This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As data science evolves and grows, the demand for skilled datascientists is also rising. A datascientist’s role is to extract insights and knowledge from data and to use this information to inform decisions and drive business growth.
Today’s question is, “What does a datascientist do.” ” Step into the realm of data science, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of datascientists.
It allows people with excess computing resources to sell them to datascientists in exchange for cryptocurrencies. Datascientists can access remote computing power through sophisticated networks. This feature helps automate many parts of the datapreparation and data model development process.
Predictive analytics, sometimes referred to as big dataanalytics, relies on aspects of data mining as well as algorithms to develop predictive models. These predictive models can be used by enterprise marketers to more effectively develop predictions of future user behaviors based on the sourced historical data.
Predictive modeling plays a crucial role in transforming vast amounts of data into actionable insights, paving the way for improved decision-making across industries. By leveraging statistical techniques and machine learning, organizations can forecast future trends based on historical data. What is predictive modeling?
Learn the essential skills needed to become a Data Science rockstar; Understand CNNs with Python + Tensorflow + Keras tutorial; Discover the best podcasts about AI, Analytics, Data Science; and find out where you can get the best Certificates in the field.
What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. However, instead of using Hadoop, data lakes are increasingly being constructed using cloud object storage services. Which one is right for your business?
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
Dataanalytics is integral to modern business, but many organizations’ efforts are starting to fall flat. Now that virtually every company is capitalizing on data, analytics alone isn’t enough to surge ahead of the competition. You must be able to analyze data faster, more accurately, and within context.
By harnessing the power of data and analytics, companies can gain a competitive edge, enhance customer satisfaction, and mitigate risks effectively. Leveraging a combination of data, analytics, and machine learning, it emerges as a multidisciplinary field that empowers organizations to optimize their decision-making processes.
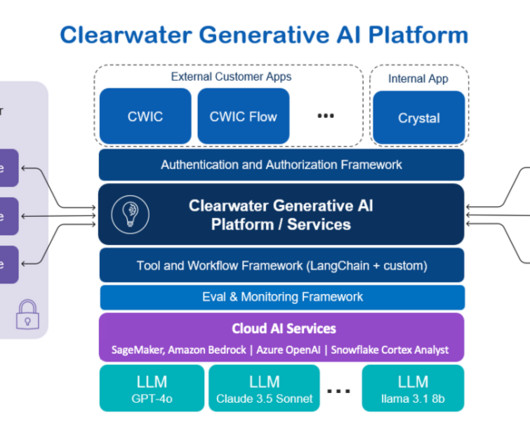
This post was written with Darrel Cherry, Dan Siddall, and Rany ElHousieny of Clearwater Analytics. About Clearwater Analytics Clearwater Analytics (NYSE: CWAN) stands at the forefront of investment management technology. This approach enhances cost-effectiveness and performance to promote high-quality interactions.
Summary: This blog provides a comprehensive roadmap for aspiring Azure DataScientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. This roadmap aims to guide aspiring Azure DataScientists through the essential steps to build a successful career.
Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method. Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. What is Microsoft Fabric?
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. In this post, you will learn how Marubeni is optimizing market decisions by using the broad set of AWS analytics and ML services, to build a robust and cost-effective Power Bid Optimization solution.
Summary: Demystify time complexity, the secret weapon for DataScientists. Explore practical examples, tools, and future trends to conquer big data challenges. Introduction to Time Complexity for DataScientists Time complexity refers to how the execution time of an algorithm scales in relation to the size of the input data.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
Hopefully, at the top, because it’s the very foundation of self-service analytics. We’re all trying to use more data to make decisions, but constantly face roadblocks and trust issues related to data governance. . Data modeling. Data migration . Data architecture. Metadata management. Regulatory compliance.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly. A datascientist team orders a new JuMa workspace in BMW’s Catalog.
There has been a paradigm change in the mindshare of education customers who are now willing to explore new technologies and analytics. However, higher education institutions often lack ML professionals and datascientists. Your models may take more or less time, depending on factors such as input data size and complexity.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, data analysis, data cleaning, and data visualization. It facilitates exploratory Data Analysis and provides quick insights.
Hopefully, at the top, because it’s the very foundation of self-service analytics. We’re all trying to use more data to make decisions, but constantly face roadblocks and trust issues related to data governance. . Data modeling. Data migration . Data architecture. Metadata management. Regulatory compliance.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. With this new feature, you can use your own identity provider (IdP) such as Okta , Azure AD , or Ping Federate to connect to Snowflake via Data Wrangler.
Recently I sat down with the study authors and datascientists at Alation, Andrea Levy and Naveen Kalyanasamy. Talo Thomson, Content Marketing Manager, Alation: You two are datascientists. Why will other data people be interested in these case studies? Get the latest data cataloging news and trends in your inbox.
For instance, telcos are early adopters of location intelligence – spatial analytics has been helping telecommunications firms by adding rich location-based context to their existing data sets for years. Despite that fact, valuable data often remains locked up in various silos across the organization.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
IBM® SPSS Statistics is a leading comprehensive statistical software that provides predictive models and advanced statistical techniques to derive actionable insights from data. For many businesses, research institutions, datascientists, data analyst experts and statisticians, SPSS Statistics is the standard for statistical analysis.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring. AI life-cycle tools are essential to productize AI/ML solutions. “AWS
Data preprocessing ensures the removal of incorrect, incomplete, and inaccurate data from datasets, leading to the creation of accurate and useful datasets for analysis ( Image Credit ) Data completeness One of the primary requirements for data preprocessing is ensuring that the dataset is complete, with minimal missing values.
Solution overview Amazon SageMaker is a fully managed service that helps developers and datascientists build, train, and deploy machine learning (ML) models. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and data governance processes.
Paxata was a Silver Sponsor at the recent Gartner Data and Analytics Summit in Grapevine Texas. Although some product solutions disrupted the operational reporting market, they require users to know the questions they need to ask their data. 2) Line of business is taking a more active role in data projects.
By Carolyn Saplicki , IBM DataScientist Industries are constantly seeking innovative solutions to maximize efficiency, minimize downtime, and reduce costs. All datascientists could leverage our patterns during an engagement. Industries that use air compressors include manufacturing, automotive, construction, and energy.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
Some of the ways in which ML can be used in process automation include the following: Predictive analytics: ML algorithms can be used to predict future outcomes based on historical data, enabling organizations to make better decisions. RPA and ML are two different technologies that serve different purposes.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together datascientists to tackle one of the most dynamic aspects of racing — pit stop strategies. This competition emphasized leveraging analytics in one of the world’s fastest and most data-intensive sports.
At IBM, we believe it is time to place the power of AI in the hands of all kinds of “AI builders” — from datascientists to developers to everyday users who have never written a single line of code. A data store built on open lakehouse architecture, it runs both on premises and across multi-cloud environments.
This allows SageMaker Studio users to perform petabyte-scale interactive datapreparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure.
Business organisations worldwide depend on massive volumes of data that require DataScientists and analysts to interpret to make efficient decisions. Understanding the appropriate ways to use data remains critical to success in finance, education and commerce. What is Data Mining and how is it related to Data Science ?
The solution: IBM databases on AWS To solve for these challenges, IBM’s portfolio of SaaS database solutions on Amazon Web Services (AWS), enables enterprises to scale applications, analytics and AI across the hybrid cloud landscape. It enables secure data sharing for analytics and AI across your ecosystem.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content