This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. The post The Tale of ApacheHadoop YARN! Introduction YARN stands for Yet Another Resource Negotiator, a large-scale distributed data operating system used for Big Data Analytics. Apart from resource management, […]. appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction MapReduce is part of the ApacheHadoop ecosystem, a framework that develops large-scale data processing. Other components of ApacheHadoop include Hadoop Distributed File System (HDFS), Yarn, and Apache Pig.
This article was published as a part of the Data Science Blogathon. Introduction ApacheHadoop is an open-source framework designed to facilitate interaction with big data. The post Hadoop Ecosystem appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post An Introduction to Hadoop Ecosystem for Big Data appeared first on Analytics Vidhya. The post An Introduction to Hadoop Ecosystem for Big Data appeared first on Analytics Vidhya. Imagine how much data millions of other people are doing the […].
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive data warehouse software project built on top of ApacheHadoop for providing data query and analysis.
This article was published as a part of the Data Science Blogathon. Introduction ApacheHadoop is the most used open-source framework in the industry to store and process large data efficiently. Hive is built on the top of Hadoop for providing data storage, query and processing capabilities.
This article was published as a part of the Data Science Blogathon. Introduction This article will discuss the Hadoop Distributed File System, its features, components, functions, and benefits. This article also describes the working and real-time applications. Both structured and complex data can […].
This article was published as a part of the Data Science Blogathon. Introduction Hadoop facilitates the processing of large datasets in a distributed manner and provides the foundation on which other services and applications can be built. MapReduce and HDFS are the two main components of Hadoop.
This article was published as a part of the Data Science Blogathon. Previous versions of Hadoop only support […]. The post Architecture and Components of Apache YARN appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Impala is an open-source and native analytics database for Hadoop. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. If you want to learn all things Impala, you’ve come to the right place.
This article was published as a part of the Data Science Blogathon. The post A Beginners’ Guide to ApacheHadoop’s HDFS appeared first on Analytics Vidhya. Introduction With a huge increment in data velocity, value, and veracity, the volume of data is growing exponentially with time.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is ApacheHadoop?
This article explains what PySpark is, some common PySpark functions, and data analysis of the New York City Taxi & Limousine Commission Dataset using PySpark. PySpark is an interface for Apache Spark in Python. It leverages ApacheHadoop for both storage and processing. What is PySpark?
This article helps you choose the right path by exploring their differences, roles, and future opportunities. Big data platforms such as ApacheHadoop and Spark help handle massive datasets efficiently. They must also stay updated on tools such as TensorFlow, Hadoop, and cloud-based platforms like AWS or Azure.
Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. In this article, we’ll focus on a data lake vs. data warehouse. ApacheHadoop, for example, was initially created as a mechanism for distributed storage of large amounts of information. Other platforms defy simple categorization, however.
Refer to Unlocking the Power of Big Data Article to understand the use case of these data collected from various sources. Data Ingestion: Data is collected and funneled into the pipeline using batch or real-time methods, leveraging tools like Apache Kafka, AWS Kinesis, or custom ETL scripts.
Summary: The article explores the differences between data driven and AI driven practices. To confirm seamless integration, you can use tools like ApacheHadoop, Microsoft Power BI, or Snowflake to process structured data and Elasticsearch or AWS for unstructured data.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Among these tools, ApacheHadoop, Apache Spark, and Apache Kafka stand out for their unique capabilities and widespread usage.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. ETL Tools: Apache NiFi, Talend, etc.
There are different programming languages and in this article, we will explore 8 programming languages that play a crucial role in the realm of Data Science. With its powerful ecosystem and libraries like ApacheHadoop and Apache Spark, Java provides the tools necessary for distributed computing and parallel processing.
This article discusses five commonly used architectural design patterns in data engineering and their use cases. One popular example of the MapReduce pattern is ApacheHadoop, an open-source software framework used for distributed storage and processing of big data.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and ApacheHadoop. Now let’s get into the main topic of the article.
This article will discuss managing unstructured data for AI and ML projects. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. ApacheHadoopApacheHadoop is an open-source framework that supports the distributed processing of large datasets across clusters of computers.
This article endeavors to alleviate those confusions. It can include technologies that range from Oracle, Teradata and ApacheHadoop to Snowflake on Azure, RedShift on AWS or MS SQL in the on-premises data center, to name just a few. While this is encouraging, it is also creating confusion in the market.
Text Analytics and Natural Language Processing (NLP) Projects: These projects involve analyzing unstructured text data, such as customer reviews, social media posts, emails, and news articles. NLP techniques help extract insights, sentiment analysis, and topic modeling from text data.
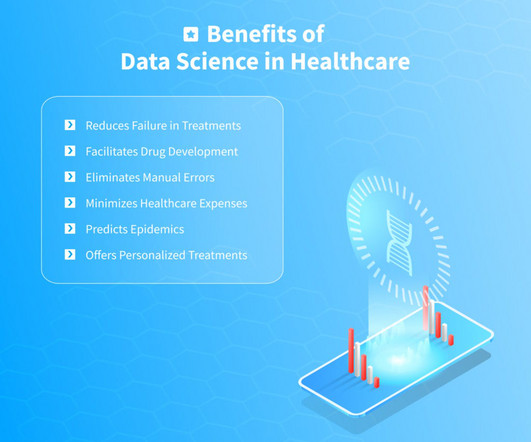
In this article, we will examine various applications and use cases of data science in healthcare as well as investigate its benefits. The diverse technologies and techniques that we covered in this article can improve patient satisfaction, drive medical research, and make positive systematic change.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content