This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features. ApacheHadoop: ApacheHadoop is an open-source framework for distributed storage and processing of large datasets. It provides a scalable and fault-tolerant ecosystem for big data processing.
AI engineering is the discipline that combines the principles of data science, software engineering, and machinelearning to build and manage robust AI systems. MachineLearning Algorithms Recent improvements in machinelearning algorithms have significantly enhanced their efficiency and accuracy.
In der Parallelwelt der ITler wurde das Tool und Ökosystem ApacheHadoop quasi mit Big Data beinahe synonym gesetzt. Von Data Science spricht auf Konferenzen heute kaum noch jemand und wurde hype-technisch komplett durch MachineLearning bzw. Neben Supervised Learning kam auch Reinforcement Learning zum Einsatz.
Dashboards, such as those built using Tableau or Power BI , provide real-time visualizations that help track key performance indicators (KPIs). Machinelearning algorithms play a central role in building predictive models and enabling systems to learn from data. Data Scientists require a robust technical foundation.
MachineLearning Experience is a Must. Machinelearning technology and its growing capability is a huge driver of that automation. It’s for good reason too because automation and powerful machinelearning tools can help extract insights that would otherwise be difficult to find even by skilled analysts.
These procedures are central to effective data management and crucial for deploying machinelearning models and making data-driven decisions. After this, the data is analyzed, business logic is applied, and it is processed for further analytical tasks like visualization or machinelearning. What is a Data Pipeline?
Proficient in programming languages like Python or R, data manipulation libraries like Pandas, and machinelearning frameworks like TensorFlow and Scikit-learn, data scientists uncover patterns and trends through statistical analysis and data visualization. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
These frameworks facilitate the efficient processing of Big Data, enabling organisations to derive insights quickly.Some popular frameworks include: ApacheHadoop: An open-source framework that allows for distributed processing of large datasets across clusters of computers. It is known for its high fault tolerance and scalability.
These frameworks facilitate the efficient processing of Big Data, enabling organisations to derive insights quickly.Some popular frameworks include: ApacheHadoop: An open-source framework that allows for distributed processing of large datasets across clusters of computers. It is known for its high fault tolerance and scalability.
It provides a comprehensive suite of tools, libraries, and packages specifically designed for statistical analysis, data manipulation, visualization, and machinelearning. Packages like dplyr, data.table, and sparklyr enable efficient data processing on big data platforms such as ApacheHadoop and Apache Spark.
Accordingly, there are many Python libraries which are open-source including Data Manipulation, Data Visualisation, MachineLearning, Natural Language Processing , Statistics and Mathematics. Learn probability, testing for hypotheses, regression, classification, and grouping, among other topics.
Using machinelearning algorithms, data from these sources can be effectively controlled and further improve the utilisation of the data. To overcome these challenges, organisations must use advanced machinelearning models to enable security platforms. This has resulted in higher ends of work for the Data Scientists.
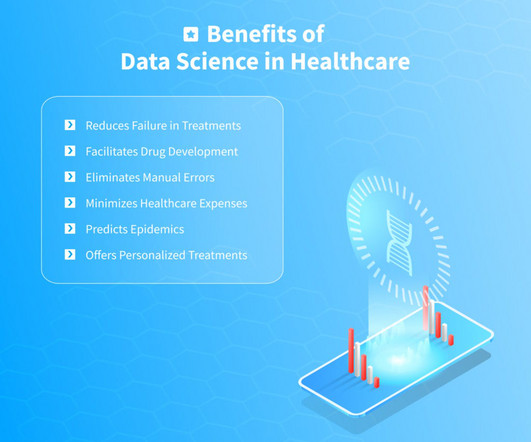
Utilizing Big Data, the Internet of Things, machinelearning, artificial intelligence consulting , etc., The implementation of machinelearning algorithms enables the prediction of drug performance and side effects. allows data scientists to revolutionize the entire sector.
Best Big Data Tools Popular tools such as ApacheHadoop, Apache Spark, Apache Kafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Speed : Spark processes data in-memory, making it up to 100 times faster than Hadoop MapReduce in certain applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content