This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Kinesis is a platform to build pipelines for streaming data at the scale of terabytes per hour. The post Amazon Kinesis vs. ApacheKafka For BigData Analysis appeared first on Dataconomy. Parts of the Kinesis platform are.
The generation and accumulation of vast amounts of data have become a defining characteristic of our world. This data, often referred to as BigData , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. databases), semi-structured data (e.g.,
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
With the explosive growth of bigdata over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. The success of any data initiative hinges on the robustness and flexibility of its bigdata pipeline.
Summary: Netflix’s sophisticated BigData infrastructure powers its content recommendation engine, personalization, and data-driven decision-making. As a pioneer in the streaming industry, Netflix utilises advanced data analytics to enhance user experience, optimise operations, and drive strategic decisions.
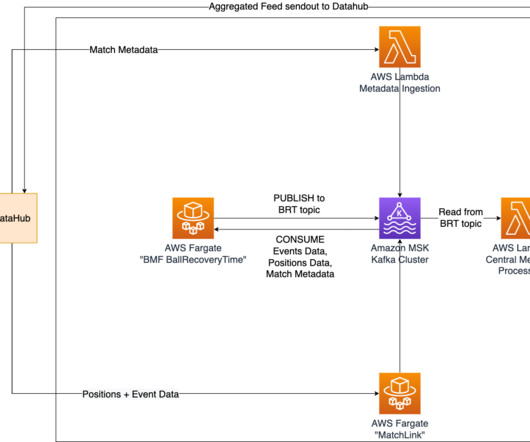
How it’s implemented Positional data from an ongoing match, which is recorded at a sampling rate of 25 Hz, is utilized to determine the time taken to recover the ball. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
Therefore, it’s no surprise that determining the proficiency of goalkeepers in preventing the ball from entering the net is considered one of the most difficult tasks in football data analysis. Bundesliga and AWS have collaborated to perform an in-depth examination to study the quantification of achievements of Bundesliga’s keepers.
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
This explosive growth is driven by the increasing volume of data generated daily, with estimates suggesting that by 2025, there will be around 181 zettabytes of data created globally. The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and BigData technologies.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. million by 2028.
Defining clear objectives and selecting appropriate techniques to extract valuable insights from the data is essential. Here are some project ideas suitable for students interested in bigdata analytics with Python: 1. Implement real-time analytics to monitor trends or anomalies in the data.
Data Lakes Data lakes are centralized repositories designed to store vast amounts of raw, unstructured, and structured data in their native format. They enable flexible data storage and retrieval for diverse use cases, making them highly scalable for bigdata applications.
Listed below are some of the common types of data pipeline tools: Commercial vs open-source data pipeline tools When a business needs full control over the development process and wants to build highly customizable complex solutions, open-source tools come in handy. No built-in data quality functionality. No expert support.
1 Data Ingestion (e.g., ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., As usage increased, the system had to be scaled vertically, approaching AWS instance-type limits. Today different stages exist within ML pipelines built to meet technical, industrial, and business requirements.
Summary: BigData tools empower organizations to analyze vast datasets, leading to improved decision-making and operational efficiency. Ultimately, leveraging BigData analytics provides a competitive advantage and drives innovation across various industries.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. offers Data Science courses covering essential data tools with a job guarantee. It integrates well with various data sources, making analysis easier.
In this post, we dive deep into how CONXAI hosts the state-of-the-art OneFormer segmentation model on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS), KServe, and NVIDIA Triton. Our journey to AWS Initially, CONXAI started with a small cloud provider specializing in offering affordable GPUs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content