This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
generally available on May 24, Alation introduces the Open DataQuality Initiative for the modern data stack, giving customers the freedom to choose the dataquality vendor that’s best for them with the added confidence that those tools will integrate seamlessly with Alation’s Data Catalog and Data Governance application.
Several weeks ago (prior to the Omicron wave), I got to attend my first conference in roughly two years: Dataversity’s DataQuality and Information Quality Conference. Ryan Doupe, Chief Data Officer of American Fidelity, held a thought-provoking session that resonated with me. Step 2: Data Definitions.
Each source system had their own proprietary rules and standards around data capture and maintenance, so when trying to bring different versions of similar data together such as customer, address, product, or financial data, for example there was no clear way to reconcile these discrepancies.
Together, these factors determine the reliability of the organization’s data. Dataquality uses those criteria to measure the level of data integrity and, in turn, its reliability and applicability for its intended use. Reduced dataquality can result in productivity losses, revenue decline and reputational damage.
Key Takeaways: • Implement effective dataquality management (DQM) to support the data accuracy, trustworthiness, and reliability you need for stronger analytics and decision-making. Embrace automation to streamline dataquality processes like profiling and standardization.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for DataProfiling in ETL becomes important for ensuring higher dataquality as per business requirements. What is DataProfiling in ETL?
For any data user in an enterprise today, dataprofiling is a key tool for resolving dataquality issues and building new data solutions. In this blog, we’ll cover the definition of dataprofiling, top use cases, and share important techniques and best practices for dataprofiling today.
These SQL assets can be used in downstream operations like dataprofiling, analysis, or even exporting to other systems for further processing. Updated asset view based on the UpdatedQuery Step 11: Profile the Microsegment Run profiling on the newly created microsegment.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
Example: For a project to optimize supply chain operations, the scope might include creating dashboards for inventory tracking but exclude advanced predictive analytics in the first phase. Key questions to ask: What data sources are required? Are there any data gaps that need to be filled? What are the dataquality expectations?
How to Scale Your DataQuality Operations with AI and ML: In the fast-paced digital landscape of today, data has become the cornerstone of success for organizations across the globe. Every day, companies generate and collect vast amounts of data, ranging from customer information to market trends.
Data entry errors will gradually be reduced by these technologies, and operators will be able to fix the problems as soon as they become aware of them. Make DataProfiling Available. To ensure that the data in the network is accurate, dataprofiling is a typical procedure.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
Data fabric is an architecture and set of data services that provide capabilities to seamlessly integrate and access data from multiple data sources like on-premise and cloud-native platforms. The data can also be processed, managed and stored within the data fabric. Dataquality and governance.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
Databricks Databricks is a cloud-native platform for big data processing, machine learning, and analytics built using the Data Lakehouse architecture. Your data team can manage large-scale, structured, and unstructured data with high performance and durability.
Forward-thinking businesses invest in digital transformation, cloud adoption, advanced analytics and predictive modeling, and supply chain resiliency. 2023 Data Integrity Trends & Insights Results from a Survey of Data and Analytics Professionals Read the report Here are some of the top takeaways that stood out to panelists.
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
In the next section, let’s take a deeper look into how these key attributes help data scientists and analysts make faster, more informed decisions, while supporting stewards in their quest to scale governance policies on the Data Cloud easily. Find Trusted Data. Verifying quality is time consuming.
Data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations who seek to empower more and better data-driven decisions and actions throughout their enterprises. These groups want to expand their user base for data discovery, BI, and analytics so that their business […].
Data engineers play a crucial role in managing and processing big data Ensuring dataquality and integrity Dataquality and integrity are essential for accurate data analysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
It provides a unique ability to automate or accelerate user tasks, resulting in benefits like: improved efficiency greater productivity reduced dependence on manual labor Let’s look at AI-enabled dataquality solutions as an example. Problem: “We’re unsure about the quality of our existing data and how to improve it!”
Master Data Management (MDM) and data catalog growth are accelerating because organizations must integrate more systems, comply with privacy regulations, and address dataquality concerns. What Is Master Data Management (MDM)? Early on, analysts used data catalogs to find and understand data more quickly.
How to become a data scientist Data transformation also plays a crucial role in dealing with varying scales of features, enabling algorithms to treat each feature equally during analysis Noise reduction As part of data preprocessing, reducing noise is vital for enhancing dataquality.
The definition we are going with here is Gartner’s and, to them, there is no single vendor that addresses the complete set of needs required to build a data fabric (at least not today). Gartner defines data fabric as a “design concept that serves as an integrated layer (fabric) of data and connecting processes.”.
Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a data lake. Data Consumption : You have reached a point where the data is ready for consumption for AI, BI & other analytics. This ensures that the data is accurate, consistent, and reliable.
Here are some specific reasons why they are important: Data Integration: Organizations can integrate data from various sources using ETL pipelines. This provides data scientists with a unified view of the data and helps them decide how the model should be trained, values for hyperparameters, etc.
In Part 1 and Part 2 of this series, we described how data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations. Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their […].
In Part 1 of this series, we described how data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations. Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their user base for […].
Thankfully, Sigma Computing and Snowflake Data Cloud provide powerful tools for HCLS companies to address these dataanalytics challenges head-on. In this blog, we’ll explore 10 pressing dataanalytics challenges and discuss how Sigma and Snowflake can help.
Finally, they need control and authority to make decisions that improve data governance. But first, they need to understand the top challenges to data governance, unique to their organization. Source: Gartner : Adaptive Data and Analytics Governance to Achieve Digital Business Success. No Data Leadership.
Why keep data at all? Answering these questions can improve operational efficiencies and inform a number of data intelligence use cases, which include data governance, self-service analytics, and more. Data Intelligence: Origin, Evolution, Use Cases. Examples of Data Intelligence use cases include: Data governance.
Data integration: Merges information from CRM platforms and marketing automation systems for a comprehensive view of customer interactions. Creation of reliable datasets: Prepares datasets for analytics use cases, ensuring reliability for thorough analysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































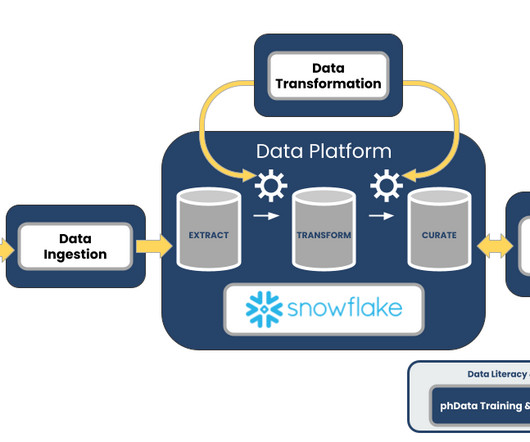









Let's personalize your content