This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can safely use an ApacheKafkacluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
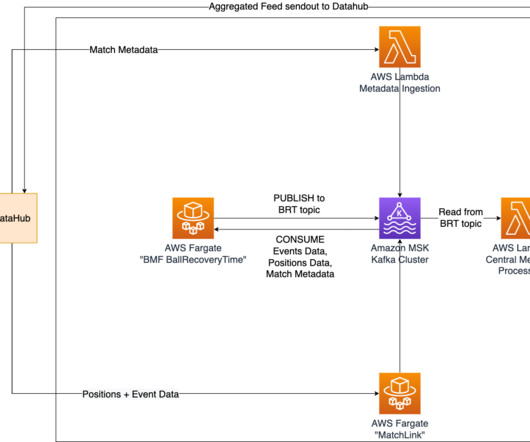
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes. Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS).
The service, which was launched in March 2021, predates several popular AWS offerings that have anomaly detection, such as Amazon OpenSearch , Amazon CloudWatch , AWS Glue Data Quality , Amazon Redshift ML , and Amazon QuickSight. To use this feature, you can write rules or analyzers and then turn on anomaly detection in AWS Glue ETL.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
Among these tools, Apache Hadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage. Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as ApacheKafka. Cloud-agnostic and can run on any Kubernetes cluster. Integration: It can work alongside other workflow orchestration tools (Airflow cluster or AWS SageMaker Pipelines, etc.)
ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. Kafka is highly scalable and ideal for high-throughput and low-latency data pipeline applications. Data Processing Tools These tools are essential for handling large volumes of unstructured data.
Real-time Data Stream Analysis: Use Python with libraries like ApacheKafka and Apache Spark to process and analyze real-time data streams from sources like Twitter, sensors, or website logs. Implement real-time analytics to monitor trends or anomalies in the data.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering. It connects to many DBs.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., As usage increased, the system had to be scaled vertically, approaching AWS instance-type limits. Other areas in ML pipelines: transfer learning, anomaly detection, vector similarity search, clustering, etc. 1 Data Ingestion (e.g.,
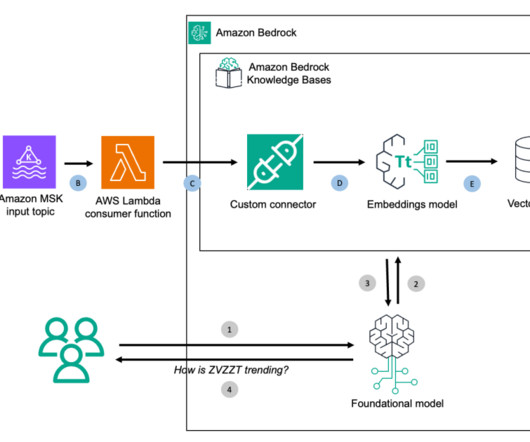
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
In this post, we dive deep into how CONXAI hosts the state-of-the-art OneFormer segmentation model on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS), KServe, and NVIDIA Triton. Our journey to AWS Initially, CONXAI started with a small cloud provider specializing in offering affordable GPUs.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content