This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It can process any type of data, regardless of its variety or magnitude, and save it in its original format. Hadoop systems and data lakes are frequently mentioned together. However, instead of using Hadoop, data lakes are increasingly being constructed using cloud object storage services.
Businesses need software developers that can help ensure data is collected and efficiently stored. They’re looking to hire experienced data analysts, datascientists and data engineers. With big data careers in high demand, the required skillsets will include: ApacheHadoop. NoSQL and SQL.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Machine learning algorithms play a central role in building predictive models and enabling systems to learn from data. Big data platforms such as ApacheHadoop and Spark help handle massive datasets efficiently. Together, these tools enable DataScientists to tackle a broad spectrum of challenges.
Data Science is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A DataScientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
These regulations have a monumental impact on data processing and handling , consumer profiling and data security. Datascientists and analysts who understand the ramifications can help organizations navigate the guidelines, and are skilled in both data privacy and security are in high demand.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. They can be changed, but not easily.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
Answering one of the most common questions I get asked as a Senior DataScientist — What skills and educational background are necessary to become a datascientist? Photo by Eunice Lituañas on Unsplash To become a datascientist, a combination of technical skills and educational background is typically required.
Data Science helps businesses uncover valuable insights and make informed decisions. Programming for Data Science enables DataScientists to analyze vast amounts of data and extract meaningful information. 8 Most Used Programming Languages for Data Science 1.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Their work ensures that data flows seamlessly through the organisation, making it easier for DataScientists and Analysts to access and analyse information.
It involves the design, development, and maintenance of systems, tools, and processes that enable the acquisition, storage, processing, and analysis of large volumes of data. Data Engineers work to build and maintain data pipelines, databases, and data warehouses that can handle the collection, storage, and retrieval of vast amounts of data.
R’s visualization capabilities help in understanding data patterns, identifying outliers, and communicating insights effectively. · Machine Learning: R provides numerous packages for machine learning tasks, making it a popular choice for datascientists. It is a DataScientist’s best friend.
Big Data Technologies: As the amount of data grows, familiarity with big data technologies such as ApacheHadoop, Apache Spark, and distributed computer platforms might be useful. It is critical for knowing how to work with huge data sets efficiently. What is the minimum age for a DataScientist?
With Amazon EMR, which provides fully managed environments like ApacheHadoop and Spark, we were able to process data faster. The data preprocessing batches were created by writing a shell script to run Amazon EMR through AWS Command Line Interface (AWS CLI) commands, which we registered to Airflow to run at specific intervals.
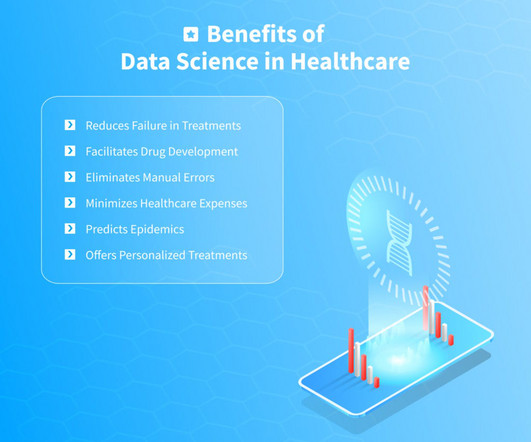
As a discipline that includes various technologies and techniques, data science can contribute to the development of new medications, prevention of diseases, diagnostics, and much more. Utilizing Big Data, the Internet of Things, machine learning, artificial intelligence consulting , etc.,
This is particularly useful in environments where datascientists and engineers need to share large datasets or model outputs. Efficient Data Retrieval AI algorithms often require quick access to data for training and inference.
It involves breaking down the data into smaller chunks that can be processed in parallel across multiple nodes, and then combining the results of those processing tasks to produce a final output. The batch layer of the architecture would handle large amounts of data from various social media platforms like Twitter and Facebook.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and ApacheHadoop. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content