This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. The post Introduction to ApacheKafka: Fundamentals and Working appeared first on Analytics Vidhya. All these sites use some event streaming tool to monitor user activities. […]. . […].
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Refer to Unlocking the Power of Big Data Article to understand the use case of these data collected from various sources. Data Ingestion: Data is collected and funneled into the pipeline using batch or real-time methods, leveraging tools like ApacheKafka, AWS Kinesis, or custom ETL scripts.
Summary: This article provides a comprehensive guide on Big Data interview questions, covering beginner to advanced topics. This article helps aspiring candidates excel by covering the most frequently asked Big Data interview questions. Familiarise yourself with essential tools like Hadoop and Spark. What is YARN in Hadoop?
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency. He tweets at @markhneedham.
In this article, we’ll take stock of what big data has achieved from a c-suite perspective (with special attention to business transformation and customer experience.). “Setting up Hadoop on-premises was a huge undertaking. Ten years later, there’s no doubt much progress has been made.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Among these tools, ApacheHadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage.
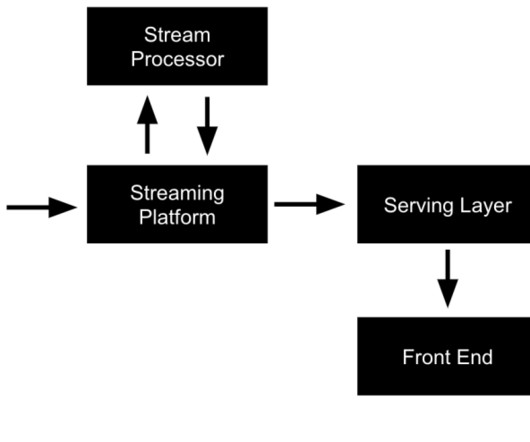
This article discusses five commonly used architectural design patterns in data engineering and their use cases. The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. This data would be stored in a distributed file system such as Hadoop Distributed File System (HDFS).
Some of these solutions include: Distributed computing: Distributed computing systems, such as Hadoop and Spark, can help distribute the processing of data across multiple nodes in a cluster. If you want to learn more about data engineers, check out article called: “ Data is the new gold and the industry demands goldsmiths.”
This article will discuss managing unstructured data for AI and ML projects. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing.
Text Analytics and Natural Language Processing (NLP) Projects: These projects involve analyzing unstructured text data, such as customer reviews, social media posts, emails, and news articles. NLP techniques help extract insights, sentiment analysis, and topic modeling from text data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content