This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Google BigQuery: Google BigQuery is a serverless, cloud-based data warehouse designed for big dataanalytics.
However, most organizations struggle to become data driven. Data is stuck in siloes, infrastructure can’t scale to meet growing data needs, and analytics is still too hard for most people to use. Google's Cloud Platform is the enterprise solution of choice for many organizations with large and complex data problems.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
However, most organizations struggle to become data driven. Data is stuck in siloes, infrastructure can’t scale to meet growing data needs, and analytics is still too hard for most people to use. Google's Cloud Platform is the enterprise solution of choice for many organizations with large and complex data problems.
How to Optimize Power BI and Snowflake for Advanced Analytics Spencer Baucke May 25, 2023 The world of business intelligence and data modernization has never been more competitive than it is today. Much of what is discussed in this guide will assume some level of analytics strategy has been considered and/or defined. No problem!
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
Data Lakes are among the most complex and sophisticated data storage and processing facilities we have available to us today as human beings. Analytics Magazine notes that data lakes are among the most useful tools that an enterprise may have at its disposal when aiming to compete with competitors via innovation.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. The power of the customer graph keeps going.
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. . But good data—and actionable insights—are hard to get. The power of the customer graph keeps going.
MongoDB for end-to-end AI data management MongoDB Atlas , an integrated suite of data services centered around a multi-cloud NoSQL database, enables developers to unify operational, analytical, and AI data services to streamline building AI-enriched applications.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
But where DevOps focuses on product development, DataOps aims to reduce the time from data need to data success. At its best, DataOps shortens the cycle time for analytics and aligns with business goals. Data Operations, or DataOps, is like DevOps in that both are based in agile, continuous improvement thinking.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides data science and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic data science concepts to advanced machine learning techniques.
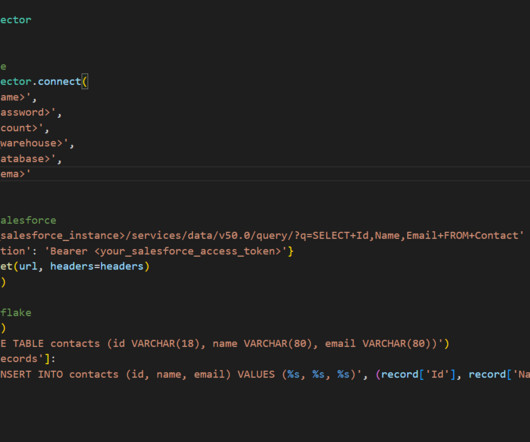
Advantages One of the main advantages of this approach is that it enables businesses to centralize their data in Snowflake, which can improve data accuracy and consistency. It also permits enterprises to perform advanced analytics on their Salesforce data using Snowflake’s powerful analytics capabilities.
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. Snowflake Data Cloud Replication Transferring data from a source system to a cloud data warehouse.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. Finally, conduct a proof of concept to assess how the data warehouse meets requirements. Featuring a robust architecture, it powers efficient data storage, processing, and querying.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. Dynamic tables provide a streamlined and efficient mechanism for capturing and processing changes in data.
To learn more, watch the webinar “Implementing Gen AI for Financial Services” with Larry Lerner, Partner & Global Lead - Banking and Securities Analytics, McKinsey & Company, and Yaron Haviv, Co-founder and CTO, Iguazio (acquired by McKinsey), which this blog post is based on. Let’s dive into the data management pipeline.
An integrated model factory to develop, deploy, and monitor models in one place using your preferred tools and languages. Databricks Databricks is a cloud-native platform for big data processing, machine learning, and analytics built using the Data Lakehouse architecture. Can you render audio/video?
Mastering skills helps stay ahead with the current data landscape and prepare for future transformations. A data engineering career has become highly crucial due to the need for a harmonious interflow of technical prowess, analytical thinking, and problem-solving agility. Hadoop, Spark).
In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, Business Intelligence and Analytics tools, Data Governance , and Metadata Management solutions. The most important reason for using DBT in Data Vault 2.0
Every company today is being asked to do more with less, and leaders need access to fresh, trusted KPIs and data-driven insights to manage their businesses, keep ahead of the competition, and provide unparalleled customer experiences. But good data—and actionable insights—are hard to get. What is Salesforce Data Cloud for Tableau?
What does a modern data architecture do for your business? A modern data architecture like Data Mesh and Data Fabric aims to easily connect new data sources and accelerate development of use case specific datapipelines across on-premises, hybrid and multicloud environments.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. It also lets you choose the right engine for the right workload at the right cost, potentially reducing your data warehouse costs by optimizing workloads.
Businesses might need to invest additional resources to fix data issues, integrate disparate systems, or replace the inadequate tool entirely. Long-Term Data Management Strategies Investing in the right ETL tool offers numerous long-term benefits. Read Further: Azure Data Engineer Jobs.
Real-time Monitoring and Analytics It enables real-time monitoring of critical infrastructure, industrial processes, and financial markets. This data can be vast and complex, and TSDBs provide the necessary capabilities for efficient storage, retrieval, and analysis, facilitating scientific discovery and innovation.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Under this category, tools with pre-built connectors for popular data sources and visual tools for data transformation are better choices. Integration: How well does the tool integrate with your existing infrastructure, databases, cloud platforms, and analytics tools?
Using 3rd party tooling is essential if you’re a Snowflake AI Data Cloud customer. Getting your data into Snowflake, creating analytics applications from the data, and even ensuring your Snowflake account runs smoothly all require some sort of tool. But you still want to start building out the datamodel.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By doing so, you can ensure quality and production-ready models.
How can we build up toward our vision in terms of solvable data problems and specific data products? data sources or simpler datamodels) of the data products we want to build? A data product may aim to automate a decision, or it may aim to assist a human decision-maker. What are we working towards?
We aim to help you understand how these schemas impact data warehousing and guide you in selecting the most appropriate design for your organisation’s analytical requirements. What is Dimensional Modeling? It is commonly used in data warehouses for business analytics and reporting.
Today, companies are facing a continual need to store tremendous volumes of data. The demand for information repositories enabling business intelligence and analytics is growing exponentially, giving birth to cloud solutions. Use Multiple DataModels With on-premise data warehouses, storing multiple copies of data can be too expensive.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By doing so, you can ensure quality and production-ready models.
Data Engineer Data engineers are the authors of the infrastructure that stores, processes, and manages the large volumes of data an organization has. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
It is specially designed for monitoring highly dynamic containerized environments such as Kubernetes and provides powerful features for collecting, querying, visualizing, and alerting on time-series data. Apache Airflow Apache Airflow is an open-source workflow orchestration tool that can manage complex workflows and datapipelines.
Structuring the dbt Project The most important aspect of any dbt project is its structural design, which organizes project files and code in a way that supports scalability for large data warehouses. DataAnalytics Engineers create models to transform data without it ever leaving the warehouse.
ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
The good news is that there’s a concept called the Modern Data Stack that when utilized properly, consistently helps empower organizations to harness the full potential of their data. Throughout this journey, we’ve helped hundreds of clients achieve eye-opening results by moving to the Modern Data Stack.
The benefits often drive priority, so unless cost structures change, it will be an ongoing challenge to retire, archive, and delete data as we would wish. In terms of identifying which data should be owned and governed – where do we start? Some data seems more analytical, while other is operational (external facing).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content