This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
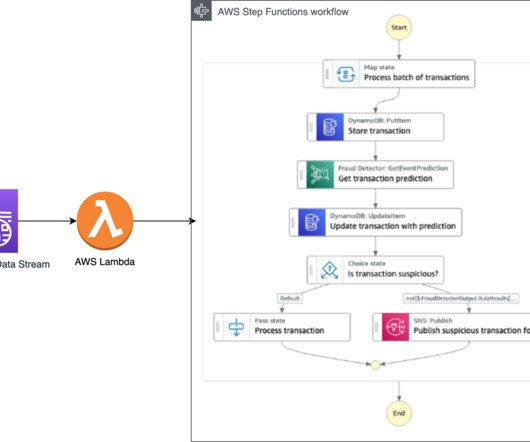
We show how you can apply this approach to various data streaming and event-driven architectures, depending on the desired outcome and actions to take to prevent fraud (such as alert the user about the fraud or flag the transaction for additional review). Example use cases for this could be payment processing or high-volume account creation.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
This process comprises two key components: event data and optical tracking data. Event data collection entails gathering the fundamental building blocks of the game. For the precision needed in shot speed calculations, we must ensure that the ball’s position aligns precisely with the moment of the event.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. It offers an AWS CloudFormation template for straightforward deployment in an AWS account.
TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting. TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations.
Amazon S3: Amazon Simple Storage Service (S3) is a scalable object storage service provided by Amazon Web Services (AWS). Unlike traditional batch processing, where data is processed in fixed intervals, stream processing enables organizations to gain insights and respond to events as they happen in real-time.
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer. Interested in attending an ODSC event? Learn more about our upcoming events here. Each platform offers unique features and benefits, making it vital for data engineers to understand their differences.
It utilises Amazon Web Services (AWS) as its main data lake, processing over 550 billion events daily—equivalent to approximately 1.3 Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs.
Among these tools, Apache Hadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage. Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
Diagnostic Analytics Projects: Diagnostic analytics seeks to determine the reasons behind specific events or patterns observed in the data. 3. Predictive Analytics Projects: Predictive analytics involves using historical data to predict future events or outcomes. Root cause analysis is a typical diagnostic analytics task.
ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. Kafka is highly scalable and ideal for high-throughput and low-latency data pipeline applications. It allows unstructured data to be moved and processed easily between systems.
Flexibility: Airflow was designed with batch workflows in mind; it was not meant for permanently running event-based workflows. Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as ApacheKafka. Miscellaneous Workflows are created as directed acyclic graphs (DAGs).
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Pricing Up to a million events/month on the free plan. Up to 100 million events/month and a 14-day trial for the starter plan. High CPU requirement at data destination for data loading operations.
Bundesliga and AWS have collaborated to perform an in-depth examination to study the quantification of achievements of Bundesliga’s keepers. How Keeper Efficiency is implemented This Bundesliga Match Fact consumes both event and positional data. This frame is used to synchronize the event data with the positional data.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., As usage increased, the system had to be scaled vertically, approaching AWS instance-type limits. These include shared-nothing architecture, event-driven architecture, and directed acyclic graphs (DAGs). 1 Data Ingestion (e.g.,
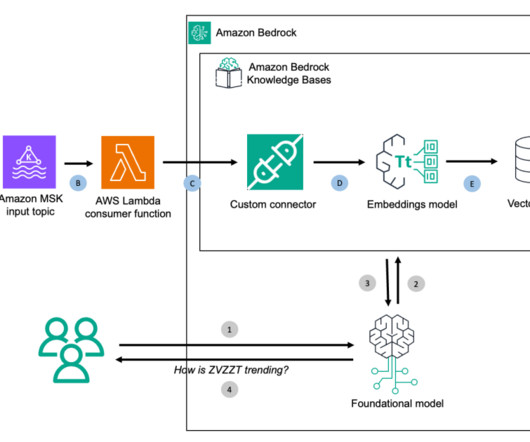
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
In this post, we dive deep into how CONXAI hosts the state-of-the-art OneFormer segmentation model on AWS using Amazon Simple Storage Service (Amazon S3), Amazon Elastic Kubernetes Service (Amazon EKS), KServe, and NVIDIA Triton. Our journey to AWS Initially, CONXAI started with a small cloud provider specializing in offering affordable GPUs.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Statistics : According to AWS reports, EMR reduces the time required for Big Data processing tasks by up to 90% compared to traditional methods.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data. Which cloud-based data engineering tools are most popular?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content