This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Confluent Confluent provides a robust data streaming platform built around ApacheKafka. Microsoft AzureAzure supports AI development through tools like Azure ML Studio, virtual machines, and Azure OpenAI integration.
ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer. Spark offers a versatile range of functionalities, from batch processing to stream processing, making it a comprehensive solution for complex data challenges.
On Wednesday, Henk Boelman, Senior Cloud Advocate at Microsoft, spoke about the current landscape of Microsoft Azure, as well as some interesting use cases and recent developments. Keynotes Our main keynote sessions were held on the virtual side of the conference. You can read the recap here and watch the full keynote here.
ApacheKafka An open-source platform designed for real-time data streaming. Popular options include ApacheKafka for real-time streaming, Apache Spark for batch and stream processing, Talend for ETL, and cloud-based solutions like AWS Glue, Azure Data Factory, and Google Cloud Dataflow.
Among these tools, Apache Hadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage. Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Understanding real-time data processing frameworks, such as ApacheKafka, will also enhance your ability to handle dynamic analytics. AWS or Azure) will be increasingly important as more organisations migrate their operations online.
Cloud Storage: Services like Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage provide scalable storage solutions that can accommodate massive datasets with ease. Key storage solutions include: Data Lakes: Centralised repositories that store raw data in its native format until needed for analysis.
Cloud Storage: Services like Amazon S3, Google Cloud Storage, and Microsoft Azure Blob Storage provide scalable storage solutions that can accommodate massive datasets with ease. Key storage solutions include: Data Lakes: Centralised repositories that store raw data in its native format until needed for analysis.
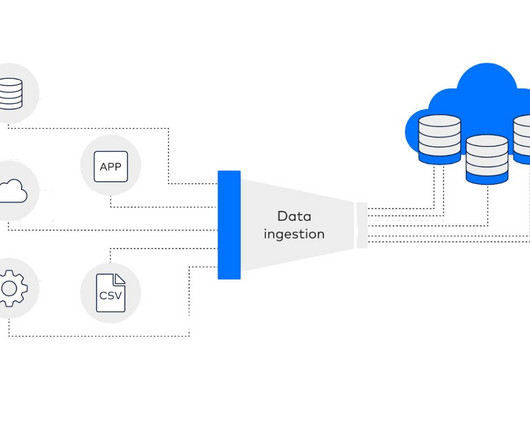
Utilising data streaming platforms such as ApacheKafka, Apache Flink, or Apache Spark Streaming, data is gathered from many sources and processed in real-time or close to real-time. IoT applications, log processing, and other data-intensive scenarios frequently use this kind of ingestion.
There are a number of tools that can help with streaming data collection and processing, some popular ones include: ApacheKafka : An open-source, distributed event streaming platform that can handle millions of events per second. Azure Stream Analytics : A cloud-based service that can be used to process streaming data in real-time.
Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. Data Processing Tools These tools are essential for handling large volumes of unstructured data.
Data Science Dojo is offering Memphis broker for FREE on Azure Marketplace preconfigured with Memphis, a platform that provides a P2P architecture, scalability, storage tiering, fault-tolerance, and security to provide real-time processing for modern applications suitable for large volumes of data.
Technologies like ApacheKafka, often used in modern CDPs, use log-based approaches to stream customer events between systems in real-time. Activity Schema Processing : To capture and process customer activities, you might use a stream processing technology like ApacheKafka or Apache Flink.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Integration with Microsoft Services : Seamlessly integrates with other Azure services like Azure Data Lake Storage.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data. The global Big Data and data engineering market, valued at $75.55
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content