This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this sponsored post, Devika Garg, PhD, Senior Solutions Marketing Manager for Analytics at Pure Storage, believes that in the current era of data-driven transformation, IT leaders must embrace complexity by simplifying their analytics and data footprint.
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […].
The needs and requirements of a company determine what happens to data, and those actions can range from extraction or loading tasks […]. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
The post All About DataPipeline and Kafka Basics appeared first on Analytics Vidhya. But as the technology emerged, people have automated the process of getting water for their use without having to collect it from different […].
While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. This article dives into the core functionalities of dbt, exploring its unique strengths and how […] The post Transforming Your DataPipeline with dbt(data build tool) appeared first on Analytics Vidhya.
In the data-driven world […] The post Monitoring Data Quality for Your Big DataPipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Introduction Discover the ultimate guide to building a powerful datapipeline on AWS! In today’s data-driven world, organizations need efficient pipelines to collect, process, and leverage valuable data. With AWS, you can unleash the full potential of your data.
Introduction In this blog, we will explore one interesting aspect of the pandas read_csv function, the Python Iterator parameter, which can be used to read relatively large input data. Pandas library in python is an excellent choice for reading and manipulating data as data frames. […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. The post ETL Pipeline using Shell Scripting | DataPipeline appeared first on Analytics Vidhya. What is shell scripting?
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Kafka is based on the idea of a distributed commit log, which stores and manages streams of information that can still work even […] The post Build a Scalable DataPipeline with Apache Kafka appeared first on Analytics Vidhya.
Introduction Datapipelines play a critical role in the processing and management of data in modern organizations. A well-designed datapipeline can help organizations extract valuable insights from their data, automate tedious manual processes, and ensure the accuracy of data processing.
.- Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. The Internet of Things(IoT) devices can generate a large […].
Handling and processing the streaming data is the hardest work for Data Analysis. We know that streaming data is data that is emitted at high volume […] The post Kafka to MongoDB: Building a Streamlined DataPipeline appeared first on Analytics Vidhya.
Although data forms the basis for effective and efficient analysis, large-scale data processing requires complete data-driven import and processing techniques […]. The post All About DataPipeline and Its Components appeared first on Analytics Vidhya.
Business leaders are growing weary of making further investments in business intelligence (BI) and big dataanalytics. Beyond the challenging technical components of data-driven projects, BI and analytics services have yet to live up to the hype.
Azure Data Factory […]. The post Building an ETL DataPipeline Using Azure Data Factory appeared first on Analytics Vidhya. It helps organizations across the globe in planning marketing strategies and making critical business decisions.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
We are proud to announce two new analyst reports recognizing Databricks in the data engineering and data streaming space: IDC MarketScape: Worldwide Analytic.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article we will be discussing Binary Image Classification. The post Image Classification with TensorFlow : Developing the DataPipeline (Part 1) appeared first on Analytics Vidhya.
Dataanalytics has become a key driver of commercial success in recent years. The ability to turn large data sets into actionable insights can mean the difference between a successful campaign and missed opportunities. According to Gartner’s Hype Cycle, GenAI is at the peak, showcasing its potential to transform analytics.¹
Introduction Imagine yourself as a data professional tasked with creating an efficient datapipeline to streamline processes and generate real-time information. Sounds challenging, right? That’s where Mage AI comes in to ensure that the lenders operating online gain a competitive edge.
Most organizations today with complex datapipelines to […]. The post Airflow for Orchestrating REST API Applications appeared first on Analytics Vidhya. It started at Airbnb in October 2014 as a solution to manage the company’s increasingly complex workflows.
Artificial intelligence (AI) and natural language processing (NLP) technologies are evolving rapidly to manage live data streams. They power everything from chatbots and predictive analytics to dynamic content creation and personalized recommendations.
It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating datapipelines, and efficiently managing data warehouses. appeared first on Analytics Vidhya.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. The movement of data in a pipeline from one point to another.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis.
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL.
Over the last few years, with the rapid growth of data, pipeline, AI/ML, and analytics, DataOps has become a noteworthy piece of day-to-day business New-age technologies are almost entirely running the world today. Among these technologies, big data has gained significant traction. This concept is …
Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers. Nevertheless, setting up a streaming datapipeline to power such dashboards may […] The post Data Engineering for Streaming Data on GCP appeared first on Analytics Vidhya.
Introduction Apache Airflow is a crucial component in data orchestration and is known for its capability to handle intricate workflows and automate datapipelines. Many organizations have chosen it due to its flexibility and strong scheduling capabilities.
It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
A data engineer investigates the issue, identifies a glitch in the e-commerce platform’s data funnel, and swiftly implements seamless datapipelines. While data scientists and analysts receive […] The post What Data Engineers Really Do? appeared first on Analytics Vidhya.
By treating relational databases as the rich, interconnected graphs they inherently are, these models eliminate the need for extensive feature engineering and complex datapipelines that have traditionally slowed AI adoption.
ArticleVideos I will admit, AWS Data Wrangler has become my go-to package for developing extract, transform, and load (ETL) datapipelines and other day-to-day. The post Using AWS Data Wrangler with AWS Glue Job 2.0 appeared first on Analytics Vidhya.
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method. Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. What is Microsoft Fabric?
Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning datapipelines.
The concept of streaming data was born of necessity. More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Business success is based on how we use continuously changing data.
To provide our community with a better understanding of how different elements of the subject are used in different domains, Analytics Vidhya has launched our DataHour sessions. appeared first on Analytics Vidhya. These sessions will enhance your domain knowledge and help you learn new […].
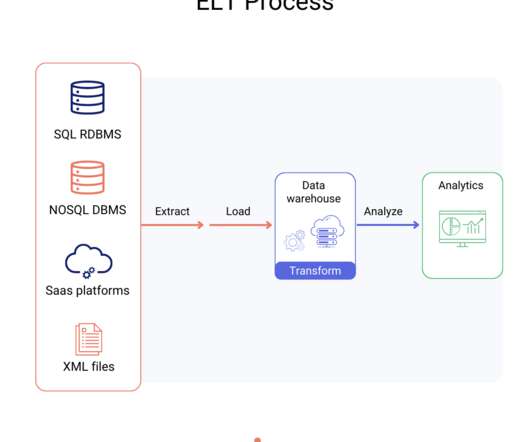
An ELT pipeline is a datapipeline that extracts (E) data from a source, loads (L) the data into a destination, and then transforms (T) data after it has been stored in the destination. If you can’t import all your data, you may only have a partial picture of your business.
Dataanalytics helps to determine the success of the business. Therefore, data-driven analytics eventually helps to bring a change. Impact Of Data-Driven Analytics. Several companies in today’s time claim to be a part of the data-driven world. How Is Data-Driven Analytics Being Helpful?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content