This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hadoop has become synonymous with big data processing, transforming how organizations manage vast quantities of information. As businesses increasingly rely on data for decision-making, Hadoop’s open-source framework has emerged as a key player, offering a powerful solution for handling diverse and complex datasets.
This covers commercial products from data warehouse and business intelligence providers as well as open-source frameworks like ApacheHadoop, Apache Spark, and Apache Presto. As an alternative, data preparation tools that provide self-service access to the information kept in data lakes are gaining popularity.
ApacheHadoop needs no introduction when it comes to the management of large sophisticated storage spaces, but you probably wouldn’t think of it as the first solution to turn to when you want to run an email marketing campaign. Try feeding all of this information into a Hadoop-based predictive analytics routine.
For example, AI-driven agricultural tools can analyze soil conditions and weather patterns to inform better crop management decisions, while AI in construction can lead to smarter building techniques that are environmentally friendly and cost-effective.
How will we manage all this information? For frameworks and languages, there’s SAS, Python, R, ApacheHadoop and many others. What’s more interesting, however, are the trends formed as a result of the newer digitally-reliant solutions. They specifically help shape the industry, altering how business analysts work with data.
Business Analytics involves leveraging data to uncover meaningful insights and support informed decision-making. Big data platforms such as ApacheHadoop and Spark help handle massive datasets efficiently. Both domains are growing rapidly, with increasing demand for skilled professionals across industries.
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. This phase ensures quality and consistency using frameworks like Apache Spark or AWS Glue.
To confirm seamless integration, you can use tools like ApacheHadoop, Microsoft Power BI, or Snowflake to process structured data and Elasticsearch or AWS for unstructured data. Such an organisation that employs these practices would learn to make improved and well-informed decisions to stay competitive.
The rise of Big Data has been fueled by advancements in technology that allow organisations to collect, store, and analyse vast amounts of information from diverse sources. Organisations can harness Big Data Analytics to identify trends, predict outcomes, and make informed decisions that were previously unattainable with smaller datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. As organisations collect vast amounts of information from various sources, ensuring data quality becomes critical.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. As organisations collect vast amounts of information from various sources, ensuring data quality becomes critical.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
For more information about the model, refer to the paper Neural Collaborative Filtering. With Amazon EMR, which provides fully managed environments like ApacheHadoop and Spark, we were able to process data faster. This information allows you to reference previous versions of your models at any time. northeast-2.amazonaws.com/pytorch-inference:1.8.1-gpu-py3'
Web crawling is the automated process of systematically browsing the internet to gather and index information from various web pages. Data Collection : The crawler collects information from each page it visits, including the page title, meta tags, headers, and other relevant data. What is Web Crawling?
The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations. Their work ensures that data flows seamlessly through the organisation, making it easier for Data Scientists and Analysts to access and analyse information.
Introduction to BDaaS In today’s data-driven world, organisations are inundated with vast amounts of information generated from various sources. To harness the potential of Big Data , businesses require robust solutions that can efficiently manage, process, and analyse this information.
Additionally, the ability to handle diverse data types and perform distributed processing enhances efficiency, enabling businesses to derive valuable insights and drive informed decision-making. Software Installation Install the necessary software, including the operating system, Java, and the Hadoop distribution (e.g.,
These data originate from multiple sources that help Data Scientists provide meaningful insights and enable organisations to make informed decisions. This can help companies to access information quickly and faster than usual. The process of data integration from multiple sources requires manual entry of data.
One thing is clear : unstructured data doesn’t mean it lacks information. All forms of data must have some form of information, or else they won’t be considered data. Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information.
Data Science helps businesses uncover valuable insights and make informed decisions. Programming for Data Science enables Data Scientists to analyze vast amounts of data and extract meaningful information. But for it to be functional, programming languages play an integral role. 8 Most Used Programming Languages for Data Science 1.
Hadoop, focusing on their strengths, weaknesses, and use cases. What is ApacheHadoop? ApacheHadoop is an open-source framework for processing and storing massive datasets in a distributed computing environment. Spark uses a more sophisticated mechanism called lineage-based fault tolerance.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. ETL Tools: Apache NiFi, Talend, etc. Big Data Processing: ApacheHadoop, Apache Spark, etc.
Packages like dplyr, data.table, and sparklyr enable efficient data processing on big data platforms such as ApacheHadoop and Apache Spark. Data Visualisation: R is well-known for its complex and adaptable visualisation of information abilities.
It can include technologies that range from Oracle, Teradata and ApacheHadoop to Snowflake on Azure, RedShift on AWS or MS SQL in the on-premises data center, to name just a few. All phases of the data-information lifecycle. The data fabric embraces all phases of the data-information-insight lifecycle.
Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources. Apache NiFi, an open-source data ingestion and distribution platform, has emerged as a powerful tool designed to automate the flow of data between systems.
The data is then transformed to fit a common data model that includes patient demographic information, clinical data, and patient satisfaction scores. One popular example of the MapReduce pattern is ApacheHadoop, an open-source software framework used for distributed storage and processing of big data.
Pricing Management: To improve product price plans, analyze pricing information, rival pricing, and consumer behavior. Programming languages like Python or R should be mastered by students or professionals working on these projects, as should big data tools like ApacheHadoop, Apache Spark, or cloud-based data analytics platforms.
Metadata Management Many DFS architectures include dedicated metadata servers that manage information about file attributes, access controls, and the mapping between logical names and physical locations. This includes features like coherent access, where changes made to files are instantly visible across the network.
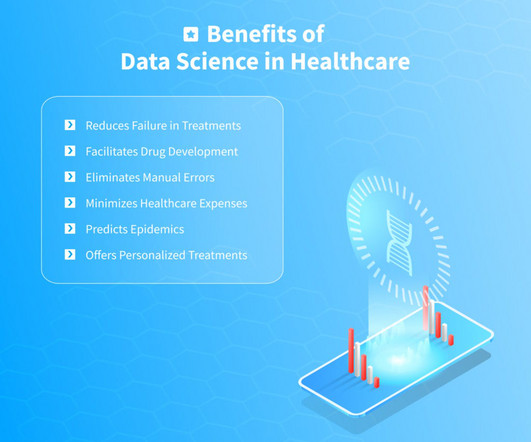
Considering the human body generates two terabytes of data on a daily basis, from brain activity to muscle performance, scientists have a lot of information to collect and process. Data science in healthcare is capable of analyzing vast amounts of information to learn patterns of disease occurrence.
Introduction to Big Data Tools In todays data-driven world, organisations are inundated with vast amounts of information generated from various sources, including social media, IoT devices, transactions, and more. Big Data tools are essential for effectively managing and analysing this wealth of information.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content