This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From artificialintelligence and machine learning to blockchains and data analytics, big data is everywhere. With big data careers in high demand, the required skillsets will include: ApacheHadoop. Software businesses are using Hadoop clusters on a more regular basis now. Big Data Skillsets. NoSQL and SQL.
In der Parallelwelt der ITler wurde das Tool und Ökosystem ApacheHadoop quasi mit Big Data beinahe synonym gesetzt. ArtificialIntelligence (AI) ersetzt. Big Data tauchte als Buzzword meiner Recherche nach erstmals um das Jahr 2011 relevant in den Medien auf. Big Data wurde zum Business-Sprech der darauffolgenden Jahre.
ArtificialIntelligence is reshaping industries around the world, revolutionizing how businesses operate and deliver services. Latest Advancements in AI Affecting Engineering ArtificialIntelligence continues to advance at a rapid pace, bringing transformative changes to the field of engineering.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is ApacheHadoop?
Besides, there is a balance between the precision of traditional data analysis and the innovative potential of explainable artificialintelligence. Machine learning allows an explainable artificialintelligence system to learn and change to achieve improved performance in highly dynamic and complex settings.
Apache Spark: Apache Spark is an open-source data processing framework for processing large datasets in a distributed manner. It leverages ApacheHadoop for both storage and processing. It does in-memory computations to analyze data in real-time. select: Projects a… Read the full blog for free on Medium.
DFS is widely applied in pathfinding, puzzle-solving, cycle detection, and network analysis, making it a versatile tool in ArtificialIntelligence and computer science. Depth First Search (DFS) is a fundamental algorithm use in ArtificialIntelligence and computer science for traversing or searching tree and graph data structures.
Big data platforms such as ApacheHadoop and Spark help handle massive datasets efficiently. Common Job Titles in Data Science Data Science delves into predictive modeling, artificialintelligence, and machine learning. Key roles include Data Scientist, Machine Learning Engineer, and Data Engineer.
Artificialintelligence (AI) is revolutionizing industries by enabling advanced analytics, automation and personalized experiences. Leveraging distributed storage and processing frameworks such as ApacheHadoop, Spark or Dask accelerates data ingestion, transformation and analysis.
This section will highlight key tools such as ApacheHadoop, Spark, and various NoSQL databases that facilitate efficient Big Data management. ApacheHadoopHadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability. Data lakes and cloud storage provide scalable solutions for large datasets.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. ETL Tools: Apache NiFi, Talend, etc.
This layer includes tools and frameworks for data processing, such as ApacheHadoop, Apache Spark, and data integration tools. Platform as a Service (PaaS) PaaS offerings provide a development environment for building, testing, and deploying Big Data applications.
One way to solve Data Science’s challenges in Data Cleaning and pre-processing is to enable ArtificialIntelligence technologies like Augmented Analytics and Auto-feature Engineering. Some of the tools used by Data Science in 2023 include statistical analysis system (SAS), Apache, Hadoop, and Tableau.
Furthermore, data warehouse storage cannot support workloads like ArtificialIntelligence (AI) or Machine Learning (ML), which require huge amounts of data for model training. By the time the data is ready for analysis, the insights it can yield will be stale relative to the current state of transactional systems.
Packages like dplyr, data.table, and sparklyr enable efficient data processing on big data platforms such as ApacheHadoop and Apache Spark. mlr: This package is nothing short of outstanding for performing artificialintelligence tasks. It literally has all of the technologies required for machine learning jobs.
Apache Nutch A powerful web crawler built on ApacheHadoop, suitable for large-scale data crawling projects. Nutch is often used in conjunction with other Hadoop tools for big data processing. Scrapy is known for its speed and efficiency, making it a popular choice among developers.
Explore Machine Learning with Python: Become familiar with prominent Python artificialintelligence libraries such as sci-kit-learn and TensorFlow. Big Data Technologies: As the amount of data grows, familiarity with big data technologies such as ApacheHadoop, Apache Spark, and distributed computer platforms might be useful.
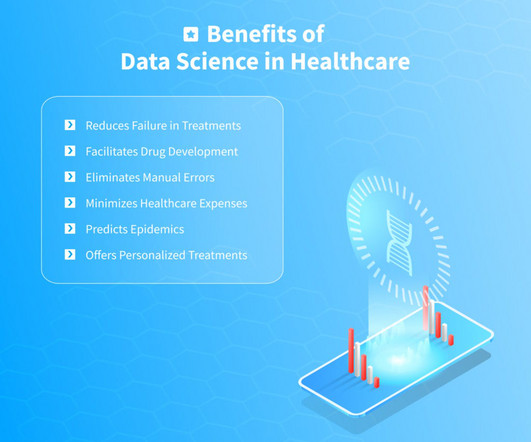
Utilizing Big Data, the Internet of Things, machine learning, artificialintelligence consulting , etc., As a discipline that includes various technologies and techniques, data science can contribute to the development of new medications, prevention of diseases, diagnostics, and much more.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content