This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction SQL is easily one of the most important languages in the computer world. It serves as the primary means for communicating with relational databases, where most organizations store crucial data. SQL plays a significant role including analyzing complex data, creating datapipelines, and efficiently managing data warehouses.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century. The post Dynamic SQL Queries to Transform Data appeared first on Analytics Vidhya.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis.
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL.
Knowledge-intensive analytical applications retrieve context from both structured tabular data and unstructured, text-free documents for effective decision-making. Large language models (LLMs) have made it significantly easier to prototype such retrieval and reasoning datapipelines.
Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method. Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. What is Microsoft Fabric?
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
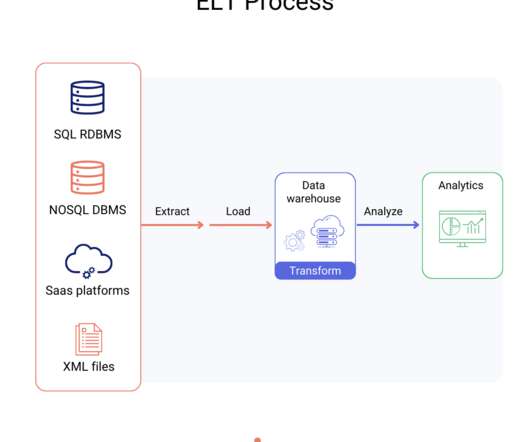
An ELT pipeline is a datapipeline that extracts (E) data from a source, loads (L) the data into a destination, and then transforms (T) data after it has been stored in the destination. If you can’t import all your data, you may only have a partial picture of your business.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Google BigQuery: Google BigQuery is a serverless, cloud-based data warehouse designed for big dataanalytics.
This is especially true for questions that require analytical reasoning across multiple documents. This task involves answering analytical reasoning questions. In this post, we show how to design an intelligent document assistant capable of answering analytical and multi-step reasoning questions in three parts.
Managing and retrieving the right information can be complex, especially for data analysts working with large data lakes and complex SQL queries. This tool converts questions from data analysts asked in natural language (such as “Which table contains customer address information?”)
Data must be combined and harmonized from multiple sources into a unified, coherent format before being used with AI models. Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as data integration, one of the key components to a strong data fabric.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. This will provision the backend infrastructure and services that the sales analytics application will rely on.
However, most organizations struggle to become data driven. Data is stuck in siloes, infrastructure can’t scale to meet growing data needs, and analytics is still too hard for most people to use. Google's Cloud Platform is the enterprise solution of choice for many organizations with large and complex data problems.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. With QuickSight, all users can meet varying analytic needs from the same source of truth through modern interactive dashboards, paginated reports, embedded analytics, and natural language queries. Basic knowledge of a SQL query editor.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Azure data factory helps organizations across the globe in making critical business decisions by collecting data from various sources such as e-commerce websites, supply chains, logistics, […] The post Most Frequently Asked Azure Data Factory Interview Questions appeared first on Analytics Vidhya.
Though you may encounter the terms “data science” and “dataanalytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, dataanalytics is the act of examining datasets to extract value and find answers to specific questions.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
However, most organizations struggle to become data driven. Data is stuck in siloes, infrastructure can’t scale to meet growing data needs, and analytics is still too hard for most people to use. Google's Cloud Platform is the enterprise solution of choice for many organizations with large and complex data problems.
The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements. ETL is one of the most integral processes required by Business Intelligence and Analytics use cases since it relies on the data stored in Data Warehouses to build reports and visualizations.
The modern data stack is defined by its ability to handle large datasets, support complex analytical workflows, and scale effortlessly as data and business needs grow. Two key technologies that have become foundational for this type of architecture are the Snowflake AI Data Cloud and Dataiku.
Using structured data to answer questions requires a way to effectively extract data that’s relevant to a user’s query. We formulated a text-to-SQL approach where by a user’s natural language query is converted to a SQL statement using an LLM. The SQL is run by Amazon Athena to return the relevant data.
How to Optimize Power BI and Snowflake for Advanced Analytics Spencer Baucke May 25, 2023 The world of business intelligence and data modernization has never been more competitive than it is today. Much of what is discussed in this guide will assume some level of analytics strategy has been considered and/or defined. No problem!
Domain experts, for example, feel they are still overly reliant on core IT to access the data assets they need to make effective business decisions. In all of these conversations there is a sense of inertia: Data warehouses and data lakes feel cumbersome and datapipelines just aren't agile enough.
Automation Automating datapipelines and models ➡️ 6. The most common data science languages are Python and R — SQL is also a must have skill for acquiring and manipulating data. The Data Engineer Not everyone working on a data science project is a data scientist.
Alteryx and the Snowflake Data Cloud offer a potential solution to this issue and can speed up your path to Analytics. In this blog post, we will explore how Alteryx and Snowflake can accelerate your journey to Analytics by sharing use cases and best practices. What is Alteryx? What is Snowflake?
Skills and qualifications required for the role To excel as a machine learning engineer, individuals need a combination of technical skills, analytical thinking, and problem-solving abilities. They work with raw data, transform it into a usable format, and apply various analytical techniques to extract actionable insights.
Being able to discover connections between variables and to make quick insights will allow any practitioner to make the most out of the data. Analytics and Data Analysis Coming in as the 4th most sought-after skill is dataanalytics, as many data scientists will be expected to do some analysis in their careers.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. VisiData works with CSV files, Excel spreadsheets, SQL databases, and many other data sources.
Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python. Databases and SQL : Managing and querying relational databases using SQL, as well as working with NoSQL databases like MongoDB.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. However, there might be instances where you need to migrate the raw event data from GA4 to Snowflake for more in-depth analysis and business intelligence purposes.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Putting the T for Transformation in ELT (ETL) is essential to any datapipeline. After extracting and loading your data into the Snowflake AI Data Cloud , you may wonder how best to transform it. Luckily, Snowflake answers this question with many features designed to transform your data for all your analytic use cases.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any cloud data platform in the market. Building datapipelines manually is an expensive and time-consuming process. Why Use Fivetran?
It consolidates data from various systems, such as transactional databases, CRM platforms, and external data sources, enabling organizations to perform complex queries and derive insights. By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making.
Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. It involves developing datapipelines that efficiently transport data from various sources to storage solutions and analytical tools. ETL is vital for ensuring data quality and integrity.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content