This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
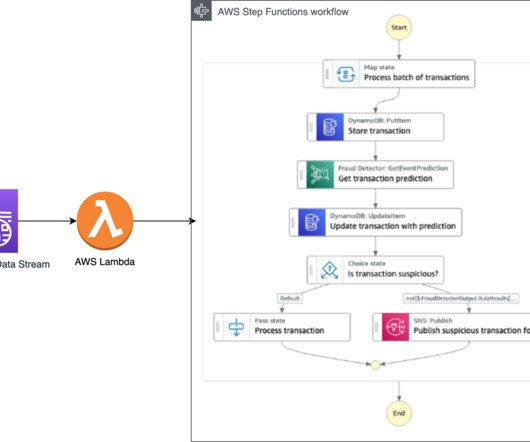
The same architecture applies if you use Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a data streaming service. This approach allows you to react to the potentially fraudulent transactions in real time as you store each transaction in a database and inspect it before processing further.
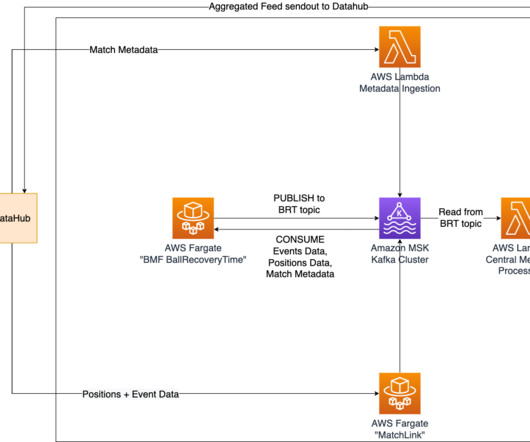
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. A Lambda function retrieves all recovery times from the relevant Kafka topic and stores them in an Amazon Aurora Serverless database.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. It offers an AWS CloudFormation template for straightforward deployment in an AWS account.
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS).
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). We’ve implemented an AWS Lambda function with the specific task of retrieving the calculated shot speed from the relevant Kafka topic.
Components of a Big Data Pipeline Data Sources (Collection): Data originates from various sources, such as databases, APIs, and log files. Examples include transactional databases, social media feeds, and IoT sensors. This phase ensures quality and consistency using frameworks like Apache Spark or AWS Glue.
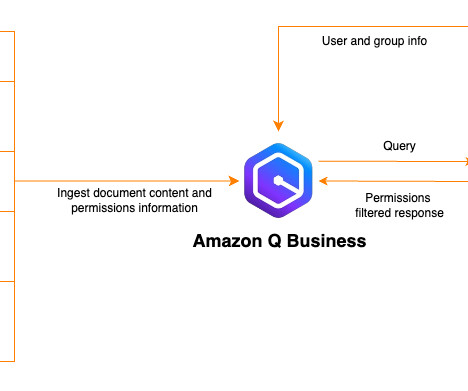
Additionally, you will learn how to configure the Amazon Q Business application and enable user authentication through AWS IAM Identity Center , which is a recommended service for managing a workforce’s access to AWS applications. Permission to access your AWS Secrets Manager secret to authenticate your data source connector instance.
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
From extracting information from databases and spreadsheets to ingesting streaming data from IoT devices and social media platforms, It’s the foundation upon which data-driven initiatives are built. ApacheKafka An open-source platform designed for real-time data streaming. It supports both batch and real-time processing.
It utilises Amazon Web Services (AWS) as its main data lake, processing over 550 billion events daily—equivalent to approximately 1.3 Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs. petabytes of data.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Focus on Python and R for Data Analysis, along with SQL for database management. Understanding real-time data processing frameworks, such as ApacheKafka, will also enhance your ability to handle dynamic analytics.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering. Talend Free to use.
Bundesliga and AWS have collaborated to perform an in-depth examination to study the quantification of achievements of Bundesliga’s keepers. The BMF logic itself (except for the ML model) runs on an AWS Fargate container. This Bundesliga Match Fact was developed among a team of Bundesliga and AWS experts.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The exploration of common machine learning pipeline architecture and patterns starts with a pattern found in not just machine learning systems but also database systems, streaming platforms, web applications, and modern computing infrastructure. 1 Data Ingestion (e.g.,
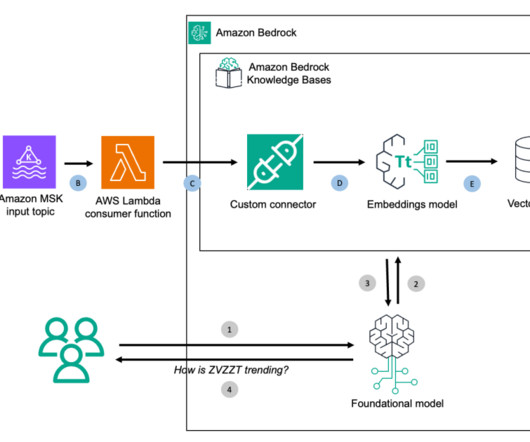
This feature chunks and converts input data into embeddings using your chosen Amazon Bedrock model and stores everything in the backend vector database. Amazon MSK is a streaming data service that manages ApacheKafka infrastructure and operations, making it straightforward to run ApacheKafka applications on Amazon Web Services (AWS).
In this post, we dive deep into how CONXAI hosts the state-of-the-art OneFormer segmentation model on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS), KServe, and NVIDIA Triton. Our journey to AWS Initially, CONXAI started with a small cloud provider specializing in offering affordable GPUs.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. A data engineer creates and manages the pipelines that transfer data from different sources to databases or cloud storage. What Does a Data Engineer Do?
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Statistics : According to AWS reports, EMR reduces the time required for Big Data processing tasks by up to 90% compared to traditional methods.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content