This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
Customers can use the CloudFormation template to bring up an application stack that receives time-series data from an Amazon Managed Streaming for ApacheKafka (Amazon MSK) streaming source and performs near-real-time anomaly detection in the streaming data. How do I delete my Amazon Lookout for Metrics resources? Choose Delete.
Andre Franca | VP of Research and Development | causaLens Popular virtual sessions: AI and Bias: How to Detect It and How to Prevent It: Sandra Wachter, PhD | Professor, Technology and Regulation | Oxford Internet Institute, University of Oxford Probabilistic Machine Learning for Finance and Investing: Deepak Kanungo | Founder and CEO, Advisory Board (..)
Streaming Machine Learning Without a Data Lake The combination of data streaming and ML enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
The session participants will learn the theory behind compound sparsity, state-of-the-art techniques, and how to apply it in practice using the Neural Magic platform.
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. Data Streaming Learning about real-time data collection methods using tools like ApacheKafka and Amazon Kinesis.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Apache Spark: A fast processing engine that supports both batch and real-time analytics, making it suitable for a wide range of applications. Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., Other areas in ML pipelines: transfer learning, anomaly detection, vector similarity search, clustering, etc. Today different stages exist within ML pipelines built to meet technical, industrial, and business requirements. 1 Data Ingestion (e.g.,
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






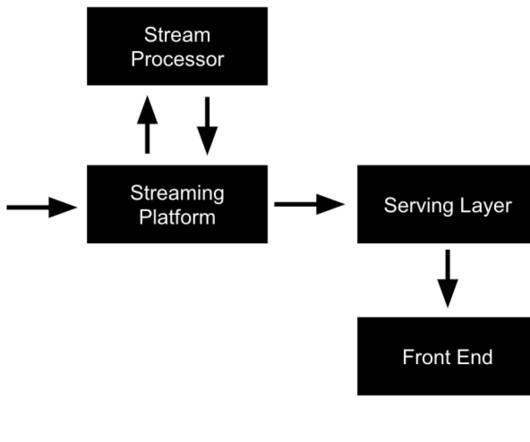

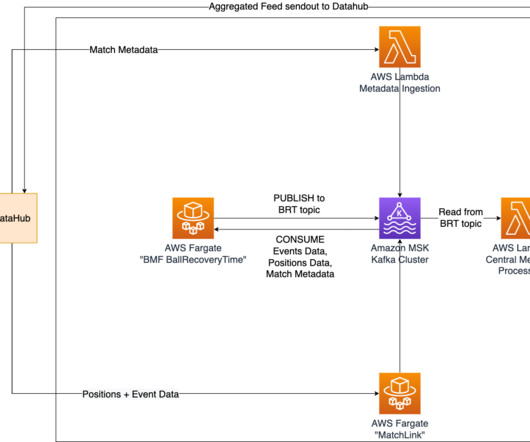









Let's personalize your content