This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale. This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product.
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
After decades of digitizing everything in your enterprise, you may have an enormous amount of data, but with dormant value. However, with the help of AI and machine learning (ML), new software tools are now available to unearth the value of unstructured data. These services write the output to a datalake.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.
An interactive analytics application gives users the ability to run complex queries across complex data landscapes in real-time: thus, the basis of its appeal. Interactive analytics applications present vast volumes of unstructured data at scale to provide instant insights. Why Use an Interactive Analytics Application?
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker , and utilize a combined architecture.
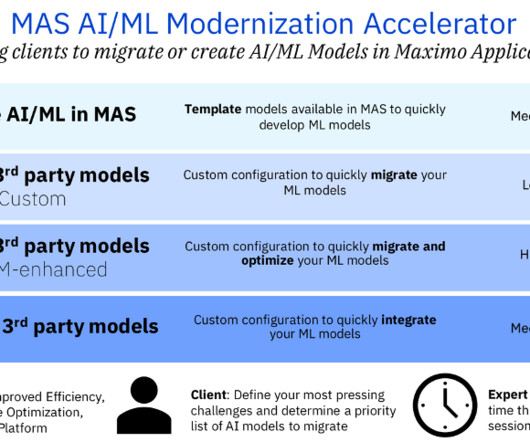
Many businesses are in different stages of their MAS AI/ML modernization journey. In this blog, we delve into 4 different “on-ramps” we created in a MAS Accelerator to offer a straightforward path to harnessing the power of AI in MAS, wherever you may be on your MAS AI/ML modernization journey.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Principal is conducting enterprise-scale near-real-time analytics to deliver a seamless and hyper-personalized omnichannel customer experience on their mission to make financial security accessible for all. They are processing data across channels, including recorded contact center interactions, emails, chat and other digital channels.
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud data warehouse, delivering the best price-performance for your analytics workloads.
LLM companies are businesses that specialize in developing and deploying Large Language Models (LLMs) and advanced machine learning (ML) models. WhyLabs WhyLabs is renowned for its versatile and robust machine learning (ML) observability platform. What are LLM Companies?
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Enterprises can use no-code ML solutions to streamline their operations and optimize their decision-making without extensive administrative overhead.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
Thats why we use advanced technology and dataanalytics to streamline every step of the homeownership experience, from application to closing. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
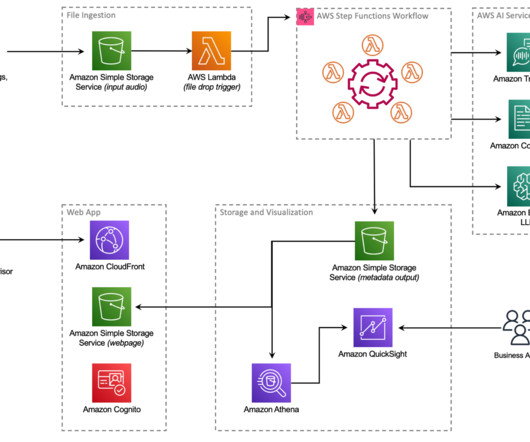
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
As the Internet of Things (IoT) continues to revolutionize industries and shape the future, data scientists play a crucial role in unlocking its full potential. A recent article on Analytics Insight explores the critical aspect of data engineering for IoT applications.
Solution overview Amazon SageMaker is a fully managed service that helps developers and data scientists build, train, and deploy machine learning (ML) models. Data preparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
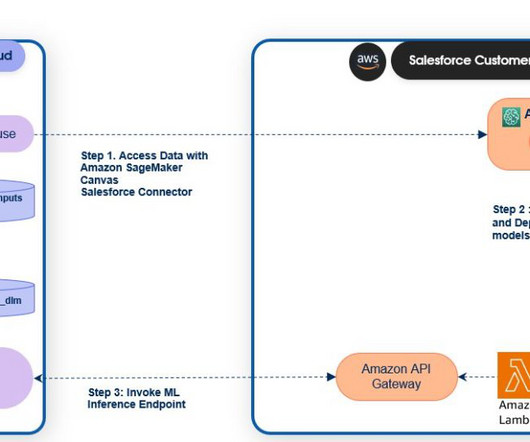
SageMaker endpoints can be registered to the Salesforce Data Cloud to activate predictions in Salesforce. SageMaker Canvas provides a no-code experience to access data from Salesforce Data Cloud and build, test, and deploy models using just a few clicks. On the Create menu, choose Tabular to create a tabular dataset.
Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. Azure Arc You can now run Azure services anywhere (on-prem, on the edge, any cloud) you can run Kubernetes. Amazon Web Services.
Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models. Amazon SageMaker JumpStart provides pre-trained models and data to help you get started with ML. MongoDB vector data store MongoDB Atlas Vector Search is a new feature that allows you to store and search vector data in MongoDB.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. In this post, we describe how to query Parquet files with Athena using AWS Lake Formation and use the output Canvas to train a model.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Azure Machine Learning is Microsoft’s enterprise-grade service that provides a comprehensive environment for data scientists and ML engineers to build, train, deploy, and manage machine learning models at scale. You can explore its capabilities through the official Azure ML Studio documentation. Awesome, right?
By running reports on historical data, a data warehouse can clarify what systems and processes are working and what methods need improvement. Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well. Modern data warehousing technology can handle all data forms.
We capitalized on the powerful tools provided by AWS to tackle this challenge and effectively navigate the complex field of machine learning (ML) and predictive analytics. This capability of predictive analytics, particularly the accurate forecast of product categories, has proven invaluable.
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
Another IDC study showed that while 2/3 of respondents reported using AI-driven dataanalytics, most reported that less than half of the data under management is available for this type of analytics. from 2022 to 2026.
Whether it’s data management, analytics, or scalability, AWS can be the top-notch solution for any SaaS company. Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including datalakes, analytics dashboards, and ETL pipelines.
Article on Azure ML by Bethany Jepchumba and Josh Ndemenge of Microsoft In this article, I will cover how you can train a model using Notebooks in Azure Machine Learning Studio. Using Azure ML, you can train your model in three ways: Automated ML: This is where you upload your data and have the workspace automatically train on your behalf.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. This tool automatically detects problems in an ML dataset.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content