This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. Introduction Machine Learning has revolutionized how we process and analyse data, enabling systems to learn patterns and make predictions.
A visual representation of generative AI – Source: Analytics Vidhya Generative AI is a growing area in machine learning, involving algorithms that create new content on their own. In this blog, we will explore the details of both approaches and navigate through their differences. What is Generative AI?
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. DecisionTrees visualize decision-making processes for better understanding.
It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive. Key applications include fraud detection, customer segmentation, and medical diagnosis.
They play a pivotal role in predictive analytics and machine learning, enabling data scientists to make informed forecasts and decisions based on historical data patterns. By leveraging models, data scientists can extrapolate trends and behaviors, facilitating proactive decision-making.
Skills gap : These strategies rely on data analytics, artificial intelligence tools, and machine learning expertise. Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decisiontrees, neural networks, and supportvectormachines.
With such an overwhelming amount of data, data mining has become an essential process for businesses and organizations to extract valuable insights and make data-driven decisions. In data mining, popular algorithms include decisiontrees, supportvectormachines, and k-means clustering.
We shall look at various machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can install and call their libraries in R studios, including executing the code. Radom Forest install.packages("randomForest")library(randomForest) 4. data = trainData) 5.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
These algorithms are carefully selected based on the specific decision problem and are trained using the prepared data. Machine learning algorithms, such as neural networks or decisiontrees, learn from the data to make predictions or generate recommendations.
Supervised learning is commonly used for risk assessment, image recognition, predictive analytics and fraud detection, and comprises several types of algorithms. Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. temperature, salary).
DecisionTrees These tree-like structures categorize data and predict demand based on a series of sequential decisions. Random Forests By combining predictions from multiple decisiontrees, random forests improve accuracy and reduce overfitting. Ensemble Learning Combine multiple forecasting models (e.g.,
On the other hand, artificial intelligence focuses on creating intelligent systems that can learn, reason, and make decisions. When AI and IoT converge, we witness a synergy where AI empowers IoT devices with advanced analytics, automation, and intelligent decision-making.
Areas making up the data science field include mining, statistics, data analytics, data modeling, machine learning modeling and programming. Ultimately, data science is used in defining new business problems that machine learning techniques and statistical analysis can then help solve. appeared first on IBM Blog.
Machine Learning with Python Machine Learning (ML) empowers systems to learn from data and improve their performance over time without explicit programming. Algorithms in ML identify patterns and make decisions, which is crucial for applications like predictive analytics and recommendation systems.
It constructs multiple decisiontrees and combines their predictions to achieve accurate results in identifying different types of network traffic SupportVectorMachines (SVM) : SVM is used for both classification and anomaly detection.
Markets for each field are booming, offering diverse job roles, especially in Machine Learning for Data Analytics. As we navigate this landscape, the interconnected world of Data Science, Machine Learning, and AI defines the era of 2024, emphasising the importance of these fields in shaping the future.
Techniques like linear regression, time series analysis, and decisiontrees are examples of predictive models. At each node in the tree, the data is split based on the value of an input variable, and the process is repeated recursively until a decision is made.
If you’re looking to start building up your skills in these important Python libraries, especially for those that are used in machine & deep learning, NLP, and analytics, then be sure to check out everything that ODSC East has to offer. And did any of your favorites make it in?
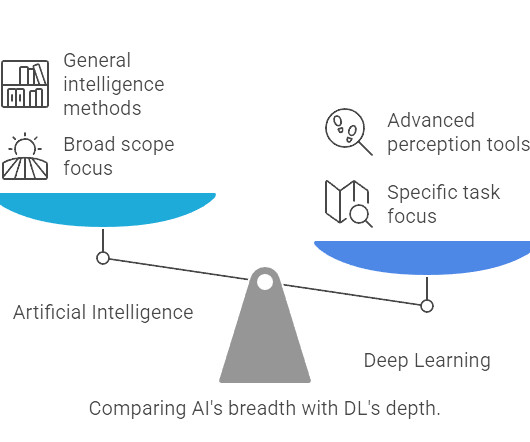
DL Enhances Predictive Analytics: Excels in image and speech recognition tasks. AI is a broad field focused on simulating human intelligence, encompassing techniques like decisiontrees and rule-based systems. Deep Learning Focuses on Neural Networks : Specializes in complex pattern recognition.
Common Applications of Machine Learning Machine Learning has numerous applications across industries. Predictive analytics uses historical data to forecast future trends, such as stock market movements or customer churn. Selecting an Algorithm Choosing the correct Machine Learning algorithm is vital to the success of your model.
It also addresses security, privacy concerns, and real-world applications across various industries, preparing students for careers in data analytics and fostering a deep understanding of Big Data’s impact. Velocity It indicates the speed at which data is generated and processed, necessitating real-time analytics capabilities.
DecisionTrees: A supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks. Random Forest: An ensemble learning method that constructs multiple decisiontrees and merges them to improve accuracy and control overfitting.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, Machine Learning, Natural Language Processing , Statistics and Mathematics. Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow.
What is the difference between data analytics and data science? Data analytics deals with checking the existing hypothesis and information and answering questions for a better and more effective business-related decision-making process. Decisiontrees are more prone to overfitting.
Common algorithms include decisiontrees, neural networks, and supportvectormachines. Enhancing Decision-Making with Data-Driven Insights Machine Learning empowers businesses to make smarter decisions by analysing vast amounts of data and uncovering hidden patterns.
Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming. Techniques such as decisiontrees, supportvectormachines, and neural networks gained popularity.
Healthcare Data Science is revolutionising healthcare through predictive analytics, personalised medicine, and disease detection. Data Science continues to impact various industries, driving innovation and efficiency through data-driven insights and advanced analytics.
Both PyTorch and TensorFlow/Keras are still the go-to machine learning frameworks for a number of tasks, largely thanks to their ability to scale and be used for more resource-intensive tasks like deep learning; these two frameworks arent limited to just basic ML. Kafka remains the go-to for real-time analytics and streaming.
DecisionTrees These trees split data into branches based on feature values, providing clear decision rules. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane.
Scikit-learn provides a consistent API for training and using machine learning models, making it easy to experiment with different algorithms and techniques. Grafana Grafana is a popular analytics and visualization platform that is most commonly used for monitoring and observability in machine learning.
This capability bridges various disciplines, leveraging techniques from statistics, machine learning, and artificial intelligence. Some key areas include: Big Data analytics: It helps in interpreting vast amounts of data to extract meaningful insights.
(Or even better than that) Machine learning has transformed the way businesses operate by automating processes, analyzing data patterns, and improving decision-making. It plays a crucial role in areas like customer segmentation, fraud detection, and predictive analytics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content