This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction YARN stands for Yet Another Resource Negotiator, a large-scale distributed data operating system used for BigData Analytics. The post The Tale of ApacheHadoop YARN! Apart from resource management, […].
This article was published as a part of the Data Science Blogathon. Introduction MapReduce is part of the ApacheHadoop ecosystem, a framework that develops large-scale data processing. Other components of ApacheHadoop include Hadoop Distributed File System (HDFS), Yarn, and Apache Pig.
This article was published as a part of the Data Science Blogathon. Introduction Every day the internet generates billions of bytes of data. Every time you put on a dog filter, watch cat videos or order food from your favourite restaurant, you generate data.
This article was published as a part of the Data Science Blogathon. Introduction ApacheHadoop is an open-source framework designed to facilitate interaction with bigdata. Still, for those unfamiliar with this technology, one question arises, what is bigdata?
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdata pipeline.
This article was published as a part of the Data Science Blogathon. Introduction Impala is an open-source and native analytics database for Hadoop. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. If you want to learn all things Impala, you’ve come to the right place.
With data science and analytics reshaping industries, understanding the distinction between Business Analytics and Data Science is crucial for anyone navigating a career in this field. According to the US Bureau of Labor Statistics, jobs requiring data science skills will grow by 27.9% Masters or Ph.D.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. It discusses performance, use cases, and cost, helping you choose the best framework for your bigdata needs. What is ApacheHadoop?
Data warehouse vs. data lake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a data lake vs. data warehouse. It is often used as a foundation for enterprise data lakes.
As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. The global BigData and Data Engineering Services market, valued at USD 51,761.6 Its ability to handle vast amounts of data makes it a cornerstone in bigdata environments.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of bigdata technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and ApacheHadoop. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
Text Analytics and Natural Language Processing (NLP) Projects: These projects involve analyzing unstructured text data, such as customer reviews, social media posts, emails, and news articles. NLP techniques help extract insights, sentiment analysis, and topic modeling from text data.
Programming for Data Science enables Data Scientists to analyze vast amounts of data and extract meaningful information. There are different programming languages and in this article, we will explore 8 programming languages that play a crucial role in the realm of Data Science.
Data engineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in data engineering that are used to solve different data-related problems.
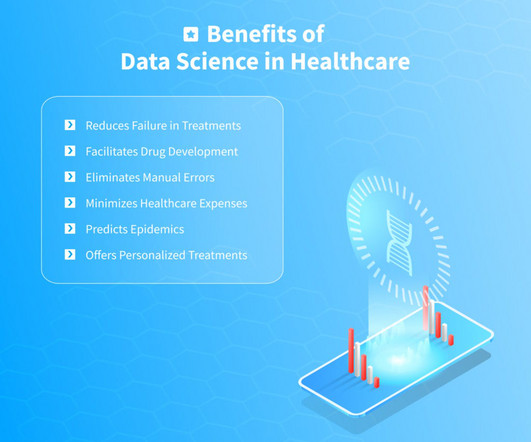
As a discipline that includes various technologies and techniques, data science can contribute to the development of new medications, prevention of diseases, diagnostics, and much more. Utilizing BigData, the Internet of Things, machine learning, artificial intelligence consulting , etc.,
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
Summary: The article explores the differences between data driven and AI driven practices. Data-driven and AI-driven approaches have become key in how businesses address challenges, seize opportunities, and shape their strategic directions. Unify Data Sources Collect data from multiple systems into one cohesive dataset.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content