free!
PlotlyInteractive Data Visualization Plotly is a leader in interactive data visualization tools, offering open-source graphing libraries in Python, R, JavaScript, and more. Their solutions, including Dash, make it easier for developers and data scientists to build analytical web applications with minimalcoding.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content