This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the forefront of this event-driven revolution is ApacheKafka, the widely recognized and dominant open-source technology for event streaming. While most enterprises have already recognized how ApacheKafka provides a strong foundation for EDA, they often fall behind in unlocking its true potential.
Artificialintelligence is also key for businesses, helping provide capabilities for both streamlining business processes and improving strategic decisions. Events as fuel for AI Models: Artificialintelligence models rely on big data to refine the effectiveness of their capabilities.
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Overview There are a plethora of data science tools out there – which one should you pick up? Here’s a list of over 20. The post 22 Widely Used Data Science and Machine Learning Tools in 2020 appeared first on Analytics Vidhya.
With AI credits, teams can streamline the annotation process using intelligent suggestions and quality control mechanisms. Confluent Confluent provides a robust data streaming platform built around ApacheKafka. Amazon Web Services(AWS) AWS offers one of the most extensive AI and ML infrastructures in the world.
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificialintelligence. It’s heavily used in many industries such as automotive, aerospace, communication, and manufacturing.
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). He is passionate about enabling customers on their data and artificialintelligence (AI) journey to the cloud.
ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer. Spark offers a versatile range of functionalities, from batch processing to stream processing, making it a comprehensive solution for complex data challenges.
It initially sources input time series data from Amazon Managed Streaming for ApacheKafka (Amazon MSK) using this live stream for model training. The application, once deployed, constructs an ML model using the Random Cut Forest (RCF) algorithm. Post-training, the model continues to process incoming data points from the stream.
Customers can use the CloudFormation template to bring up an application stack that receives time-series data from an Amazon Managed Streaming for ApacheKafka (Amazon MSK) streaming source and performs near-real-time anomaly detection in the streaming data.
Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs. Data at Rest This includes storage solutions such as S3 Data Warehouse and Cassandra. What Technologies Does Netflix Use for Its Big Data Infrastructure?
Enhanced Data Utilisation Effective ingestion unlocks the full potential of data by making it available for advanced analytics, machine learning, and artificialintelligence applications, driving innovation and business growth. ApacheKafka An open-source platform designed for real-time data streaming.
The rise of advanced technologies such as ArtificialIntelligence (AI), Machine Learning (ML) , and Big Data analytics is reshaping industries and creating new opportunities for Data Scientists. ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Here are five key trends to watch.
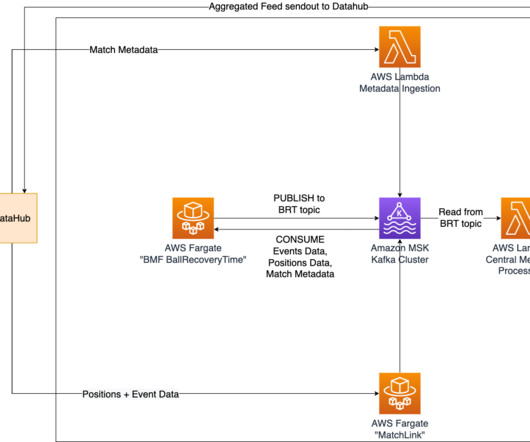
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
Leverage Compound Sparsity to Achieve the Fastest Inference Performance on CPUs: Damian Bogunowicz | Neural Magic and Konstantin Gulin | Machine Learning Engineer | Neural Magic ApacheKafka for Real-Time Machine Learning Without a Data Lake: Kai Waehner | Global Field CTO | Author, International Speaker Time Series Forecasting for Managers — All Forecasts (..)
The session participants will learn the theory behind compound sparsity, state-of-the-art techniques, and how to apply it in practice using the Neural Magic platform.
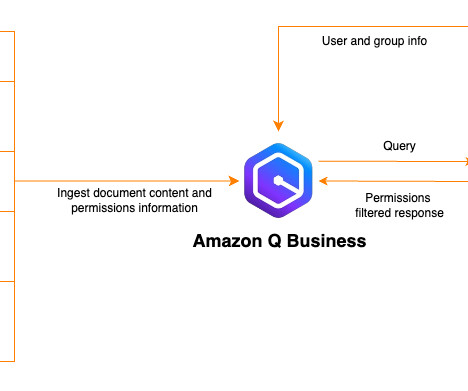
I am currently using ApacheKafka. The #customerwork Slack channel is being used to communicate about an upcoming customer engagement, as shown in the following figure. Post the first question to Amazon Q Business. Can you list high level steps involved in migration to Amazon MSK?
Then the events are ingested into TR’s centralized streaming platform, which is built on top of Amazon Managed Streaming for Kafka (Amazon MSK). Amazon MSK makes it easy to ingest and process streaming data in real time with fully managed ApacheKafka.
In response, Twitter has implemented various solutions, including ApacheKafka, a distributed streaming platform that helps manage the data flow from user interactions. Using Kafka, Twitter can effectively handle high-throughput data streams, enabling users to receive timely notifications and updates.
Efficient Incremental Processing with Apache Iceberg and Netflix Maestro Dimensional Data Modeling in the Modern Era Building Big Data Workflows: NiFi, Hive, Trino, & Zeppelin An Introduction to Data Contracts From Data Mess to Data Mesh — Data Management in the Age of Big Data and Gen AI Introduction to Containers for Data Science / Data Engineering (..)
Data Streaming Learning about real-time data collection methods using tools like ApacheKafka and Amazon Kinesis. Future Trends Exploring emerging trends in Big Data, such as the rise of edge computing, quantum computing, and advancements in artificialintelligence.
Real-time processing allows organisations to make timely decisions based on current data rather than relying on historical information.Technologies enabling real-time analytics include: Stream Processing Frameworks: Tools like ApacheKafka facilitate the continuous ingestion and processing of streaming data.
For every xSaves prediction, it produces a message with the prediction as a payload, which then gets distributed by a central message broker running on Amazon Managed Streaming for ApacheKafka (Amazon MSK). The information also gets stored in a data lake for future auditing and model improvements.
Streaming Machine Learning Without a Data Lake The combination of data streaming and ML enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., Today different stages exist within ML pipelines built to meet technical, industrial, and business requirements. This section delves into the common stages in most ML pipelines, regardless of industry or business function. 1 Data Ingestion (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content