This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler. You can download the dataset loans-part-1.csv
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
In the following sections, we demonstrate how to import and prepare the data, optionally export the data, create a model, and run inference, all in SageMaker Canvas. Download the dataset from Kaggle and upload it to an Amazon Simple Storage Service (Amazon S3) bucket.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, data lakes, and analytics tools to load, transform, clean, and aggregate data.
Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics. But today, dashboards and visualizations have become table stakes.
In such situations, it may be desirable to have the data accessible to SageMaker in the ephemeral storage media attached to the ephemeral training instances without the intermediate storage of data in Amazon S3. We add this data to Snowflake as a new table. Launch a SageMaker Training job for training the ML model.
This is where location intelligence (LI) shines – answering those key questions and unlocking insights that inform smarter data-driven decision-making. Download Trending Now: Location Intelligence Drivers Spatial analytics tools aren’t new to the marketplace – in fact, some have been around for decades. Democratization of tools.
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import. This can take a few minutes.
For instance, telcos are early adopters of location intelligence – spatial analytics has been helping telecommunications firms by adding rich location-based context to their existing data sets for years. Despite that fact, valuable data often remains locked up in various silos across the organization.
introduces a wide range of capabilities designed to improve every stage of data analysis—from datapreparation to dashboard consumption. Tableau workbook performance can have a huge effect on the analytics experience for individuals, plus there are implications for your organization at the technology level. Tableau 2022.1
introduces a wide range of capabilities designed to improve every stage of data analysis—from datapreparation to dashboard consumption. Tableau workbook performance can have a huge effect on the analytics experience for individuals, plus there are implications for your organization at the technology level. Tableau 2022.1
Alteryx and the Snowflake Data Cloud offer a potential solution to this issue and can speed up your path to Analytics. In this blog post, we will explore how Alteryx and Snowflake can accelerate your journey to Analytics by sharing use cases and best practices. What is Alteryx? What is Snowflake?
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You’re redirected to the Prepare page, where you can add transformations and analyses to the data. You can either download the report or view it online.
We walk you through the following steps to set up our spam detector model: Download the sample dataset from the GitHub repo. Load the data in an Amazon SageMaker Studio notebook. Prepare the data for the model. Download the dataset Download the email_dataset.csv from GitHub and upload the file to the S3 bucket.
SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data. In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing.
SageMaker Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. Amazon SageMaker Canvas is a powerful no-code ML tool designed for business and data teams to generate accurate predictions without writing code or having extensive ML experience.
This method leverages data from various sensors and advanced analytics to monitor the condition of equipment in real-time. We will start by setting up libraries and datapreparation. To download our dataset and set up our environment, we will install the following packages. temperature, pressure, vibration, etc.)
Download the Machine Learning Project Checklist. Download Now. Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Exploring and Transforming Data. Good data curation and datapreparation leads to more practical, accurate model outcomes.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
SageMaker Studio allows data scientists, ML engineers, and data engineers to preparedata, build, train, and deploy ML models on one web interface. Our training script uses this location to download and prepare the training data, and then train the model. split('/',1) s3 = boto3.client("s3")
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
It provides a single web-based visual interface where you can perform all ML development steps, including preparingdata and building, training, and deploying models. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
Moreover, the library can be downloaded in its entirety from reliable sources such as GitHub at no cost, ensuring its accessibility to a wide range of developers. Its functionalities span from deep learning to text mining, datapreparation, and predictive analytics, ensuring a versatile utility for developers and data scientists alike.
There has been a paradigm change in the mindshare of education customers who are now willing to explore new technologies and analytics. Amazon SageMaker Canvas is a low-code/no-code ML service that enables business analysts to perform datapreparation and transformation, build ML models, and deploy these models into a governed workflow.
Consequently, the tools we employ to process and visualize this data play a critical role. KNIME Analytics Platform is an open-source dataanalytics tool that enables users to manage, process, and analyze data. In this blog, we will focus on integrating Power BI within KNIME for enhanced dataanalytics.
The integration of these multimodal capabilities has unlocked new possibilities for businesses and individuals, revolutionizing fields such as content creation, visual analytics, and software development. These models are released under different licenses designated by their respective sources. You can access the Meta Llama 3.2
AWS HealthOmics and sequence stores AWS HealthOmics is a purpose-built service that helps healthcare and life science organizations and their software partners store, query, and analyze genomic, transcriptomic, and other omics data and then generate insights from that data to improve health and drive deeper biological understanding.
Hugging Face Hub – If your SageMaker Studio domain has access to download models from the Hugging Face Hub , you can use the AutoModelForCausalLM class from huggingface/transformers to automatically download models and pin them to your local GPUs. The model weights will be stored in your local machine’s cache. resource('s3').
This brief definition makes several points about data catalogs—data management, searching, data inventory, and data evaluation—but all depend on the central capability to provide a collection of metadata. Data catalogs have become the standard for metadata management in the age of big data and self-service analytics.
Although the Amazon Kendra console comes equipped with an analytics dashboard, many of our customers prefer to build a custom dashboard. Dockerfile requirements.txt Create an Amazon Elastic Container Registry (Amazon ECR) repository in us-east-1 and push the container image created by the downloaded Dockerfile. Choose Select.
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions.
Jump Right To The Downloads Section Understanding Anomaly Detection: Concepts, Types, and Algorithms What Is Anomaly Detection? Anomaly detection ( Figure 2 ) is a critical technique in data analysis used to identify data points, events, or observations that deviate significantly from the norm.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
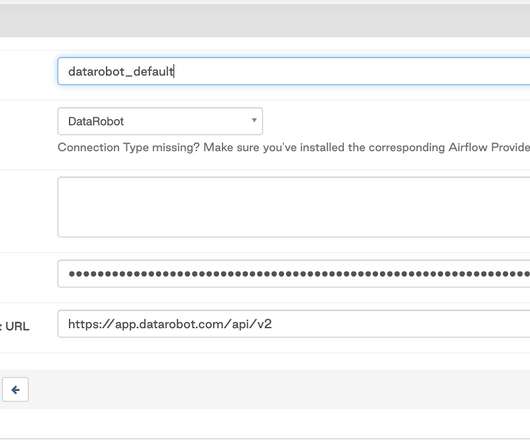
To make it available, download the DAG file from the repository to the dags/ directory in your project (browse GitHub tags to download to the same source code version as your installed DataRobot provider) and refresh the page. Multipersona Data Science and Machine Learning (DSML) Platforms. Download now. References. *
Why will other data people be interested in these case studies? Andrea Levy, Technical Lead, Data Science & Analytics, Alation: First of all: impact! The query reuse case study , especially demonstrates the value of collaboration and centralization of analytics teams. Subscribe to Alation's Blog.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. He develops and codes cloud native solutions with a focus on big data, analytics, and data engineering.
However, if there’s one thing we’ve learned from years of successful cloud data implementations here at phData, it’s the importance of: Defining and implementing processes Building automation, and Performing configuration …even before you create the first user account. Download a free PDF by filling out the form.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML.
Carrier is making more precise energy analytics and insights accessible to customers so they reduce energy consumption and cut carbon emissions. Clariant is empowering its team members with an internal generative AI chatbot to accelerate R&D processes, support sales teams with meeting preparation, and automate customer emails.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. A self-service infrastructure portal for infrastructure and governance.
This minimizes the complexity and overhead associated with moving data between cloud environments, enabling organizations to access and utilize their disparate data assets for ML projects. You can use SageMaker Canvas to build the initial datapreparation routine and generate accurate predictions without writing code.
After you download the code base, you can deploy the project following the instructions outlined in the GitHub repo. Dataset preparation consists of the following key steps: Data acquisition – We begin by downloading a collection of games in PGN format from publicly available PGN files on the PGN mentor program website.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content